AstroPT: Scaling Large Observation Models for Astronomy
2405.14930
2
0
Abstract
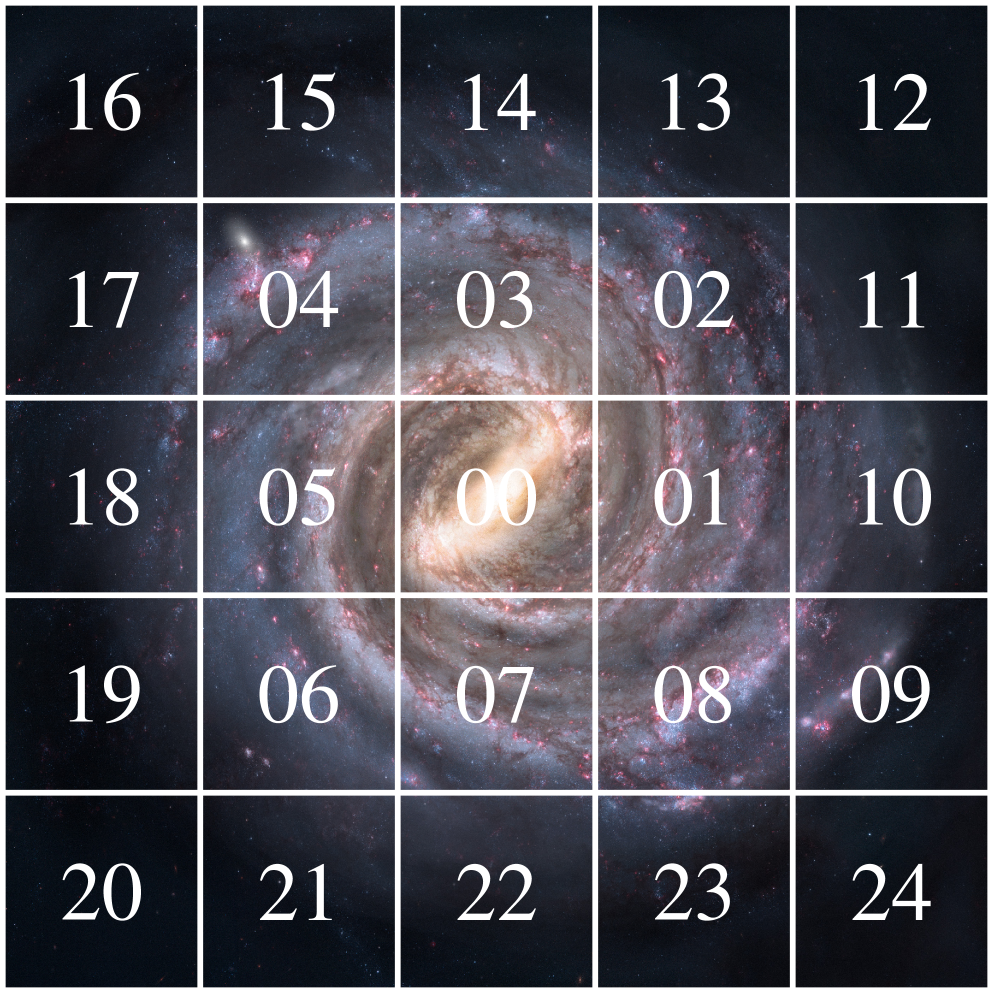
This work presents AstroPT, an autoregressive pretrained transformer developed with astronomical use-cases in mind. The AstroPT models presented here have been pretrained on 8.6 million $512 times 512$ pixel $grz$-band galaxy postage stamp observations from the DESI Legacy Survey DR8. We train a selection of foundation models of increasing size from 1 million to 2.1 billion parameters, and find that AstroPT follows a similar saturating log-log scaling law to textual models. We also find that the models' performances on downstream tasks as measured by linear probing improves with model size up to the model parameter saturation point. We believe that collaborative community development paves the best route towards realising an open source `Large Observation Model' -- a model trained on data taken from the observational sciences at the scale seen in natural language processing. To this end, we release the source code, weights, and dataset for AstroPT under the MIT license, and invite potential collaborators to join us in collectively building and researching these models.
