Boosting Self-Supervision for Single-View Scene Completion via Knowledge Distillation

0
🧪
Sign in to get full access
Overview
- Proposes a method called "Multi-View Behind the Scenes (MVBTS)" to fuse density fields from multiple images for improved single-view scene completion
- Introduces a new technique called "KDBTS" that uses knowledge distillation to train a single-view scene completion network directly from the MVBTS model
- Achieves state-of-the-art performance on occupancy prediction, especially in occluded regions
Plain English Explanation
Scene reconstruction from images is a fundamental problem in computer vision. While previous methods have focused on the visible parts of a scene, the task of scene completion aims to reason about the geometry of occluded regions as well.
The recent popularity of neural radiance fields (NeRFs) has made implicit representations, such as density fields, a promising approach for scene completion. Unlike explicit methods like voxel-based techniques, density fields allow for accurate depth prediction and novel-view synthesis.
This work proposes a method called MVBTS that fuses the scene reconstruction from multiple images into a more accurate single-view scene reconstruction. It does this by training a density field model in a fully self-supervised way using only image data.
The researchers then use a technique called knowledge distillation to train a separate single-view scene completion network called KDBTS directly from the MVBTS model. This allows KDBTS to achieve state-of-the-art performance on predicting the occupancy of occluded regions, outperforming other single-view methods.
The key innovation is the use of multiple views to learn a more comprehensive density field representation, which can then be distilled into a powerful single-view model. This advances the state-of-the-art in scene completion, with particular benefits for reasoning about hidden geometry.
Technical Explanation
The proposed MVBTS approach fuses density fields from multiple posed images to learn a more accurate representation of the scene, including occluded regions. It does this in a fully self-supervised way, using only image data without any ground truth 3D information.
The key insight is that by aggregating the information from multiple viewpoints, the model can learn a more complete density field that better captures the full 3D geometry of the scene. This is in contrast to single-view methods, which are limited to only the visible regions.
To leverage this multi-view knowledge, the researchers then use a knowledge distillation technique to train a separate single-view scene completion network called KDBTS. KDBTS is directly supervised by the learned density field from MVBTS, allowing it to accurately predict occupancy even in occluded areas.
Experiments show that KDBTS achieves state-of-the-art performance on scene completion benchmarks, particularly in terms of accurately reconstructing hidden geometry. This demonstrates the value of the multi-view fusion approach and the effectiveness of the knowledge distillation training.
Critical Analysis
The paper makes a strong contribution by showing how multi-view learning can be leveraged to improve single-view scene completion. The use of density fields as an intermediate representation is well-justified, as it allows for accurate depth prediction and novel-view synthesis.
One potential limitation is the reliance on posed images, which may not always be available in practical scenarios. An interesting avenue for future work could be to explore self-supervised camera pose estimation, as in IncJoint or MonoSelfRecon, to make the approach more widely applicable.
Additionally, while the paper demonstrates strong performance on occupancy prediction, it would be valuable to also evaluate the quality of the reconstructed geometry, for example by comparing to ground truth PlaneNeRF reconstructions. This could provide further insights into the strengths and limitations of the proposed approach.
Overall, this work represents an important step forward in single-view scene completion by leveraging multi-view learning. The ideas presented here could inspire further research into more robust and generalizable scene reconstruction techniques.
Conclusion
This paper introduces a novel approach called MVBTS that fuses density fields from multiple images to learn a more comprehensive representation of a scene, including occluded regions. By distilling this multi-view knowledge into a single-view model called KDBTS, the researchers achieve state-of-the-art performance on scene completion tasks, particularly in predicting the occupancy of hidden geometry.
The key innovation is the use of multi-view learning to overcome the limitations of single-view methods, which are confined to only the visible parts of a scene. This work demonstrates the power of leveraging multiple perspectives to build more accurate and complete 3D scene reconstructions from image data alone.
The ideas presented here could have far-reaching implications for a wide range of computer vision applications, from robotic navigation to augmented reality, by enabling more accurate and robust scene understanding. As the field of 3D reconstruction continues to evolve, this research represents an important step forward in the quest to truly "see behind the scenes" of complex environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧪
0
Boosting Self-Supervision for Single-View Scene Completion via Knowledge Distillation
Keonhee Han, Dominik Muhle, Felix Wimbauer, Daniel Cremers
Inferring scene geometry from images via Structure from Motion is a long-standing and fundamental problem in computer vision. While classical approaches and, more recently, depth map predictions only focus on the visible parts of a scene, the task of scene completion aims to reason about geometry even in occluded regions. With the popularity of neural radiance fields (NeRFs), implicit representations also became popular for scene completion by predicting so-called density fields. Unlike explicit approaches. e.g. voxel-based methods, density fields also allow for accurate depth prediction and novel-view synthesis via image-based rendering. In this work, we propose to fuse the scene reconstruction from multiple images and distill this knowledge into a more accurate single-view scene reconstruction. To this end, we propose Multi-View Behind the Scenes (MVBTS) to fuse density fields from multiple posed images, trained fully self-supervised only from image data. Using knowledge distillation, we use MVBTS to train a single-view scene completion network via direct supervision called KDBTS. It achieves state-of-the-art performance on occupancy prediction, especially in occluded regions.
