THE COLOSSEUM: A Benchmark for Evaluating Generalization for Robotic Manipulation

0
Sign in to get full access
Related Work
Robotic Manipulation
Researchers have made significant progress in developing robotic manipulation capabilities through a variety of approaches. Some key related works include:
- Evaluating Real-World Robot Manipulation Policies in Simulation: This work explores techniques for transferring manipulation policies learned in simulation to the real world.
- Learning Manipulation Tasks in Dynamic Shared 3D Spaces: This research focuses on enabling robots to learn manipulation skills in complex, dynamic environments shared with humans.
- Investigating Generalizability of Assistive Robot Models Over Various Environments and Tasks: This study examines how well robotic manipulation models can generalize across different environments and tasks.
- Efficient Data Collection for Robotic Manipulation via Compositional Task Decomposition: This work explores techniques for more efficiently collecting training data for robotic manipulation tasks.
- ManifoundATION: A Model for General-Purpose Robotic Manipulation with Contact: This model aims to enable robots to perform a wide range of manipulation tasks involving contact with the environment.
These and other related studies have made important advancements in robotic manipulation, but there is still significant room for improvement, particularly in the area of generalization to novel tasks and environments.
Plain English Explanation
The paper presents a new benchmark called "The Colosseum" for evaluating how well robotic manipulation systems can generalize to novel tasks and environments. Generalization is a key challenge in robotics, as we want robots to be able to adapt and apply their skills flexibly, rather than being limited to specific, pre-programmed behaviors.
The Colosseum benchmark consists of a diverse set of manipulation tasks, ranging from simple object grasping to more complex assembly and disassembly. Importantly, these tasks are designed to become progressively more difficult, with changes in the object properties, environmental conditions, and task requirements. This allows researchers to rigorously test how well their manipulation models can adapt and perform across a wide range of scenarios.
By providing a standardized platform for evaluation, the Colosseum benchmark aims to drive progress in the field of robotic manipulation. Researchers can use it to identify the strengths and weaknesses of their approaches, compare their results to others, and ultimately develop more capable and flexible manipulation systems. This could have significant implications for a variety of real-world applications, from manufacturing and logistics to assistive robotics and beyond.
Technical Explanation
The paper introduces a new benchmark called "The Colosseum" for evaluating the generalization capabilities of robotic manipulation systems. The Colosseum consists of a diverse set of manipulation tasks, including object grasping, assembly, and disassembly, which become progressively more challenging in terms of object properties, environmental conditions, and task requirements.
The authors designed the Colosseum to address the key challenge of generalization in robotic manipulation. Existing benchmarks often focus on specific, pre-programmed tasks, which can limit the ability of manipulation models to adapt to novel scenarios. In contrast, the Colosseum is designed to test how well these models can transfer their skills across a wide range of manipulation challenges.
To create the Colosseum, the authors drew inspiration from the Roman Colosseum and its gladiatorial battles, with the manipulation tasks representing different "arenas" that robots must overcome. The benchmark includes a total of 16 arenas, each with its own unique set of objects, environments, and task requirements. These arenas are organized into four difficulty levels, allowing researchers to systematically evaluate the generalization capabilities of their manipulation models.
The authors also provide a suite of evaluation metrics to assess the performance of robotic manipulation systems on the Colosseum benchmark. These metrics capture various aspects of task completion, such as success rate, efficiency, and safety. By using these standardized metrics, researchers can compare the performance of different models and identify areas for improvement.
To demonstrate the utility of the Colosseum, the authors present baseline results using several state-of-the-art robotic manipulation algorithms. Their findings reveal that even the best-performing models struggle to maintain high levels of performance across the increasingly challenging arenas, highlighting the need for more robust and generalizable manipulation capabilities.
Critical Analysis
The Colosseum benchmark represents a significant advancement in the field of robotic manipulation by providing a standardized platform for evaluating generalization capabilities. The authors have thoughtfully designed the benchmark to capture a diverse range of manipulation challenges, allowing researchers to rigorously test the performance and adaptability of their models.
One potential limitation of the Colosseum is the limited number of arenas (16) compared to the vast number of possible manipulation scenarios in the real world. While the arenas are designed to span a wide range of difficulty levels, there may be additional edge cases or novel situations that are not adequately represented. The authors acknowledge this limitation and suggest that the Colosseum could be expanded or supplemented with additional environments in the future.
Another area for further investigation is the impact of different learning approaches on the generalization performance of robotic manipulation systems. The baseline results presented in the paper suggest that even state-of-the-art models struggle to maintain high levels of performance across the Colosseum arenas. Exploring alternative learning strategies, such as Manifoundation: A Model for General-Purpose Robotic Manipulation with Contact, may lead to more robust and adaptable manipulation capabilities.
Overall, the Colosseum benchmark represents a valuable contribution to the field of robotic manipulation, providing a standardized platform for evaluating generalization and driving progress towards more versatile and capable robotic systems. As researchers continue to explore and refine their approaches, the Colosseum can serve as an important tool for accelerating the development of robotic manipulation technologies with real-world impact.