Create account to get full access
Overview
- This paper, titled "AstroPT: Scaling Large Observation Models for Astronomy", explores techniques for scaling large observation models in the field of astronomy.
- The key focus is on using contrastive learning and other methods to improve the performance and scalability of these models.
- The research aims to address the challenges of working with the massive datasets and complex models involved in analyzing astronomical observations.
Plain English Explanation
When astronomers study the universe, they collect massive amounts of data from telescopes and other instruments. This data needs to be analyzed using complex computer models to extract meaningful insights. The paper on scaling large observation models for astronomy tackles the challenge of making these models more powerful and efficient.
The researchers use a technique called contrastive learning to train the models. This involves teaching the model to identify key differences between related observations, which helps it learn more effectively. They also explore other approaches to make the models scale better as the datasets grow larger.
By improving the scalability and performance of these observation models, the research aims to support advances in our understanding of the cosmos. For example, scaling laws for large time series models could lead to better predictions about the behavior of stars and galaxies over time. And pretraining billion-scale geospatial foundational models could unlock new insights from the vast stores of astronomical data.
Technical Explanation
The key technical contributions of this paper include:
-
Contrastive Learning: The researchers propose a contrastive learning approach to train large observation models more effectively. This involves teaching the model to identify the differences between related astronomical observations, which helps it learn the important features more efficiently.
-
Architecture and Training Techniques: The paper explores different model architectures and training strategies to improve the scalability and performance of these large observation models. This includes techniques like auto-regressive denoising operators and pretraining on billion-scale datasets.
-
Evaluation on Astronomy Tasks: The authors test their models on a range of astronomy-specific tasks, such as named entity recognition, to demonstrate their effectiveness in real-world applications.
Critical Analysis
The paper presents a promising approach to scaling large observation models in astronomy, but it also acknowledges several limitations and areas for further research:
- The contrastive learning techniques require carefully designed data augmentation and sampling strategies, which can be complex to implement in practice.
- The performance gains demonstrated may be sensitive to the specific tasks and datasets used in evaluation, so more extensive testing is needed to validate the generalizability of the findings.
- The computational and memory requirements of these large models remain a challenge, and further innovations in model architecture and training may be necessary to make them truly scalable.
Despite these caveats, the core ideas presented in the paper represent an important step forward in addressing the challenges of working with massive astronomical datasets and complex observation models. Continued research in this direction has the potential to unlock new discoveries about the universe.
Conclusion
The "AstroPT: Scaling Large Observation Models for Astronomy" paper proposes innovative techniques to improve the scalability and performance of large-scale observation models used in astronomy. By leveraging contrastive learning and other advanced training methods, the researchers demonstrate the potential to extract more meaningful insights from the vast troves of astronomical data.
While some challenges remain, this work represents a significant advancement in the field and could pave the way for breakthroughs in our understanding of the cosmos. As astronomical observations and models continue to grow in complexity, solutions like those presented in this paper will become increasingly crucial to driving progress in this important scientific domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

The Scaling Law in Stellar Light Curves
Jia-Shu Pan, Yuan-Sen Ting, Yang Huang, Jie Yu, Ji-Feng Liu
0
0
Analyzing time series of fluxes from stars, known as stellar light curves, can reveal valuable information about stellar properties. However, most current methods rely on extracting summary statistics, and studies using deep learning have been limited to supervised approaches. In this research, we investigate the scaling law properties that emerge when learning from astronomical time series data using self-supervised techniques. By employing the GPT-2 architecture, we show the learned representation improves as the number of parameters increases from $10^4$ to $10^9$, with no signs of performance plateauing. We demonstrate that a self-supervised Transformer model achieves 3-10 times the sample efficiency compared to the state-of-the-art supervised learning model when inferring the surface gravity of stars as a downstream task. Our research lays the groundwork for analyzing stellar light curves by examining them through large-scale auto-regressive generative models.
