Bridging the Novice-Expert Gap via Models of Decision-Making: A Case Study on Remediating Math Mistakes

0
🎲
Sign in to get full access
Overview
- The paper explores the potential of large language models (LLMs) to enhance the ability of novice tutors to remediate student mistakes in math.
- It introduces a method called Bridge that uses cognitive task analysis to translate an expert's thought process into a decision-making model for remediation.
- The researchers construct a dataset of 700 real tutoring conversations, annotated by experts with their decisions, and evaluate state-of-the-art LLMs on this dataset.
Plain English Explanation
The paper tackles the challenge of scaling high-quality tutoring in education. Often, platforms employ novice tutors who lack the expertise of experienced educators and struggle to effectively address student mistakes. This means they miss valuable learning opportunities.
The researchers explore how large language models can be used to bridge the knowledge gap between novice and expert tutors. They introduce a method called Bridge that analyzes how expert tutors think through the process of remediating student errors. This involves identifying the student's mistake, deciding on a remediation strategy, and considering the tutor's intent before crafting a response.
The researchers create a dataset of 700 real tutoring conversations, with experts annotating the decisions made at each step. They then evaluate how well state-of-the-art language models, like GPT-4, can use this expert decision-making model to generate better remediation responses.
The key finding is that incorporating the expert's thought process is critical for language models to close the gap between novice and expert tutors. Responses that leverage the expert's decisions on how to simplify the problem or provide context-sensitive guidance are significantly preferred over responses without this expert knowledge.
Technical Explanation
The paper explores the use of large language models to enhance the ability of novice tutors to remediate student mistakes in math. The researchers introduce a method called Bridge that uses cognitive task analysis to translate an expert's latent thought process into a decision-making model for remediation.
The Bridge method involves an expert identifying three key elements: (A) the student's error, (B) a remediation strategy, and (C) the tutor's intention before generating a response. The researchers then construct a dataset of 700 real tutoring conversations, with experts annotating these decisions.
They evaluate state-of-the-art language models, such as GPT-4, on this dataset and find that the expert's decision-making model is critical for the models to close the gap between novice and expert tutors. Responses from GPT-4 that incorporate the expert's decisions (e.g., simplifying the problem) are 76% more preferred than responses without this expert knowledge.
Additionally, the paper highlights the importance of context-sensitive decisions. Random decisions made by the language model decrease the quality of its responses by 97% compared to the expert's context-sensitive decisions.
Critical Analysis
The paper presents a promising approach to leveraging large language models to enhance the tutoring capabilities of novice educators. By embedding expert thought processes into the language model's decision-making, the researchers demonstrate significant improvements in the quality of generated remediation responses.
However, one potential limitation is the reliance on a curated dataset of 700 tutoring conversations. While this provides a valuable starting point, the model's performance may be sensitive to the specific characteristics of this dataset. Further research could explore the model's generalization to a wider range of tutoring scenarios and student populations.
Additionally, the paper does not address potential biases or ethical considerations that may arise from using language models for educational purposes. As these models become more prevalent in educational settings, it will be crucial to carefully examine their impact on student learning and ensure they do not perpetuate harmful biases or inequities.
Overall, the work presented in this paper offers a compelling approach to bridging the gap between novice and expert tutors, with promising implications for scaling high-quality educational support. As the field of large language models continues to evolve, further research and rigorous testing will be essential to realize the full potential of this technology in the educational domain.
Conclusion
This paper explores a novel approach to leveraging large language models to enhance the tutoring capabilities of novice educators. By translating an expert's thought process into a decision-making model for remediation, the researchers demonstrate significant improvements in the quality of language model-generated responses to student mistakes.
The key findings suggest that incorporating expert knowledge is critical for language models to bridge the gap between novice and experienced tutors. Additionally, the importance of context-sensitive decision-making highlights the nuanced nature of effective educational support.
While further research is needed to address potential limitations and ethical considerations, this work offers a promising path forward for scaling high-quality tutoring and improving learning outcomes for students.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎲
0
Bridging the Novice-Expert Gap via Models of Decision-Making: A Case Study on Remediating Math Mistakes
Rose E. Wang, Qingyang Zhang, Carly Robinson, Susanna Loeb, Dorottya Demszky
Scaling high-quality tutoring remains a major challenge in education. Due to growing demand, many platforms employ novice tutors who, unlike experienced educators, struggle to address student mistakes and thus fail to seize prime learning opportunities. Our work explores the potential of large language models (LLMs) to close the novice-expert knowledge gap in remediating math mistakes. We contribute Bridge, a method that uses cognitive task analysis to translate an expert's latent thought process into a decision-making model for remediation. This involves an expert identifying (A) the student's error, (B) a remediation strategy, and (C) their intention before generating a response. We construct a dataset of 700 real tutoring conversations, annotated by experts with their decisions. We evaluate state-of-the-art LLMs on our dataset and find that the expert's decision-making model is critical for LLMs to close the gap: responses from GPT4 with expert decisions (e.g., simplify the problem) are +76% more preferred than without. Additionally, context-sensitive decisions are critical to closing pedagogical gaps: random decisions decrease GPT4's response quality by -97% than expert decisions. Our work shows the potential of embedding expert thought processes in LLM generations to enhance their capability to bridge novice-expert knowledge gaps. Our dataset and code can be found at: url{https://github.com/rosewang2008/bridge}.