Conclusion
The Colosseum benchmark introduced in this paper represents a significant advancement in the field of robotic manipulation. By providing a standardized platform for evaluating the generalization capabilities of manipulation models, the Colosseum aims to drive progress towards more robust and adaptable robotic systems.
The diverse set of manipulation tasks, organized into increasingly challenging arenas, allows researchers to systematically test the performance of their models across a wide range of scenarios. This is a crucial step in addressing the key challenge of generalization, which is essential for enabling robots to flexibly apply their skills in real-world environments.
The Colosseum benchmark, along with the provided evaluation metrics, offers a valuable tool for the research community to compare results, identify areas for improvement, and develop more capable manipulation algorithms. As the field continues to evolve, the Colosseum can serve as a catalyst for accelerating the development of robotic technologies with significant implications for manufacturing, logistics, assistive robotics, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
THE COLOSSEUM: A Benchmark for Evaluating Generalization for Robotic Manipulation
Wilbert Pumacay, Ishika Singh, Jiafei Duan, Ranjay Krishna, Jesse Thomason, Dieter Fox
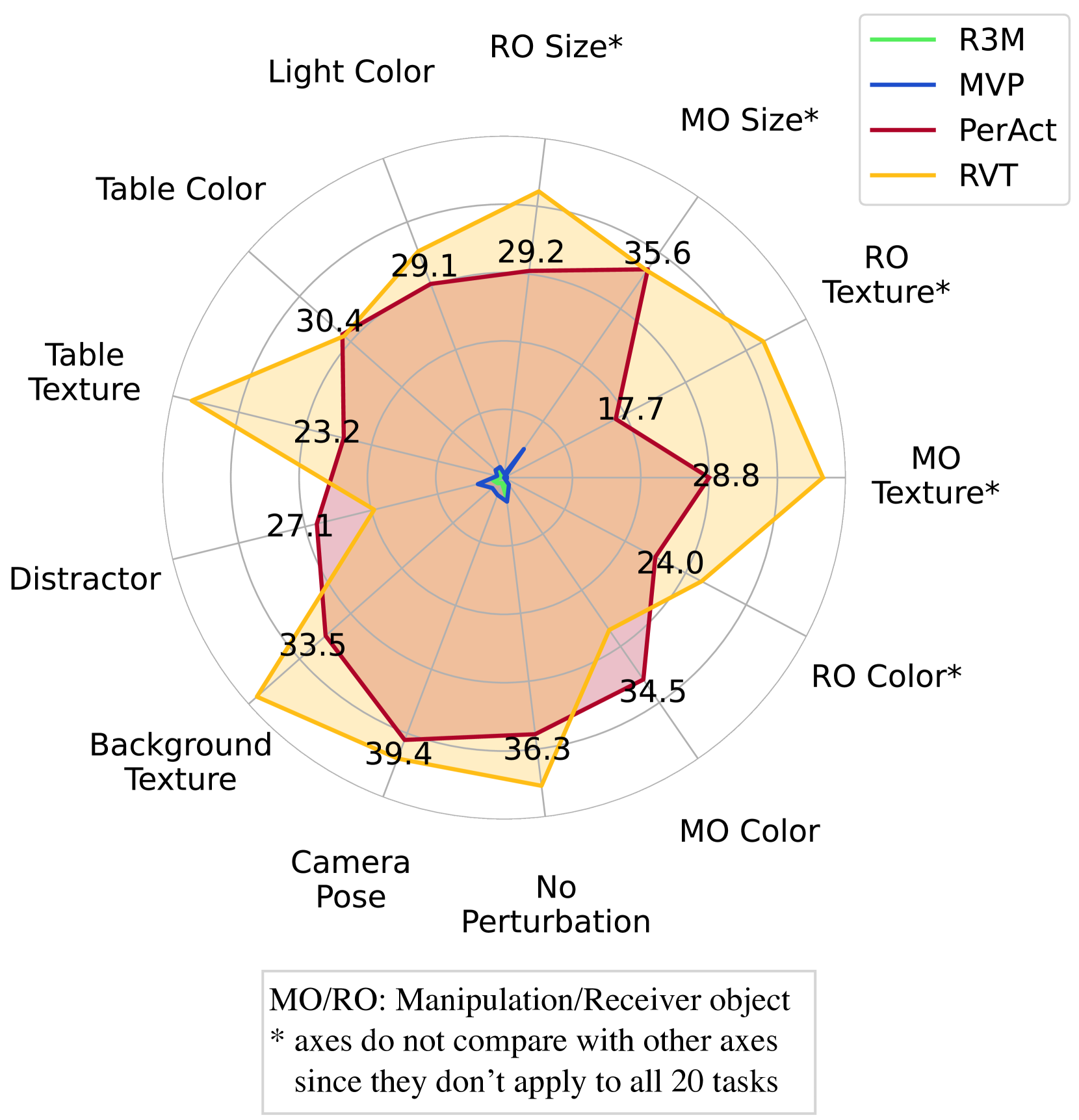
To realize effective large-scale, real-world robotic applications, we must evaluate how well our robot policies adapt to changes in environmental conditions. Unfortunately, a majority of studies evaluate robot performance in environments closely resembling or even identical to the training setup. We present THE COLOSSEUM, a novel simulation benchmark, with 20 diverse manipulation tasks, that enables systematical evaluation of models across 14 axes of environmental perturbations. These perturbations include changes in color, texture, and size of objects, table-tops, and backgrounds; we also vary lighting, distractors, physical properties perturbations and camera pose. Using THE COLOSSEUM, we compare 5 state-of-the-art manipulation models to reveal that their success rate degrades between 30-50% across these perturbation factors. When multiple perturbations are applied in unison, the success rate degrades $geq$75%. We identify that changing the number of distractor objects, target object color, or lighting conditions are the perturbations that reduce model performance the most. To verify the ecological validity of our results, we show that our results in simulation are correlated ($bar{R}^2 = 0.614$) to similar perturbations in real-world experiments. We open source code for others to use THE COLOSSEUM, and also release code to 3D print the objects used to replicate the real-world perturbations. Ultimately, we hope that THE COLOSSEUM will serve as a benchmark to identify modeling decisions that systematically improve generalization for manipulation. See https://robot-colosseum.github.io/ for more details.
