Axioms for AI Alignment from Human Feedback

0
🤖
Sign in to get full access
Overview
- This paper explores the problem of learning a reward function in reinforcement learning from human feedback (RLHF).
- The authors argue that this problem can be viewed through the lens of social choice theory, which provides a framework for evaluating different reward aggregation methods.
- The paper demonstrates that commonly used models, such as the Bradley-Terry-Luce Model, fail to meet basic axioms in social choice theory.
- In response, the authors develop novel rules for learning reward functions with strong axiomatic guarantees, introducing a new paradigm called linear social choice.
Plain English Explanation
When training AI systems using reinforcement learning from human feedback (RLHF), the reward function is typically derived from analyzing the preferences expressed by humans through pairwise comparisons. This is essentially a problem of preference aggregation, similar to how a group of people might try to come to a collective decision.
The authors of this paper suggest that we can evaluate different reward aggregation methods through the lens of social choice theory, which studies how to combine individual preferences into a collective decision. By applying the principles and axioms from social choice theory, the authors show that common models used in RLHF, such as the Bradley-Terry-Luce Model, fail to meet basic standards.
To address this issue, the authors develop new rules for learning reward functions that have strong guarantees based on social choice theory. The key innovation is that their approach has a linear structure, which greatly restricts the space of possible rules and leads to a new paradigm they call linear social choice.
Technical Explanation
The paper frames the problem of learning a reward function in RLHF as one of preference aggregation, which the authors argue largely falls within the scope of social choice theory. From this perspective, the authors evaluate different aggregation methods using established axioms, examining whether these methods meet or fail well-known standards.
The authors demonstrate that both the Bradley-Terry-Luce Model and its broad generalizations fail to meet basic axioms in social choice theory. In response, they develop novel rules for learning reward functions with strong axiomatic guarantees.
A key innovation from the standpoint of social choice is that the problem has a linear structure, which greatly restricts the space of feasible rules and leads to a new paradigm that the authors call linear social choice. This linear structure allows the authors to derive new reward learning algorithms with strong theoretical properties.
Critical Analysis
The paper presents a thoughtful and rigorous analysis of the reward learning problem in RLHF, drawing important connections to the field of social choice theory. By applying well-established axioms from this domain, the authors effectively highlight limitations in commonly used models, such as the Bradley-Terry-Luce Model.
One potential limitation of the research is that it primarily focuses on the theoretical properties of reward learning methods, without extensive empirical evaluation. While the authors demonstrate the axiomatic guarantees of their proposed rules, it would be valuable to see how these methods perform in practice compared to existing approaches.
Additionally, the authors acknowledge that their linear social choice framework may be limited in its ability to capture more complex human preferences. Further research may be needed to develop reward learning methods that can handle a wider range of preference structures while maintaining strong theoretical properties.
Overall, this paper makes a compelling case for the importance of grounding reward learning in the principles of social choice theory, and its insights could have significant implications for the design of RLHF systems and the broader field of AI alignment.
Conclusion
This paper presents a novel perspective on the problem of learning reward functions in reinforcement learning from human feedback (RLHF). By framing the task as one of preference aggregation, the authors leverage the principles of social choice theory to evaluate and develop new reward learning methods.
The key contribution of the paper is the introduction of a linear social choice framework, which provides a structured approach to designing reward learning algorithms with strong axiomatic guarantees. This work advances our understanding of the theoretical underpinnings of RLHF and could have significant implications for the development of AI systems that are better aligned with human values.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
0
Axioms for AI Alignment from Human Feedback
Luise Ge, Daniel Halpern, Evi Micha, Ariel D. Procaccia, Itai Shapira, Yevgeniy Vorobeychik, Junlin Wu
In the context of reinforcement learning from human feedback (RLHF), the reward function is generally derived from maximum likelihood estimation of a random utility model based on pairwise comparisons made by humans. The problem of learning a reward function is one of preference aggregation that, we argue, largely falls within the scope of social choice theory. From this perspective, we can evaluate different aggregation methods via established axioms, examining whether these methods meet or fail well-known standards. We demonstrate that both the Bradley-Terry-Luce Model and its broad generalizations fail to meet basic axioms. In response, we develop novel rules for learning reward functions with strong axiomatic guarantees. A key innovation from the standpoint of social choice is that our problem has a linear structure, which greatly restricts the space of feasible rules and leads to a new paradigm that we call linear social choice.
