Boosting Multimodal Large Language Models with Visual Tokens Withdrawal for Rapid Inference
2405.05803
0
0

Abstract
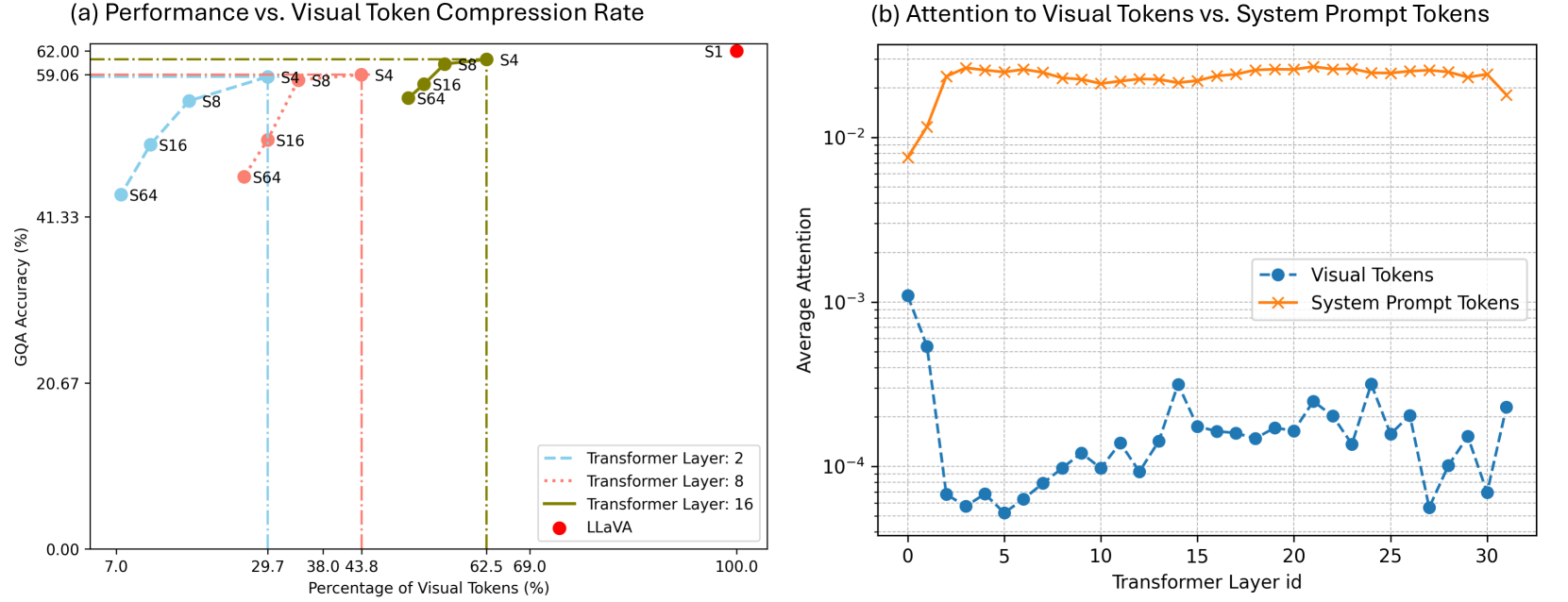
Multimodal large language models (MLLMs) demand considerable computations for inference due to the extensive parameters and the additional input tokens needed for visual information representation. Herein, we introduce Visual Tokens Withdrawal (VTW), a plug-and-play module to boost MLLMs for rapid inference. Our approach is inspired by two intriguing phenomena we have observed: (1) the attention sink phenomenon that is prevalent in LLMs also persists in MLLMs, suggesting that initial tokens and nearest tokens receive the majority of attention, while middle vision tokens garner minimal attention in deep layers; (2) the presence of information migration, which implies that visual information is transferred to subsequent text tokens within the first few layers of MLLMs. As per our findings, we conclude that vision tokens are not necessary in the deep layers of MLLMs. Thus, we strategically withdraw them at a certain layer, enabling only text tokens to engage in subsequent layers. To pinpoint the ideal layer for vision tokens withdrawal, we initially analyze a limited set of tiny datasets and choose the first layer that meets the Kullback-Leibler divergence criterion. Our VTW approach can cut computational overhead by over 40% across diverse multimodal tasks while maintaining performance. Our code is released at https://github.com/lzhxmu/VTW.
