Unveiling the Flaws: Exploring Imperfections in Synthetic Data and Mitigation Strategies for Large Language Models

0

Sign in to get full access
Overview
- This paper explores the imperfections and limitations of synthetic data used in training large language models (LLMs), and presents strategies for mitigating these issues.
- It investigates the impact of data flaws, such as biases and inconsistencies, on the performance and behavior of LLMs.
- The authors propose a range of mitigation techniques, including data augmentation, cross-validation, and the development of specialized LLM "experts" to address specific data-related challenges.
Plain English Explanation
Synthetic data is artificially created information that is used to train large language models (LLMs) - powerful AI systems that can understand and generate human-like text. However, this synthetic data may not be perfect and can contain flaws or biases. This paper explores the problems that can arise from using imperfect synthetic data to train LLMs, and suggests ways to address these issues.
The researchers found that the flaws in synthetic data, such as inconsistencies or inaccuracies, can lead to LLMs behaving in unexpected or undesirable ways. For example, an LLM trained on synthetic data with gender biases may exhibit those biases in its own outputs. The paper discusses how training on poor-quality synthetic data can negatively impact the performance and reliability of LLMs.
To mitigate these problems, the authors propose several strategies. One is using data augmentation techniques to improve the diversity and quality of the synthetic data. Another is developing specialized "expert" LLMs that are trained on high-quality data to handle specific tasks or domains, rather than relying on a single, general-purpose LLM. The paper also suggests using cross-validation to better evaluate the impact of synthetic data flaws.
By addressing these challenges, the researchers aim to help create more robust and reliable large language models that can be safely and effectively deployed in real-world applications.
Technical Explanation
The paper begins by discussing the growing reliance on synthetic data to train large language models (LLMs), and the potential issues that can arise from using imperfect or biased synthetic data. The authors investigate the impact of data flaws, such as inconsistencies, inaccuracies, and biases, on the performance and behavior of LLMs.
Through a series of experiments, the researchers demonstrate how training LLMs on synthetic data with various types of imperfections can lead to unexpected and undesirable model outputs. For example, they show how LLMs trained on synthetic data with gender biases can exhibit those biases in their own generated text.
To address these challenges, the paper proposes several mitigation strategies. One approach is data augmentation, where the synthetic data is systematically modified to increase its diversity and reduce biases. The authors also suggest using cross-validation techniques to better evaluate the impact of synthetic data flaws on model performance.
Additionally, the paper introduces the concept of specialized "expert" LLMs, which are trained on high-quality data to handle specific tasks or domains. This approach aims to create more robust and reliable language models that are less susceptible to the pitfalls of using imperfect synthetic data.
Critical Analysis
The paper provides a thorough exploration of the challenges posed by the use of synthetic data in training large language models. The authors have conducted a comprehensive set of experiments to demonstrate the potential issues, which lends credibility to their findings.
However, the paper does not delve deeply into the root causes of the synthetic data flaws or how they might arise in real-world scenarios. Further research could explore the mechanisms by which biases and inconsistencies are introduced into synthetic data during its generation.
Additionally, while the proposed mitigation strategies, such as data augmentation and specialized expert models, show promise, their effectiveness and practicality in large-scale deployment settings are not fully evaluated. More extensive testing and validation would be needed to assess the scalability and generalizability of these approaches.
Conclusion
This paper highlights the critical importance of understanding and addressing the limitations of synthetic data used in training large language models. By unveiling the flaws inherent in synthetic data and proposing mitigation strategies, the authors contribute to the ongoing efforts to develop more robust and reliable AI systems. The insights and techniques presented in this work have significant implications for the responsible development and deployment of large language models, which are increasingly integral to a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unveiling the Flaws: Exploring Imperfections in Synthetic Data and Mitigation Strategies for Large Language Models
Jie Chen, Yupeng Zhang, Bingning Wang, Wayne Xin Zhao, Ji-Rong Wen, Weipeng Chen
Synthetic data has been proposed as a solution to address the issue of high-quality data scarcity in the training of large language models (LLMs). Studies have shown that synthetic data can effectively improve the performance of LLMs on downstream benchmarks. However, despite its potential benefits, our analysis suggests that there may be inherent flaws in synthetic data. The uniform format of synthetic data can lead to pattern overfitting and cause significant shifts in the output distribution, thereby reducing the model's instruction-following capabilities. Our work delves into these specific flaws associated with question-answer (Q-A) pairs, a prevalent type of synthetic data, and presents a method based on unlearning techniques to mitigate these flaws. The empirical results demonstrate the effectiveness of our approach, which can reverse the instruction-following issues caused by pattern overfitting without compromising performance on benchmarks at relatively low cost. Our work has yielded key insights into the effective use of synthetic data, aiming to promote more robust and efficient LLM training.
Read more6/19/2024

