Bridging the Gap Between End-to-End and Two-Step Text Spotting

0

Sign in to get full access
Overview
- This paper explores a novel approach to text spotting, which is the task of detecting and recognizing text in images.
- The researchers propose a method that bridges the gap between "end-to-end" text spotting models, which perform detection and recognition jointly, and "two-step" models, which separate these tasks.
- The key innovation is a flexible architecture that allows for efficient training and inference, with state-of-the-art performance on standard benchmarks.
Plain English Explanation
The paper describes a new way to detect and read text in images, which is an important task in computer vision with many real-world applications. Existing approaches can be broadly categorized as "end-to-end" or "two-step" models.
End-to-end models try to do everything at once - they detect where the text is in the image and then recognize what the text says. Two-step models break this down into two separate tasks: first they find the text regions, then they read the text in those regions.
The key insight in this paper is that you can get the best of both worlds by designing a flexible architecture that can switch between end-to-end and two-step modes. This allows the model to be efficient during training and inference, while still achieving state-of-the-art performance. The authors show how this approach can outperform previous models on standard benchmarks for text spotting.
Technical Explanation
The proposed method, called "Bridging Transformer" (BT), consists of two main components: a detection module and a recognition module. The detection module uses a transformer-based object detection architecture to find text regions in the image. The recognition module then takes these regions and predicts the text content.
Crucially, the BT model can operate in either an end-to-end or two-step mode. In end-to-end mode, the detection and recognition modules are jointly trained and executed in a single forward pass. In two-step mode, the modules are trained and run sequentially.
The authors show that this flexibility allows BT to achieve state-of-the-art results on standard text spotting benchmarks. They find that the two-step mode is more efficient during inference, while the end-to-end mode can be more accurate in some cases.
Critical Analysis
The paper makes a compelling case for the Bridging Transformer approach, with thorough experiments and clear insights. However, there are a few potential limitations and areas for further research:
- The paper only evaluates BT on standard text spotting datasets, which may not capture the full diversity of real-world text in images. Exploring the model's performance on more challenging or domain-specific data could be valuable.
- The authors do not provide a detailed analysis of the tradeoffs between end-to-end and two-step mode in different scenarios. More work could be done to understand when each approach is preferable.
- While the flexible architecture is a key contribution, the paper does not explore the potential for further innovations in the individual detection and recognition components.
Overall, this paper presents an interesting and practical advance in text spotting that could have significant impact in applications like image analysis and document understanding.
Conclusion
This paper introduces a novel text spotting method called Bridging Transformer that bridges the gap between end-to-end and two-step approaches. By combining a flexible architecture with state-of-the-art performance, the authors demonstrate a compelling way to advance the field of text detection and recognition in images. While there are some potential avenues for further research, this work represents an important step forward in making text spotting more efficient and robust.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Bridging the Gap Between End-to-End and Two-Step Text Spotting
Mingxin Huang, Hongliang Li, Yuliang Liu, Xiang Bai, Lianwen Jin
Modularity plays a crucial role in the development and maintenance of complex systems. While end-to-end text spotting efficiently mitigates the issues of error accumulation and sub-optimal performance seen in traditional two-step methodologies, the two-step methods continue to be favored in many competitions and practical settings due to their superior modularity. In this paper, we introduce Bridging Text Spotting, a novel approach that resolves the error accumulation and suboptimal performance issues in two-step methods while retaining modularity. To achieve this, we adopt a well-trained detector and recognizer that are developed and trained independently and then lock their parameters to preserve their already acquired capabilities. Subsequently, we introduce a Bridge that connects the locked detector and recognizer through a zero-initialized neural network. This zero-initialized neural network, initialized with weights set to zeros, ensures seamless integration of the large receptive field features in detection into the locked recognizer. Furthermore, since the fixed detector and recognizer cannot naturally acquire end-to-end optimization features, we adopt the Adapter to facilitate their efficient learning of these features. We demonstrate the effectiveness of the proposed method through extensive experiments: Connecting the latest detector and recognizer through Bridging Text Spotting, we achieved an accuracy of 83.3% on Total-Text, 69.8% on CTW1500, and 89.5% on ICDAR 2015. The code is available at https://github.com/mxin262/Bridging-Text-Spotting.
Read more4/9/2024
0
FastTextSpotter: A High-Efficiency Transformer for Multilingual Scene Text Spotting
Alloy Das, Sanket Biswas, Umapada Pal, Josep Llad'os, Saumik Bhattacharya
The proliferation of scene text in both structured and unstructured environments presents significant challenges in optical character recognition (OCR), necessitating more efficient and robust text spotting solutions. This paper presents FastTextSpotter, a framework that integrates a Swin Transformer visual backbone with a Transformer Encoder-Decoder architecture, enhanced by a novel, faster self-attention unit, SAC2, to improve processing speeds while maintaining accuracy. FastTextSpotter has been validated across multiple datasets, including ICDAR2015 for regular texts and CTW1500 and TotalText for arbitrary-shaped texts, benchmarking against current state-of-the-art models. Our results indicate that FastTextSpotter not only achieves superior accuracy in detecting and recognizing multilingual scene text (English and Vietnamese) but also improves model efficiency, thereby setting new benchmarks in the field. This study underscores the potential of advanced transformer architectures in improving the adaptability and speed of text spotting applications in diverse real-world settings. The dataset, code, and pre-trained models have been released in our Github.
Read more8/28/2024