Create account to get full access
Overview
- This paper explores ways to boost the performance of multimodal large language models, which are AI systems that can understand and generate both text and images.
- The key idea is to "withdraw" or remove visual tokens (image features) from the model during inference (making predictions) to speed up the process without significantly hurting accuracy.
- The authors test this approach on several benchmark tasks and find it can significantly reduce inference time while maintaining high performance.
Plain English Explanation
The paper looks at how to make large AI models that can work with both text and images more efficient. These types of models, called "multimodal large language models," are powerful but can be slow to use. The researchers tried removing some of the image-related parts of the model during the prediction stage. This "visual tokens withdrawal" approach sped up the models without greatly reducing their accuracy on various tasks.
The core idea is that these models don't always need to fully process the visual information to do well on certain tasks. By selectively removing some of the image features, the models can run faster while still maintaining strong performance. This could be useful for applications where speed is important, like real-time chatbots or image search.
Technical Explanation
The paper presents a method called "Visual Tokens Withdrawal" (VTW) to improve the efficiency of multimodal large language models. These models typically take both text and visual inputs, but processing the visual data can be computationally expensive and slow down inference.
The VTW approach selectively removes visual tokens (image features) from the model during inference, reducing the computational burden without significantly impacting accuracy. The authors evaluate this on several multimodal benchmarks, including image-text retrieval, visual question answering, and image captioning. They find that VTW can provide up to 3x faster inference with only modest accuracy reductions.
The authors also propose an "adaptive" VTW approach that dynamically adjusts the number of visual tokens retained based on the specific input, further improving efficiency. This builds on prior work on efficient multimodal models.
Critical Analysis
The paper presents a compelling approach for improving the efficiency of multimodal language models. The authors thoroughly evaluate their method and demonstrate its effectiveness across several benchmark tasks. However, some potential limitations and areas for further research include:
- The study only considers a limited set of multimodal tasks and datasets. More extensive testing on a broader range of applications would help validate the generalizability of the VTW approach.
- The adaptive VTW method relies on a separate model to predict the optimal number of visual tokens to retain. The overhead of this additional model could offset some of the efficiency gains, and its performance may vary across different types of inputs.
- The paper does not explore the impact of VTW on the model's ability to learn and generalize from multimodal data. Removing visual tokens during training could potentially degrade the model's multimodal understanding.
Overall, this research represents an interesting step towards more efficient multimodal language models, but further work is needed to fully understand the tradeoffs and limitations of the approach.
Conclusion
This paper introduces a novel technique called "Visual Tokens Withdrawal" that can significantly improve the efficiency of multimodal large language models without sacrificing too much accuracy. By selectively removing visual features during inference, the models can run much faster, which could enable new real-time applications that leverage both text and images.
While the authors demonstrate promising results, further research is needed to explore the broader implications and potential limitations of this approach. Nonetheless, the VTW method represents an important advance in the field of efficient multimodal AI, and could pave the way for more powerful and practical applications in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LLaVA-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, Yan Yan
0
0
Large Multimodal Models (LMMs) have shown significant visual reasoning capabilities by connecting a visual encoder and a large language model. LMMs typically take in a fixed and large amount of visual tokens, such as the penultimate layer features in the CLIP visual encoder, as the prefix content. Recent LMMs incorporate more complex visual inputs, such as high-resolution images and videos, which further increases the number of visual tokens significantly. However, due to the inherent design of the Transformer architecture, the computational costs of these models tend to increase quadratically with the number of input tokens. To tackle this problem, we explore a token reduction mechanism that identifies significant spatial redundancy among visual tokens. In response, we propose PruMerge, a novel adaptive visual token reduction strategy that significantly reduces the number of visual tokens without compromising the performance of LMMs. Specifically, to metric the importance of each token, we exploit the sparsity observed in the visual encoder, characterized by the sparse distribution of attention scores between the class token and visual tokens. This sparsity enables us to dynamically select the most crucial visual tokens to retain. Subsequently, we cluster the selected (unpruned) tokens based on their key similarity and merge them with the unpruned tokens, effectively supplementing and enhancing their informational content. Empirically, when applied to LLaVA-1.5, our approach can compress the visual tokens by 14 times on average, and achieve comparable performance across diverse visual question-answering and reasoning tasks. Code and checkpoints are at https://llava-prumerge.github.io/.
