Benchmarking General Purpose In-Context Learning

0

Sign in to get full access
Overview
- This paper examines the ability of large language models to learn and generalize in-context, a key capability for AI systems to adapt to new tasks and environments.
- The researchers propose a novel benchmark called "Meta-Language" to test a model's ability to learn a randomized language from examples and apply that knowledge to new sentences.
- The paper compares the performance of several state-of-the-art language models on this benchmark and explores the factors that influence their in-context learning capabilities.
Plain English Explanation
The paper investigates how well large AI language models can learn new skills and apply them to different situations. This is an important capability, as it allows AI systems to adapt to new tasks and environments, rather than being limited to narrow, predefined functions.
To test this, the researchers created a novel benchmark called "Meta-Language." In this benchmark, the models are shown examples of a made-up, randomized language and then asked to use that knowledge to understand and generate new sentences in the same language. This tests the models' ability to quickly learn and generalize from a few examples, a key aspect of in-context learning.
The paper compares the performance of several state-of-the-art language models on this benchmark. It also explores the factors that influence the models' in-context learning capabilities, such as the amount of training data, the model architecture, and the specific task or language being learned.
By understanding the strengths and limitations of current AI systems in this area, the research can help guide the development of more adaptable and capable AI assistants that can better assist humans in a wide range of tasks and contexts.
Technical Explanation
The paper proposes a new benchmark called "Meta-Language" to test a model's ability to learn a randomized language from examples and apply that knowledge to new sentences. In this benchmark, the model is shown a set of example sentences in a made-up language, along with their English translations. The model must then use this limited training data to understand and generate new sentences in the same language.
The researchers evaluate several state-of-the-art language models, including GPT-3, InstructGPT, and HintedLLM, on their ability to learn and generalize in this Meta-Language task. They find that while the models can learn the basic structure of the language, their performance often degrades when the sentences become more complex or deviate from the training examples.
The paper also explores factors that influence the models' in-context learning capabilities, such as the amount of training data, the model architecture, and the specific task or language being learned. For example, larger models with more parameters tend to perform better on the Meta-Language task, but deeper models with more layers do not necessarily show an advantage.
Overall, the findings from this research highlight the potential and limitations of current AI systems in learning and generalizing from limited contextual information. By better understanding these capabilities, the research can inform the development of more adaptable and capable AI assistants.
Critical Analysis
The Meta-Language benchmark proposed in this paper provides a novel and interesting way to test a model's in-context learning abilities. However, the paper acknowledges that the benchmark may not fully capture the complexity of real-world language learning, as the randomized language used is relatively simple compared to natural human languages.
Additionally, while the paper explores several factors that influence the models' performance, there may be other important variables, such as the specific training data used or the model's prior knowledge, that could also play a role. The paper does not delve deeply into the mechanisms underlying the models' learning and generalization capabilities, which could provide additional insights.
Furthermore, the paper focuses primarily on the models' performance on the Meta-Language task, without much discussion of the potential real-world applications or implications of this research. It would be helpful to see a more in-depth exploration of how these findings could be applied to the development of more adaptable and capable AI systems.
Overall, the paper makes a valuable contribution to the understanding of in-context learning in large language models, but there is still room for further research and analysis to fully capture the nuances and potential of this important capability.
Conclusion
This paper presents a novel benchmark called "Meta-Language" to assess the in-context learning capabilities of large language models. The findings suggest that while current state-of-the-art models can learn and generalize from limited examples, their performance is often sensitive to the complexity of the language and the specific task at hand.
By exploring the factors that influence these in-context learning abilities, the research provides insights that can inform the development of more adaptable and capable AI systems. However, the paper also acknowledges the limitations of the benchmark and calls for further research to fully understand the mechanisms and real-world implications of this key capability.
Overall, this work represents an important step forward in the ongoing effort to create AI systems that can fluidly learn and apply new skills in a wide range of contexts, ultimately enhancing their ability to assist and collaborate with humans in meaningful ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Benchmarking General Purpose In-Context Learning
Fan Wang, Chuan Lin, Yang Cao, Yu Kang
In-context learning (ICL) empowers generative models to address new tasks effectively and efficiently on the fly, without relying on any artificially crafted optimization techniques. In this paper, we study extending ICL to address a broader range of tasks with an extended learning horizon and higher improvement potential, namely General-Purpose In-Context Learning (GPICL). To this end, we introduce two lightweight benchmarks specifically crafted to train and evaluate GPICL functionalities. Each benchmark encompasses a vast number of tasks characterized by significant task variance, facilitating meta-training that minimizes inductive bias. These tasks are also crafted to promote long-horizon in-context learning through continuous generation and interaction. These characteristics necessitate the models to leverage contexts and history interactions to enhance their capabilities, across domains such as language modeling, decision-making, and world modeling. Our experiments on the baseline models demonstrate that meta-training with minimal inductive bias and ICL from the ground up is feasible across all the domains we've discussed. Additionally, our findings indicate that the scale of parameters alone may not be crucial for ICL or GPICL, suggesting alternative approaches such as increasing the scale of contexts and memory states.