Read more5/24/2024
0
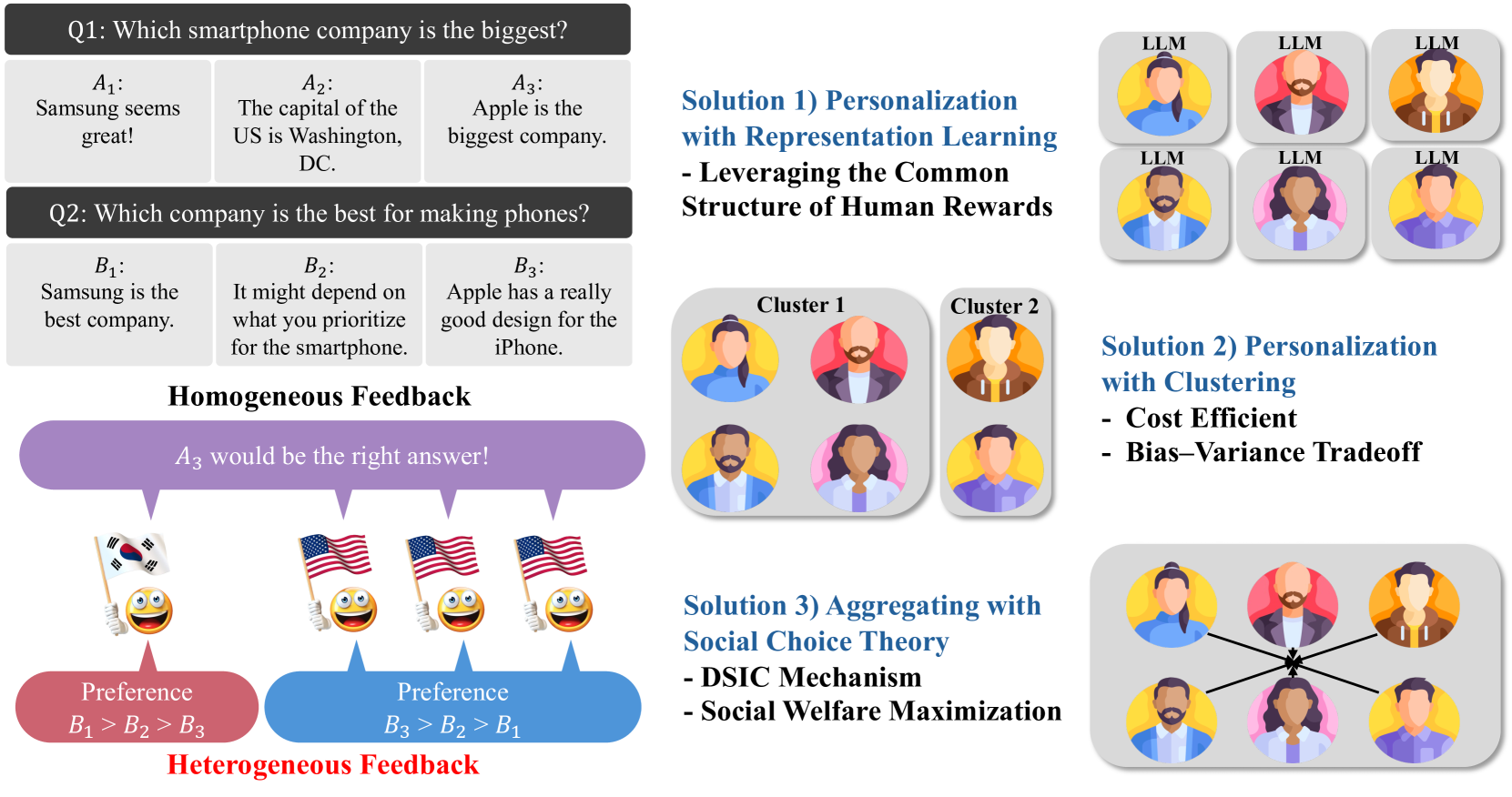
Principled RLHF from Heterogeneous Feedback via Personalization and Preference Aggregation
Chanwoo Park, Mingyang Liu, Dingwen Kong, Kaiqing Zhang, Asuman Ozdaglar
Reinforcement learning from human feedback (RLHF) has been an effective technique for aligning AI systems with human values, with remarkable successes in fine-tuning large-language models recently. Most existing RLHF paradigms make the underlying assumption that human preferences are relatively homogeneous, and can be encoded by a single reward model. In this paper, we focus on addressing the issues due to the inherent heterogeneity in human preferences, as well as their potential strategic behavior in providing feedback. Specifically, we propose two frameworks to address heterogeneous human feedback in principled ways: personalization-based one and aggregation-based one. For the former, we propose two approaches based on representation learning and clustering, respectively, for learning multiple reward models that trades off the bias (due to preference heterogeneity) and variance (due to the use of fewer data for learning each model by personalization). We then establish sample complexity guarantees for both approaches. For the latter, we aim to adhere to the single-model framework, as already deployed in the current RLHF paradigm, by carefully aggregating diverse and truthful preferences from humans. We propose two approaches based on reward and preference aggregation, respectively: the former utilizes