Read more5/29/2024

0
RoboCAS: A Benchmark for Robotic Manipulation in Complex Object Arrangement Scenarios
Liming Zheng, Feng Yan, Fanfan Liu, Chengjian Feng, Zhuoliang Kang, Lin Ma
Foundation models hold significant potential for enabling robots to perform long-horizon general manipulation tasks. However, the simplicity of tasks and the uniformity of environments in existing benchmarks restrict their effective deployment in complex scenarios. To address this limitation, this paper introduces the textit{RoboCAS} benchmark, the first benchmark specifically designed for complex object arrangement scenarios in robotic manipulation. This benchmark employs flexible and concise scripted policies to efficiently collect a diverse array of demonstrations, showcasing scattered, orderly, and stacked object arrangements within a highly realistic physical simulation environment. It includes complex processes such as target retrieval, obstacle clearance, and robot manipulation, testing agents' abilities to perform long-horizon planning for spatial reasoning and predicting chain reactions under ambiguous instructions. Extensive experiments on multiple baseline models reveal their limitations in managing complex object arrangement scenarios, underscoring the urgent need for intelligent agents capable of performing long-horizon operations in practical deployments and providing valuable insights for future research directions. Project website: url{https://github.com/notFoundThisPerson/RoboCAS-v0}.
Read more7/10/2024
👨🏫
0
Evaluating Real-World Robot Manipulation Policies in Simulation
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, Sergey Levine, Jiajun Wu, Chelsea Finn, Hao Su, Quan Vuong, Ted Xiao
The field of robotics has made significant advances towards generalist robot manipulation policies. However, real-world evaluation of such policies is not scalable and faces reproducibility challenges, which are likely to worsen as policies broaden the spectrum of tasks they can perform. We identify control and visual disparities between real and simulated environments as key challenges for reliable simulated evaluation and propose approaches for mitigating these gaps without needing to craft full-fidelity digital twins of real-world environments. We then employ these approaches to create SIMPLER, a collection of simulated environments for manipulation policy evaluation on common real robot setups. Through paired sim-and-real evaluations of manipulation policies, we demonstrate strong correlation between policy performance in SIMPLER environments and in the real world. Additionally, we find that SIMPLER evaluations accurately reflect real-world policy behavior modes such as sensitivity to various distribution shifts. We open-source all SIMPLER environments along with our workflow for creating new environments at https://simpler-env.github.io to facilitate research on general-purpose manipulation policies and simulated evaluation frameworks.
Read more5/10/2024

0
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, Yuke Zhu
Recent advancements in Artificial Intelligence (AI) have largely been propelled by scaling. In Robotics, scaling is hindered by the lack of access to massive robot datasets. We advocate using realistic physical simulation as a means to scale environments, tasks, and datasets for robot learning methods. We present RoboCasa, a large-scale simulation framework for training generalist robots in everyday environments. RoboCasa features realistic and diverse scenes focusing on kitchen environments. We provide thousands of 3D assets across over 150 object categories and dozens of interactable furniture and appliances. We enrich the realism and diversity of our simulation with generative AI tools, such as object assets from text-to-3D models and environment textures from text-to-image models. We design a set of 100 tasks for systematic evaluation, including composite tasks generated by the guidance of large language models. To facilitate learning, we provide high-quality human demonstrations and integrate automated trajectory generation methods to substantially enlarge our datasets with minimal human burden. Our experiments show a clear scaling trend in using synthetically generated robot data for large-scale imitation learning and show great promise in harnessing simulation data in real-world tasks. Videos and open-source code are available at https://robocasa.ai/
Read more6/5/2024