6/18/2024
📈
AstroCLIP: A Cross-Modal Foundation Model for Galaxies
Liam Parker, Francois Lanusse, Siavash Golkar, Leopoldo Sarra, Miles Cranmer, Alberto Bietti, Michael Eickenberg, Geraud Krawezik, Michael McCabe, Ruben Ohana, Mariel Pettee, Bruno Regaldo-Saint Blancard, Tiberiu Tesileanu, Kyunghyun Cho, Shirley Ho
0
0
We present AstroCLIP, a single, versatile model that can embed both galaxy images and spectra into a shared, physically meaningful latent space. These embeddings can then be used - without any model fine-tuning - for a variety of downstream tasks including (1) accurate in-modality and cross-modality semantic similarity search, (2) photometric redshift estimation, (3) galaxy property estimation from both images and spectra, and (4) morphology classification. Our approach to implementing AstroCLIP consists of two parts. First, we embed galaxy images and spectra separately by pretraining separate transformer-based image and spectrum encoders in self-supervised settings. We then align the encoders using a contrastive loss. We apply our method to spectra from the Dark Energy Spectroscopic Instrument and images from its corresponding Legacy Imaging Survey. Overall, we find remarkable performance on all downstream tasks, even relative to supervised baselines. For example, for a task like photometric redshift prediction, we find similar performance to a specifically-trained ResNet18, and for additional tasks like physical property estimation (stellar mass, age, metallicity, and sSFR), we beat this supervised baseline by 19% in terms of $R^2$. We also compare our results to a state-of-the-art self-supervised single-modal model for galaxy images, and find that our approach outperforms this benchmark by roughly a factor of two on photometric redshift estimation and physical property prediction in terms of $R^2$, while remaining roughly in-line in terms of morphology classification. Ultimately, our approach represents the first cross-modal self-supervised model for galaxies, and the first self-supervised transformer-based architectures for galaxy images and spectra.
6/17/2024
Can AI Understand Our Universe? Test of Fine-Tuning GPT by Astrophysical Data
Yu Wang, Shu-Rui Zhang, Aidin Momtaz, Rahim Moradi, Fatemeh Rastegarnia, Narek Sahakyan, Soroush Shakeri, Liang Li
0
0
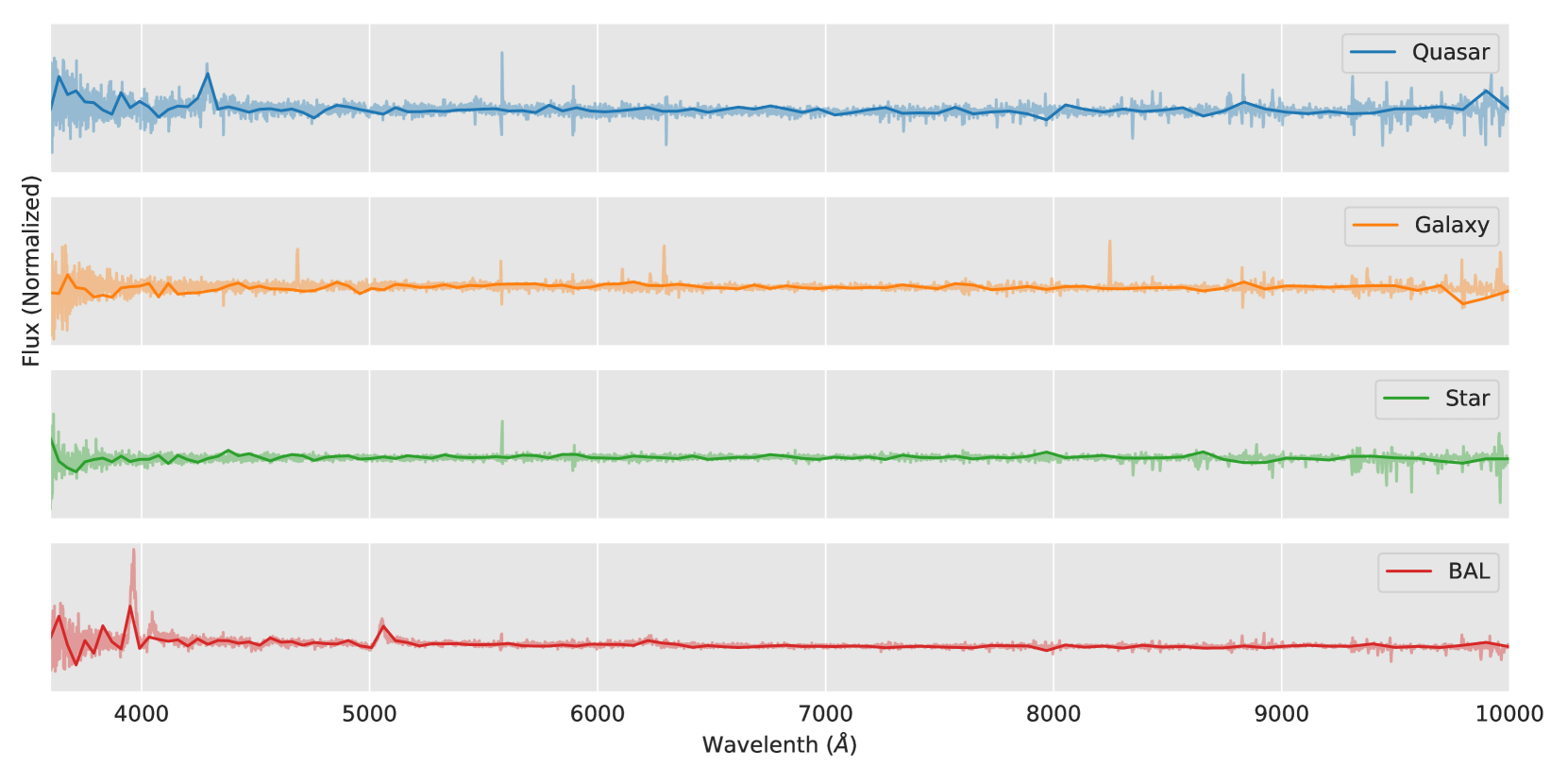