both utilitarianism and Leximin approaches to aggregate individual reward models, with sample complexity guarantees; the latter directly aggregates the human feedback in the form of probabilistic opinions. Under the probabilistic-opinion-feedback model, we also develop an approach to handle strategic human labelers who may bias and manipulate the aggregated preferences with untruthful feedback. Based on the ideas in mechanism design, our approach ensures truthful preference reporting, with the induced aggregation rule maximizing social welfare functions.
Read more5/28/2024
🔎
0
Mapping Social Choice Theory to RLHF
Jessica Dai, Eve Fleisig
Recent work on the limitations of using reinforcement learning from human feedback (RLHF) to incorporate human preferences into model behavior often raises social choice theory as a reference point. Social choice theory's analysis of settings such as voting mechanisms provides technical infrastructure that can inform how to aggregate human preferences amid disagreement. We analyze the problem settings of social choice and RLHF, identify key differences between them, and discuss how these differences may affect the RLHF interpretation of well-known technical results in social choice.
Read more4/22/2024
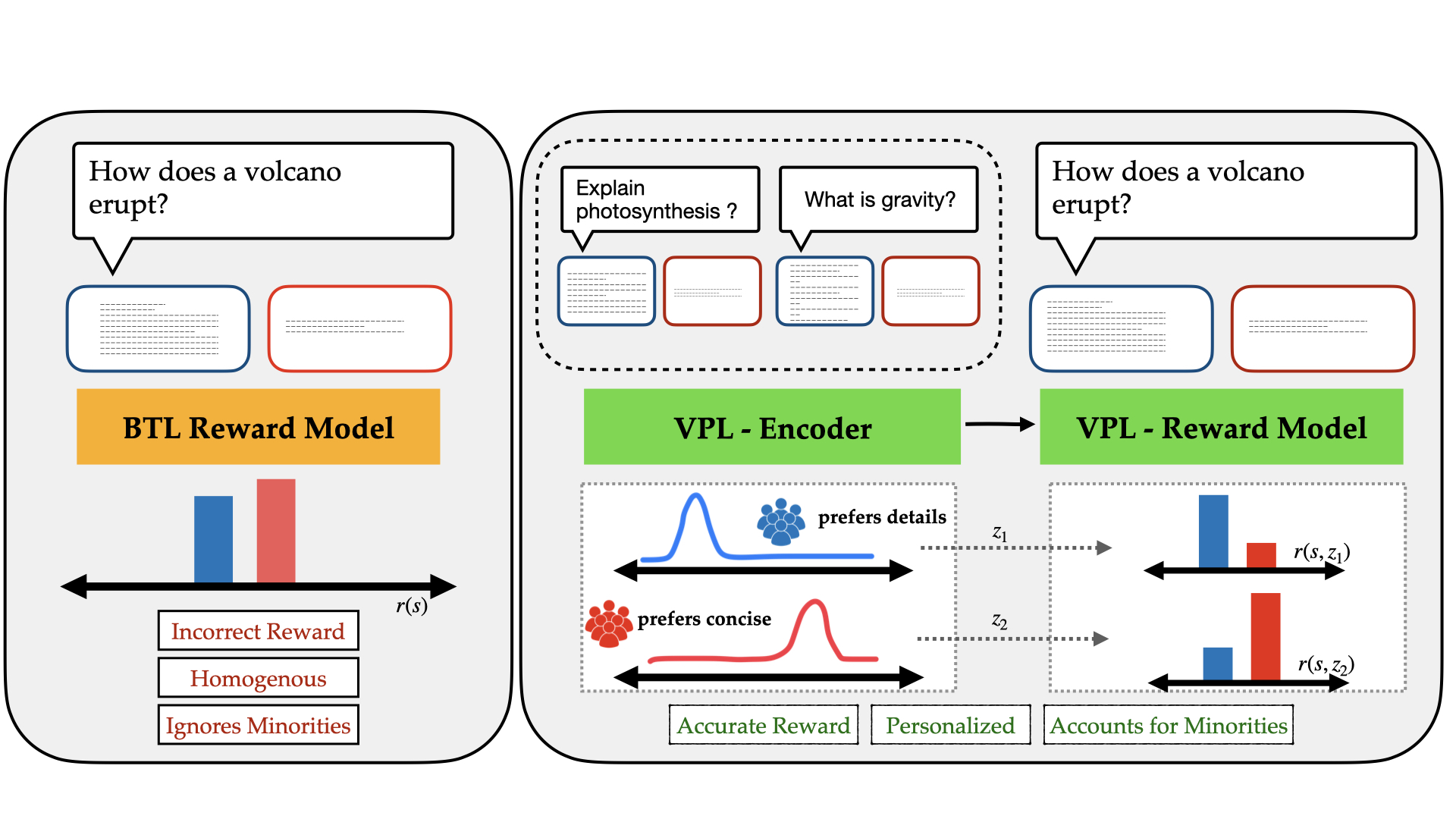
0
Personalizing Reinforcement Learning from Human Feedback with Variational Preference Learning
Sriyash Poddar, Yanming Wan, Hamish Ivison, Abhishek Gupta, Natasha Jaques
Reinforcement Learning from Human Feedback (RLHF) is a powerful paradigm for aligning foundation models to human values and preferences. However, current RLHF techniques cannot account for the naturally occurring differences in individual human preferences across a diverse population. When these differences arise, traditional RLHF frameworks simply average over them, leading to inaccurate rewards and poor performance for individual subgroups. To address the need for pluralistic alignment, we develop a class of multimodal RLHF methods. Our proposed techniques are based on a latent variable formulation - inferring a novel user-specific latent and learning reward models and policies conditioned on this latent without additional user-specific data. While conceptually simple, we show that in practice, this reward modeling requires careful algorithmic considerations around model architecture and reward scaling. To empirically validate our proposed technique, we first show that it can provide a way to combat underspecification in simulated control problems, inferring and optimizing user-specific reward functions. Next, we conduct experiments on pluralistic language datasets representing diverse user preferences and demonstrate improved reward function accuracy. We additionally show the benefits of this probabilistic framework in terms of measuring uncertainty, and actively learning user preferences. This work enables learning from diverse populations of users with divergent preferences, an important challenge that naturally occurs in problems from robot learning to foundation model alignment.
Read more8/20/2024