Read more4/12/2024

0
Revisit Self-supervised Depth Estimation with Local Structure-from-Motion
Shengjie Zhu, Xiaoming Liu
Both self-supervised depth estimation and Structure-from-Motion (SfM) recover scene depth from RGB videos. Despite sharing a similar objective, the two approaches are disconnected. Prior works of self-supervision backpropagate losses defined within immediate neighboring frames. Instead of learning-through-loss, this work proposes an alternative scheme by performing local SfM. First, with calibrated RGB or RGB-D images, we employ a depth and correspondence estimator to infer depthmaps and pair-wise correspondence maps. Then, a novel bundle-RANSAC-adjustment algorithm jointly optimizes camera poses and one depth adjustment for each depthmap. Finally, we fix camera poses and employ a NeRF, however, without a neural network, for dense triangulation and geometric verification. Poses, depth adjustments, and triangulated sparse depths are our outputs. For the first time, we show self-supervision within $5$ frames already benefits SoTA supervised depth and correspondence models. The project page is held in the link (https://shngjz.github.io/SSfM.github.io/).
Read more8/9/2024
0
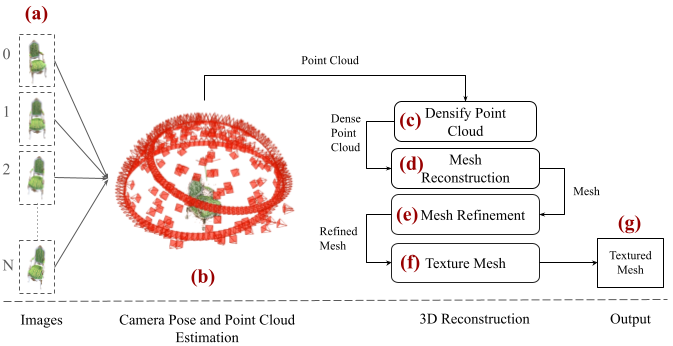
MVSBoost: An Efficient Point Cloud-based 3D Reconstruction
Umair Haroon, Ahmad AlMughrabi, Ricardo Marques, Petia Radeva
Efficient and accurate 3D reconstruction is crucial for various applications, including augmented and virtual reality, medical imaging, and cinematic special effects. While traditional Multi-View Stereo (MVS) systems have been fundamental in these applications, using neural implicit fields in implicit 3D scene modeling has introduced new possibilities for handling complex topologies and continuous surfaces. However, neural implicit fields often suffer from computational inefficiencies, overfitting, and heavy reliance on data quality, limiting their practical use. This paper presents an enhanced MVS framework that integrates multi-view 360-degree imagery with robust camera pose estimation via Structure from Motion (SfM) and advanced image processing for point cloud densification, mesh reconstruction, and texturing. Our approach significantly improves upon traditional MVS methods, offering superior accuracy and precision as validated using Chamfer distance metrics on the Realistic Synthetic 360 dataset. The developed MVS technique enhances the detail and clarity of 3D reconstructions and demonstrates superior computational efficiency and robustness in complex scene reconstruction, effectively handling occlusions and varying viewpoints. These improvements suggest that our MVS framework can compete with and potentially exceed current state-of-the-art neural implicit field methods, especially in scenarios requiring real-time processing and scalability.