ChatGPT has been the most talked-about concept in recent months, captivating both professionals and the general public alike, and has sparked discussions about the changes that artificial intelligence (AI) will bring to the world. As physicists and astrophysicists, we are curious about if scientific data can be correctly analyzed by large language models (LLMs) and yield accurate physics. In this article, we fine-tune the generative pre-trained transformer (GPT) model by the astronomical data from the observations of galaxies, quasars, stars, gamma-ray bursts (GRBs), and the simulations of black holes (BHs), the fine-tuned model demonstrates its capability to classify astrophysical phenomena, distinguish between two types of GRBs, deduce the redshift of quasars, and estimate BH parameters. We regard this as a successful test, marking the LLM's proven efficacy in scientific research. With the ever-growing volume of multidisciplinary data and the advancement of AI technology, we look forward to the emergence of a more fundamental and comprehensive understanding of our universe. This article also shares some interesting thoughts on data collection and AI design. Using the approach of understanding the universe - looking outward at data and inward for fundamental building blocks - as a guideline, we propose a method of series expansion for AI, suggesting ways to train and control AI that is smarter than humans.
4/17/2024
👨🏫
Scaling-laws for Large Time-series Models
Thomas D. P. Edwards, James Alvey, Justin Alsing, Nam H. Nguyen, Benjamin D. Wandelt
0
0
Scaling laws for large language models (LLMs) have provided useful guidance on how to train ever larger models for predictable performance gains. Time series forecasting shares a similar sequential structure to language, and is amenable to large-scale transformer architectures. Here we show that foundational decoder-only time series transformer models exhibit analogous scaling-behavior to LLMs, while architectural details (aspect ratio and number of heads) have a minimal effect over broad ranges. We assemble a large corpus of heterogenous time series data on which to train, and establish, for the first time, power-law scaling relations with respect to parameter count, dataset size, and training compute, spanning five orders of magnitude.
5/24/2024