Read more4/9/2024
0
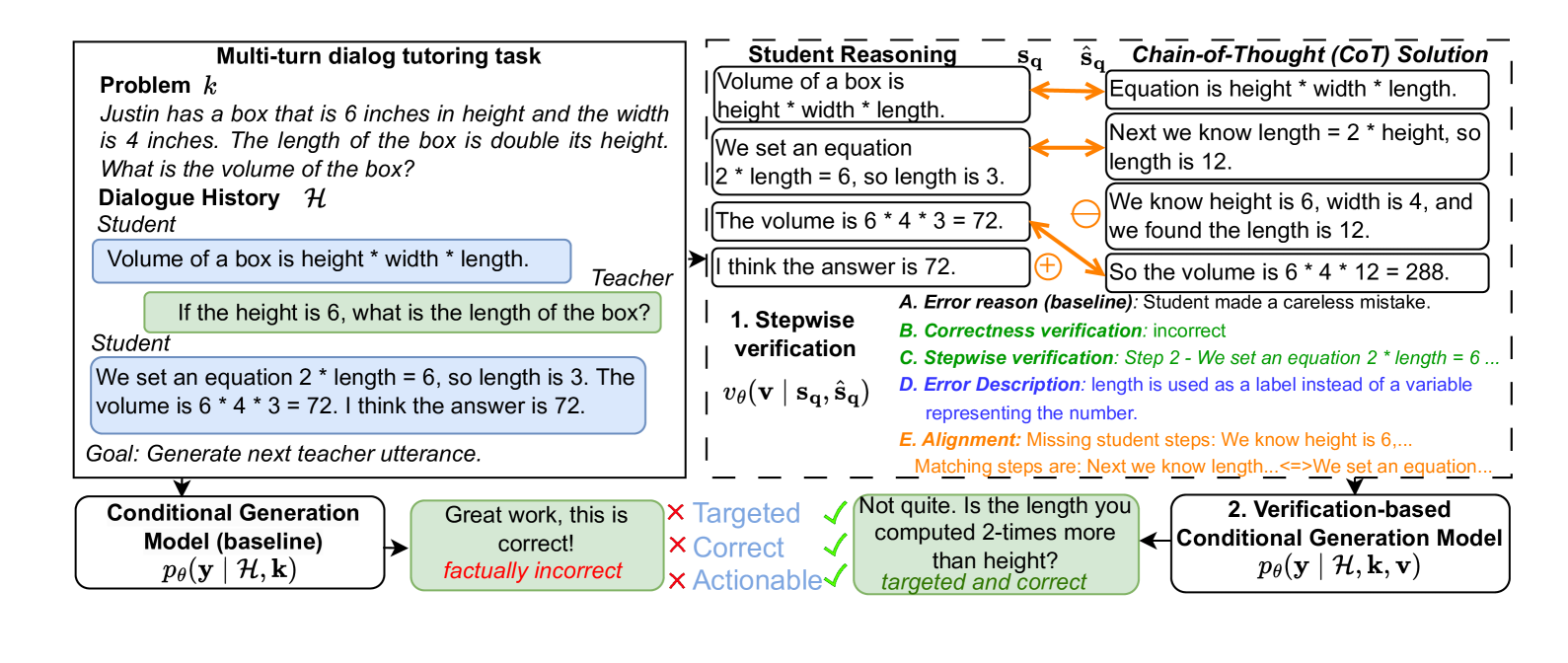
Stepwise Verification and Remediation of Student Reasoning Errors with Large Language Model Tutors
Nico Daheim, Jakub Macina, Manu Kapur, Iryna Gurevych, Mrinmaya Sachan
Large language models (LLMs) present an opportunity to scale high-quality personalized education to all. A promising approach towards this means is to build dialog tutoring models that scaffold students' problem-solving. However, even though existing LLMs perform well in solving reasoning questions, they struggle to precisely detect student's errors and tailor their feedback to these errors. Inspired by real-world teaching practice where teachers identify student errors and customize their response based on them, we focus on verifying student solutions and show how grounding to such verification improves the overall quality of tutor response generation. We collect a dataset of 1K stepwise math reasoning chains with the first error step annotated by teachers. We show empirically that finding the mistake in a student solution is challenging for current models. We propose and evaluate several verifiers for detecting these errors. Using both automatic and human evaluation we show that the student solution verifiers steer the generation model towards highly targeted responses to student errors which are more often correct with less hallucinations compared to existing baselines.