Read more7/19/2024
0
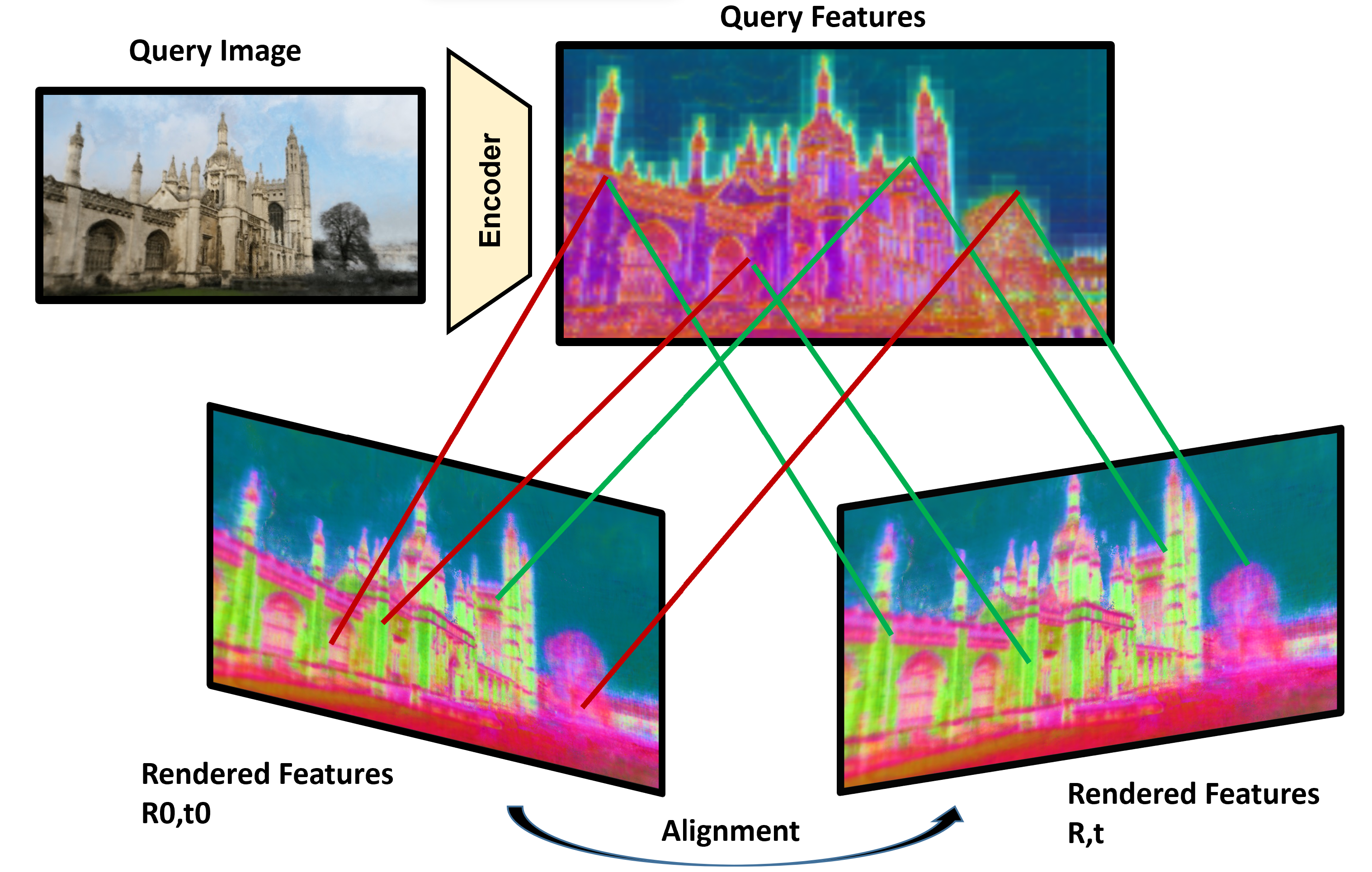
Self-supervised Learning of Neural Implicit Feature Fields for Camera Pose Refinement
Maxime Pietrantoni, Gabriela Csurka, Martin Humenberger, Torsten Sattler
Visual localization techniques rely upon some underlying scene representation to localize against. These representations can be explicit such as 3D SFM map or implicit, such as a neural network that learns to encode the scene. The former requires sparse feature extractors and matchers to build the scene representation. The latter might lack geometric grounding not capturing the 3D structure of the scene well enough. This paper proposes to jointly learn the scene representation along with a 3D dense feature field and a 2D feature extractor whose outputs are embedded in the same metric space. Through a contrastive framework we align this volumetric field with the image-based extractor and regularize the latter with a ranking loss from learned surface information. We learn the underlying geometry of the scene with an implicit field through volumetric rendering and design our feature field to leverage intermediate geometric information encoded in the implicit field. The resulting features are discriminative and robust to viewpoint change while maintaining rich encoded information. Visual localization is then achieved by aligning the image-based features and the rendered volumetric features. We show the effectiveness of our approach on real-world scenes, demonstrating that our approach outperforms prior and concurrent work on leveraging implicit scene representations for localization.
Read more6/13/2024