5/24/2024

Visual Perception by Large Language Model's Weights
Feipeng Ma, Hongwei Xue, Guangting Wang, Yizhou Zhou, Fengyun Rao, Shilin Yan, Yueyi Zhang, Siying Wu, Mike Zheng Shou, Xiaoyan Sun
0
0
Existing Multimodal Large Language Models (MLLMs) follow the paradigm that perceives visual information by aligning visual features with the input space of Large Language Models (LLMs), and concatenating visual tokens with text tokens to form a unified sequence input for LLMs. These methods demonstrate promising results on various vision-language tasks but are limited by the high computational effort due to the extended input sequence resulting from the involvement of visual tokens. In this paper, instead of input space alignment, we propose a novel parameter space alignment paradigm that represents visual information as model weights. For each input image, we use a vision encoder to extract visual features, convert features into perceptual weights, and merge the perceptual weights with LLM's weights. In this way, the input of LLM does not require visual tokens, which reduces the length of the input sequence and greatly improves efficiency. Following this paradigm, we propose VLoRA with the perceptual weights generator. The perceptual weights generator is designed to convert visual features to perceptual weights with low-rank property, exhibiting a form similar to LoRA. The experimental results show that our VLoRA achieves comparable performance on various benchmarks for MLLMs, while significantly reducing the computational costs for both training and inference. The code and models will be made open-source.
5/31/2024
New!LLaVolta: Efficient Multi-modal Models via Stage-wise Visual Context Compression
Jieneng Chen, Luoxin Ye, Ju He, Zhao-Yang Wang, Daniel Khashabi, Alan Yuille
0
0
While significant advancements have been made in compressed representations for text embeddings in large language models (LLMs), the compression of visual tokens in large multi-modal models (LMMs) has remained a largely overlooked area. In this work, we present the study on the analysis of redundancy concerning visual tokens and efficient training within these models. Our initial experiments show that eliminating up to 70% of visual tokens at the testing stage by simply average pooling only leads to a minimal 3% reduction in visual question answering accuracy on the GQA benchmark, indicating significant redundancy in visual context. Addressing this, we introduce Visual Context Compressor, which reduces the number of visual tokens during training to enhance training efficiency without sacrificing performance. To minimize information loss caused by the compression on visual tokens while maintaining training efficiency, we develop LLaVolta as a lite training scheme. LLaVolta incorporates stage-wise visual context compression to progressively compress the visual tokens from heavily to lightly, and finally no compression at the end of training, yielding no loss of information when testing. Extensive experiments demonstrate that our approach enhances the performance of MLLMs in both image-language and video-language understanding, while also significantly cutting training costs. Code is available at https://github.com/Beckschen/LLaVolta
7/1/2024

From Redundancy to Relevance: Enhancing Explainability in Multimodal Large Language Models
Xiaofeng Zhang, Chen Shen, Xiaosong Yuan, Shaotian Yan, Liang Xie, Wenxiao Wang, Chaochen Gu, Hao Tang, Jieping Ye
0
0
Recently, multimodal large language models have exploded with an endless variety, most of the popular Large Vision Language Models (LVLMs) depend on sequential visual representation, where images are converted into hundreds or thousands of tokens before being input into the Large Language Model (LLM) along with language prompts. The black-box design hinders the interpretability of visual-language models, especially regarding more complex reasoning tasks. To explore the interaction process between image and text in complex reasoning tasks, we introduce the information flow method to visualize the interaction mechanism. By analyzing the dynamic flow of the information flow, we find that the information flow appears to converge in the shallow layer. Further investigation revealed a redundancy of the image token in the shallow layer. Consequently, a truncation strategy was introduced to aggregate image tokens within these shallow layers. This approach has been validated through experiments across multiple models, yielding consistent improvements.
6/14/2024