0
LOGO: Video Text Spotting with Language Collaboration and Glyph Perception Model
Hongen Liu, Di Sun, Jiahao Wang, Yi Liu, Gang Pan
Video text spotting (VTS) aims to simultaneously localize, recognize and track text instances in videos. To address the limited recognition capability of end-to-end methods, recent methods track the zero-shot results of state-of-the-art image text spotters directly, and achieve impressive performance. However, owing to the domain gap between different datasets, these methods usually obtain limited tracking trajectories on extreme dataset. Fine-tuning transformer-based text spotters on specific datasets could yield performance enhancements, albeit at the expense of considerable training resources. In this paper, we propose a Language Collaboration and Glyph Perception Model, termed LOGO, an innovative framework designed to enhance the performance of conventional text spotters. To achieve this goal, we design a language synergy classifier (LSC) to explicitly discern text instances from background noise in the recognition stage. Specially, the language synergy classifier can output text content or background code based on the legibility of text regions, thus computing language scores. Subsequently, fusion scores are computed by taking the average of detection scores and language scores, and are utilized to re-score the detection results before tracking. By the re-scoring mechanism, the proposed LSC facilitates the detection of low-resolution text instances while filtering out text-like regions. Moreover, the glyph supervision is introduced to enhance the recognition accuracy of noisy text regions. In addition, we propose the visual position mixture module, which can merge the position information and visual features efficiently, and acquire more discriminative tracking features. Extensive experiments on public benchmarks validate the effectiveness of the proposed method.
Read more6/13/2024
0
Bridging the Gap: Integrating Pre-trained Speech Enhancement and Recognition Models for Robust Speech Recognition
Kuan-Chen Wang, You-Jin Li, Wei-Lun Chen, Yu-Wen Chen, Yi-Ching Wang, Ping-Cheng Yeh, Chao Zhang, Yu Tsao
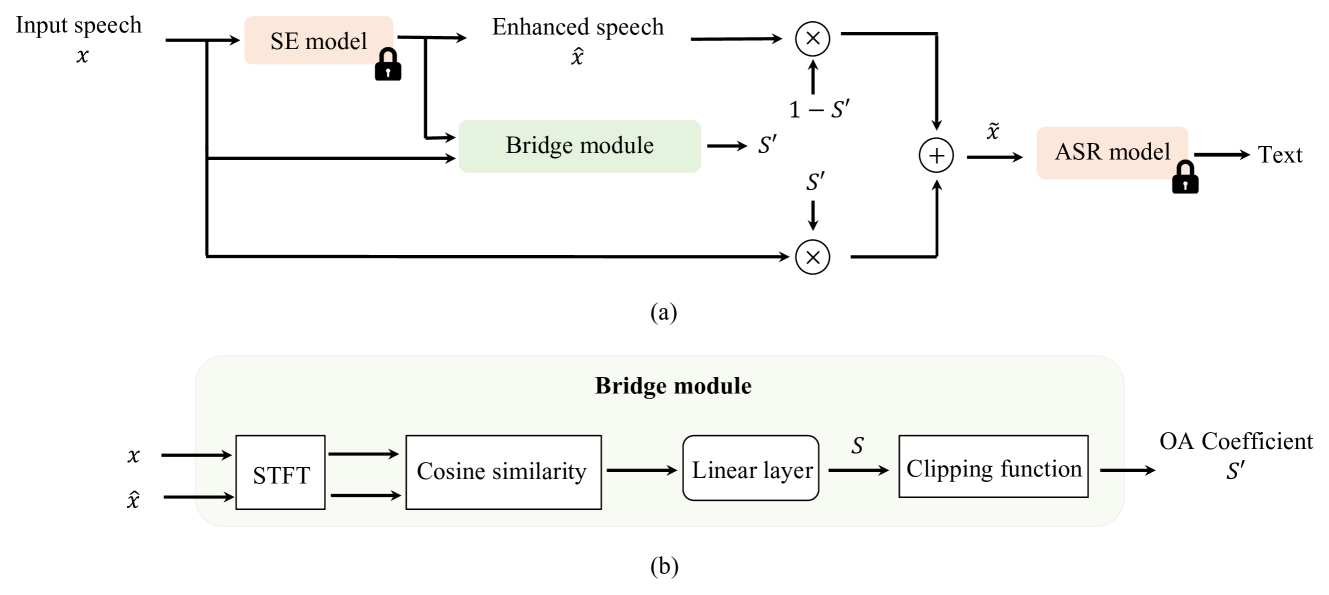
Noise robustness is critical when applying automatic speech recognition (ASR) in real-world scenarios. One solution involves the used of speech enhancement (SE) models as the front end of ASR. However, neural network-based (NN-based) SE often introduces artifacts into the enhanced signals and harms ASR performance, particularly when SE and ASR are independently trained. Therefore, this study introduces a simple yet effective SE post-processing technique to address the gap between various pre-trained SE and ASR models. A bridge module, which is a lightweight NN, is proposed to evaluate the signal-level information of the speech signal. Subsequently, using the signal-level information, the observation addition technique is applied to effectively reduce the shortcomings of SE. The experimental results demonstrate the success of our method in integrating diverse pre-trained SE and ASR models, considerably boosting the ASR robustness. Crucially, no prior knowledge of the ASR or speech contents is required during the training or inference stages. Moreover, the effectiveness of this approach extends to different datasets without necessitating the fine-tuning of the bridge module, ensuring efficiency and improved generalization.
Read more6/19/2024