Read more6/27/2024
🌿
0
A Survey on In-context Learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, Zhifang Sui
With the increasing capabilities of large language models (LLMs), in-context learning (ICL) has emerged as a new paradigm for natural language processing (NLP), where LLMs make predictions based on contexts augmented with a few examples. It has been a significant trend to explore ICL to evaluate and extrapolate the ability of LLMs. In this paper, we aim to survey and summarize the progress and challenges of ICL. We first present a formal definition of ICL and clarify its correlation to related studies. Then, we organize and discuss advanced techniques, including training strategies, prompt designing strategies, and related analysis. Additionally, we explore various ICL application scenarios, such as data engineering and knowledge updating. Finally, we address the challenges of ICL and suggest potential directions for further research. We hope that our work can encourage more research on uncovering how ICL works and improving ICL.
Read more6/19/2024
📊
0
A Data Generation Perspective to the Mechanism of In-Context Learning
Haitao Mao, Guangliang Liu, Yao Ma, Rongrong Wang, Kristen Johnson, Jiliang Tang
In-Context Learning (ICL) empowers Large Language Models (LLMs) with the capacity to learn in context, achieving downstream generalization without gradient updates but with a few in-context examples. Despite the encouraging empirical success, the underlying mechanism of ICL remains unclear, and existing research offers various viewpoints of understanding. These studies propose intuition-driven and ad-hoc technical solutions for interpreting ICL, illustrating an ambiguous road map. In this paper, we leverage a data generation perspective to reinterpret recent efforts and demonstrate the potential broader usage of popular technical solutions, approaching a systematic angle. For a conceptual definition, we rigorously adopt the terms of skill learning and skill recognition. The difference between them is skill learning can learn new data generation functions from in-context data. We also provide a comprehensive study on the merits and weaknesses of different solutions, and highlight the uniformity among them given the perspective of data generation, establishing a technical foundation for future research to incorporate the strengths of different lines of research.
Read more8/19/2024
0
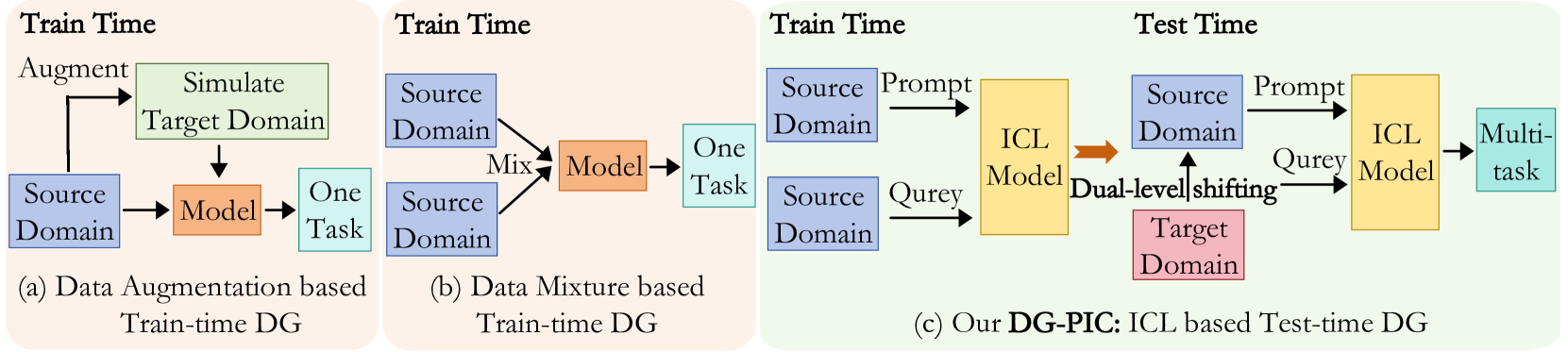
DG-PIC: Domain Generalized Point-In-Context Learning for Point Cloud Understanding
Jincen Jiang, Qianyu Zhou, Yuhang Li, Xuequan Lu, Meili Wang, Lizhuang Ma, Jian Chang, Jian Jun Zhang
Recent point cloud understanding research suffers from performance drops on unseen data, due to the distribution shifts across different domains. While recent studies use Domain Generalization (DG) techniques to mitigate this by learning domain-invariant features, most are designed for a single task and neglect the potential of testing data. Despite In-Context Learning (ICL) showcasing multi-task learning capability, it usually relies on high-quality context-rich data and considers a single dataset, and has rarely been studied in point cloud understanding. In this paper, we introduce a novel, practical, multi-domain multi-task setting, handling multiple domains and multiple tasks within one unified model for domain generalized point cloud understanding. To this end, we propose Domain Generalized Point-In-Context Learning (DG-PIC) that boosts the generalizability across various tasks and domains at testing time. In particular, we develop dual-level source prototype estimation that considers both global-level shape contextual and local-level geometrical structures for representing source domains and a dual-level test-time feature shifting mechanism that leverages both macro-level domain semantic information and micro-level patch positional relationships to pull the target data closer to the source ones during the testing. Our DG-PIC does not require any model updates during the testing and can handle unseen domains and multiple tasks, textit{i.e.,} point cloud reconstruction, denoising, and registration, within one unified model. We also introduce a benchmark for this new setting. Comprehensive experiments demonstrate that DG-PIC outperforms state-of-the-art techniques significantly.
Read more7/15/2024