Read more7/15/2024

0
AutoTutor meets Large Language Models: A Language Model Tutor with Rich Pedagogy and Guardrails
Sankalan Pal Chowdhury, Vil'em Zouhar, Mrinmaya Sachan
Large Language Models (LLMs) have found several use cases in education, ranging from automatic question generation to essay evaluation. In this paper, we explore the potential of using Large Language Models (LLMs) to author Intelligent Tutoring Systems. A common pitfall of LLMs is their straying from desired pedagogical strategies such as leaking the answer to the student, and in general, providing no guarantees. We posit that while LLMs with certain guardrails can take the place of subject experts, the overall pedagogical design still needs to be handcrafted for the best learning results. Based on this principle, we create a sample end-to-end tutoring system named MWPTutor, which uses LLMs to fill in the state space of a pre-defined finite state transducer. This approach retains the structure and the pedagogy of traditional tutoring systems that has been developed over the years by learning scientists but brings in additional flexibility of LLM-based approaches. Through a human evaluation study on two datasets based on math word problems, we show that our hybrid approach achieves a better overall tutoring score than an instructed, but otherwise free-form, GPT-4. MWPTutor is completely modular and opens up the scope for the community to improve its performance by improving individual modules or using different teaching strategies that it can follow.
Read more4/26/2024
0
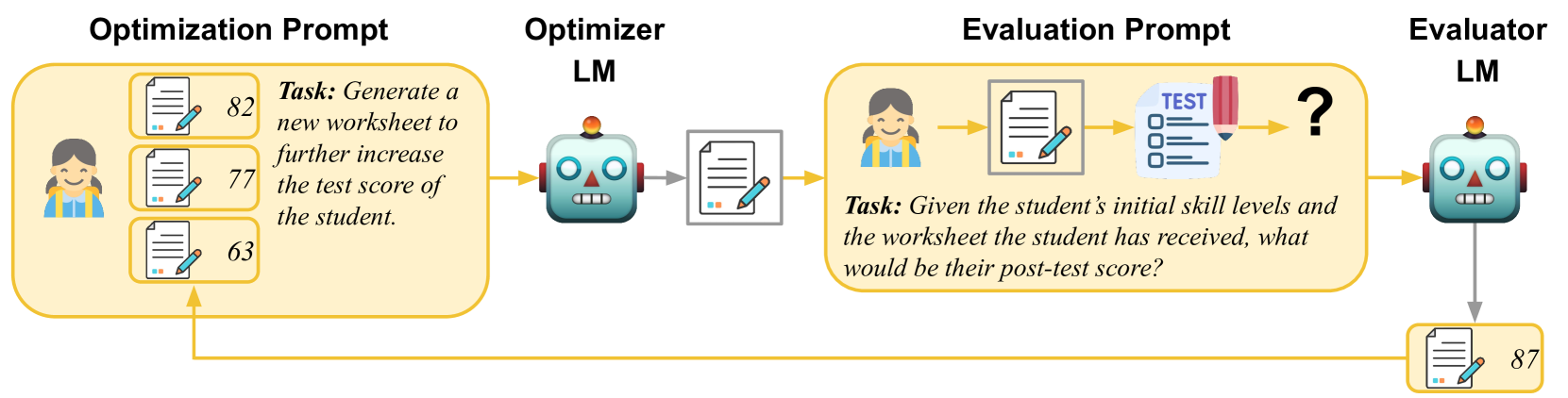
Evaluating and Optimizing Educational Content with Large Language Model Judgments
Joy He-Yueya, Noah D. Goodman, Emma Brunskill
Creating effective educational materials generally requires expensive and time-consuming studies of student learning outcomes. To overcome this barrier, one idea is to build computational models of student learning and use them to optimize instructional materials. However, it is difficult to model the cognitive processes of learning dynamics. We propose an alternative approach that uses Language Models (LMs) as educational experts to assess the impact of various instructions on learning outcomes. Specifically, we use GPT-3.5 to evaluate the overall effect of instructional materials on different student groups and find that it can replicate well-established educational findings such as the Expertise Reversal Effect and the Variability Effect. This demonstrates the potential of LMs as reliable evaluators of educational content. Building on this insight, we introduce an instruction optimization approach in which one LM generates instructional materials using the judgments of another LM as a reward function. We apply this approach to create math word problem worksheets aimed at maximizing student learning gains. Human teachers' evaluations of these LM-generated worksheets show a significant alignment between the LM judgments and human teacher preferences. We conclude by discussing potential divergences between human and LM opinions and the resulting pitfalls of automating instructional design.
Read more5/7/2024