0
Best Practices and Lessons Learned on Synthetic Data for Language Models
Ruibo Liu, Jerry Wei, Fangyu Liu, Chenglei Si, Yanzhe Zhang, Jinmeng Rao, Steven Zheng, Daiyi Peng, Diyi Yang, Denny Zhou, Andrew M. Dai
The success of AI models relies on the availability of large, diverse, and high-quality datasets, which can be challenging to obtain due to data scarcity, privacy concerns, and high costs. Synthetic data has emerged as a promising solution by generating artificial data that mimics real-world patterns. This paper provides an overview of synthetic data research, discussing its applications, challenges, and future directions. We present empirical evidence from prior art to demonstrate its effectiveness and highlight the importance of ensuring its factuality, fidelity, and unbiasedness. We emphasize the need for responsible use of synthetic data to build more powerful, inclusive, and trustworthy language models.
Read more8/13/2024
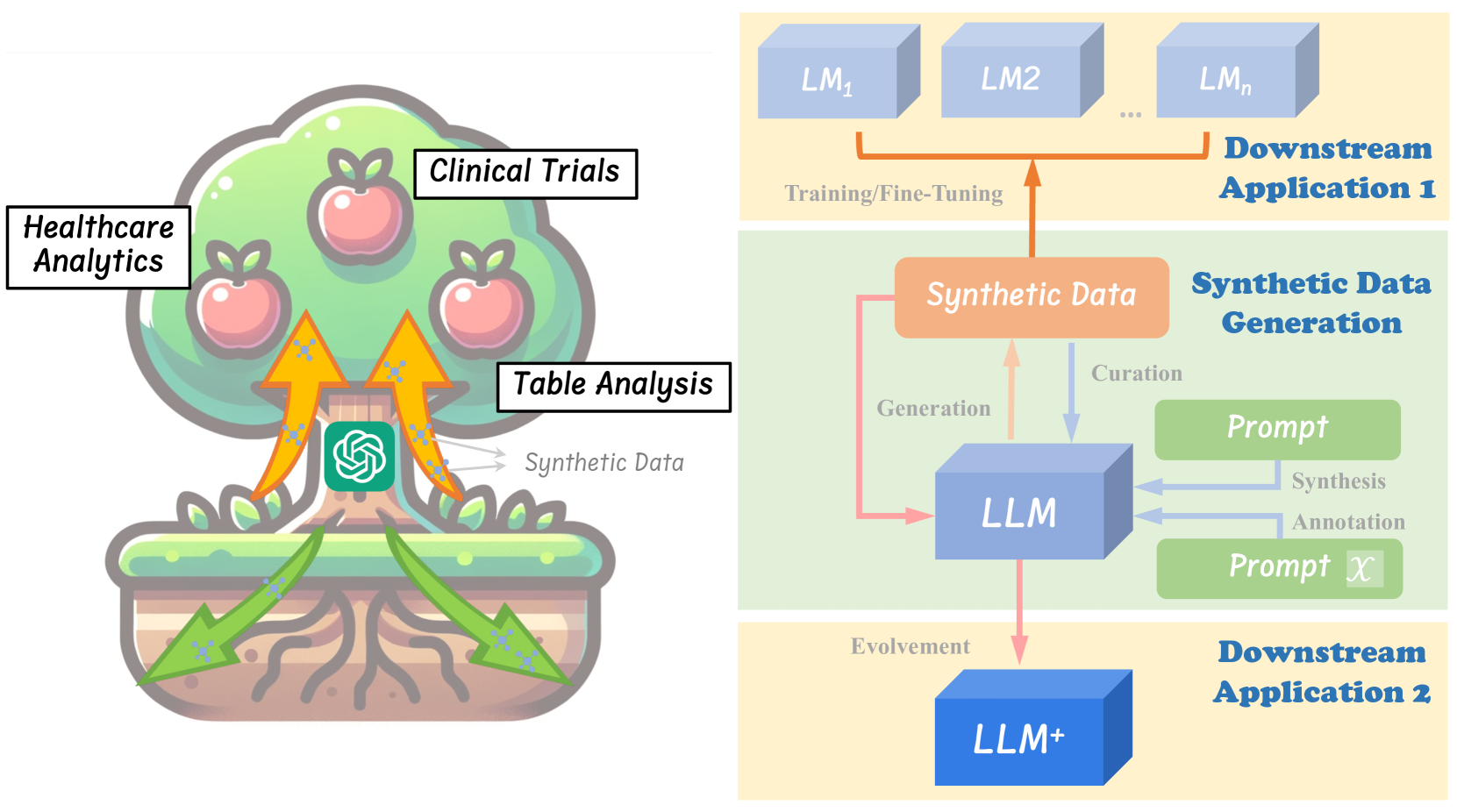
0
On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey
Lin Long, Rui Wang, Ruixuan Xiao, Junbo Zhao, Xiao Ding, Gang Chen, Haobo Wang
Within the evolving landscape of deep learning, the dilemma of data quantity and quality has been a long-standing problem. The recent advent of Large Language Models (LLMs) offers a data-centric solution to alleviate the limitations of real-world data with synthetic data generation. However, current investigations into this field lack a unified framework and mostly stay on the surface. Therefore, this paper provides an organization of relevant studies based on a generic workflow of synthetic data generation. By doing so, we highlight the gaps within existing research and outline prospective avenues for future study. This work aims to shepherd the academic and industrial communities towards deeper, more methodical inquiries into the capabilities and applications of LLMs-driven synthetic data generation.
Read more6/24/2024

0
An Empirical Study of Validating Synthetic Data for Formula Generation
Usneek Singh, Jos'e Cambronero, Sumit Gulwani, Aditya Kanade, Anirudh Khatry, Vu Le, Mukul Singh, Gust Verbruggen
Large language models (LLMs) can be leveraged to help with writing formulas in spreadsheets, but resources on these formulas are scarce, impacting both the base performance of pre-trained models and limiting the ability to fine-tune them. Given a corpus of formulas, we can use a(nother) model to generate synthetic natural language utterances for fine-tuning. However, it is important to validate whether the NL generated by the LLM is indeed accurate to be beneficial for fine-tuning. In this paper, we provide empirical results on the impact of validating these synthetic training examples with surrogate objectives that evaluate the accuracy of the synthetic annotations. We demonstrate that validation improves performance over raw data across four models (2 open and 2 closed weight). Interestingly, we show that although validation tends to prune more challenging examples, it increases the complexity of problems that models can solve after being fine-tuned on validated data.
Read more7/24/2024