Compositional Conservatism: A Transductive Approach in Offline Reinforcement Learning

0

Sign in to get full access
Overview
- This paper introduces a new approach called "Compositional Conservatism" for offline reinforcement learning (RL) tasks.
- The method aims to improve the sample efficiency and stability of offline RL by leveraging a transductive learning framework.
- Key innovations include a novel compositional reward model and a transductive policy optimization procedure.
Plain English Explanation
Reinforcement learning (RL) is a powerful technique for training AI agents to perform complex tasks by rewarding desired behaviors. However, traditional RL requires a lot of data collected through extensive real-world experimentation, which can be costly and time-consuming.
Offline RL addresses this issue by learning from pre-collected datasets, rather than interacting with the environment directly. This allows the agent to be trained without additional data collection. However, offline RL can be challenging due to the limited and potentially biased nature of the training data.
The "Compositional Conservatism" approach introduced in this paper aims to make offline RL more efficient and stable. The key idea is to decompose the reward function into multiple components, and then use a transductive learning framework to optimize the policy. This allows the agent to leverage the structure of the reward function and make more effective use of the available data.
The authors demonstrate the effectiveness of their method on several challenging continuous control tasks, showing improved sample efficiency and stability compared to other leading offline RL algorithms. This work represents an important step forward in making RL more practical and applicable to real-world problems where extensive data collection is infeasible.
Technical Explanation
The paper proposes a new offline RL algorithm called "Compositional Conservatism" that leverages a transductive learning framework. The core idea is to decompose the reward function into multiple components, and then optimize the policy using a transductive approach that takes advantage of the structure of the reward function.
Specifically, the method includes the following key elements:
-
Compositional Reward Model: The reward function is represented as a linear combination of multiple reward components, each capturing a different aspect of the desired behavior. This allows the agent to learn more efficiently by focusing on the relevant sub-tasks.
-
Transductive Policy Optimization: Instead of the standard inductive approach used in many offline RL algorithms, Compositional Conservatism employs a transductive framework. This means the policy is optimized directly on the evaluation environment, without the need for explicit generalization to unseen states.
-
Regularization and Constraint: The policy optimization process is regularized to encourage conservative behavior, ensuring the agent stays close to the observed data distribution. This helps mitigate the challenge of distributional shift in offline RL.
The authors evaluate their method on several continuous control tasks and demonstrate significant improvements in sample efficiency and stability compared to state-of-the-art offline RL algorithms, such as Solving Continual Offline Reinforcement Learning, Trajectory-wise Iterative Reinforcement Learning Framework, and Bayesian Approach to Robust Inverse Reinforcement Learning.
Critical Analysis
The Compositional Conservatism approach represents an innovative and promising direction for offline RL, but it also has some potential limitations and areas for further research:
-
Reward Function Decomposition: The performance of the method relies on the ability to decompose the reward function into meaningful components. In practice, this may not always be straightforward, and the choice of reward components could significantly impact the algorithm's performance.
-
Generalization Capabilities: While the transductive optimization approach may improve sample efficiency, it is unclear how well the learned policies would generalize to unseen states or environments. Further investigation is needed to understand the trade-offs between transductive and inductive learning in offline RL.
-
Scalability and Computational Complexity: The proposed method involves solving multiple optimization problems, which could potentially be computationally intensive, especially as the problem complexity or the number of reward components increases. Investigating more efficient optimization techniques would be a valuable direction for future research.
-
Robustness to Noise and Outliers: The paper does not explicitly address the algorithm's sensitivity to noisy or low-quality data, which is a common challenge in offline RL. Exploring techniques to make Compositional Conservatism more robust to such issues would be an important area for further development.
Overall, the Compositional Conservatism approach is a promising step forward in addressing the challenges of offline RL, and the authors have made a valuable contribution to the field. However, as with any new technique, there are opportunities for continued refinement and further exploration to fully unlock its potential.
Conclusion
This paper introduces a new offline reinforcement learning algorithm called "Compositional Conservatism" that leverages a transductive learning framework to improve sample efficiency and stability. The key innovations include a compositional reward model and a transductive policy optimization procedure, which allow the agent to make more effective use of the available offline data.
The authors demonstrate the effectiveness of their method on several challenging continuous control tasks, showing significant improvements over other leading offline RL algorithms. This work represents an important advancement in making reinforcement learning more practical and applicable to real-world problems where extensive data collection is infeasible.
While the Compositional Conservatism approach shows promise, there are also several areas for further research and refinement, such as the scalability of the method, its generalization capabilities, and its robustness to noisy or biased data. Addressing these challenges could lead to even more powerful and versatile offline RL algorithms in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Compositional Conservatism: A Transductive Approach in Offline Reinforcement Learning
Yeda Song, Dongwook Lee, Gunhee Kim
Offline reinforcement learning (RL) is a compelling framework for learning optimal policies from past experiences without additional interaction with the environment. Nevertheless, offline RL inevitably faces the problem of distributional shifts, where the states and actions encountered during policy execution may not be in the training dataset distribution. A common solution involves incorporating conservatism into the policy or the value function to safeguard against uncertainties and unknowns. In this work, we focus on achieving the same objectives of conservatism but from a different perspective. We propose COmpositional COnservatism with Anchor-seeking (COCOA) for offline RL, an approach that pursues conservatism in a compositional manner on top of the transductive reparameterization (Netanyahu et al., 2023), which decomposes the input variable (the state in our case) into an anchor and its difference from the original input. Our COCOA seeks both in-distribution anchors and differences by utilizing the learned reverse dynamics model, encouraging conservatism in the compositional input space for the policy or value function. Such compositional conservatism is independent of and agnostic to the prevalent behavioral conservatism in offline RL. We apply COCOA to four state-of-the-art offline RL algorithms and evaluate them on the D4RL benchmark, where COCOA generally improves the performance of each algorithm. The code is available at https://github.com/runamu/compositional-conservatism.
Read more4/9/2024

0
Strategically Conservative Q-Learning
Yutaka Shimizu, Joey Hong, Sergey Levine, Masayoshi Tomizuka
Offline reinforcement learning (RL) is a compelling paradigm to extend RL's practical utility by leveraging pre-collected, static datasets, thereby avoiding the limitations associated with collecting online interactions. The major difficulty in offline RL is mitigating the impact of approximation errors when encountering out-of-distribution (OOD) actions; doing so ineffectively will lead to policies that prefer OOD actions, which can lead to unexpected and potentially catastrophic results. Despite the variety of works proposed to address this issue, they tend to excessively suppress the value function in and around OOD regions, resulting in overly pessimistic value estimates. In this paper, we propose a novel framework called Strategically Conservative Q-Learning (SCQ) that distinguishes between OOD data that is easy and hard to estimate, ultimately resulting in less conservative value estimates. Our approach exploits the inherent strengths of neural networks to interpolate, while carefully navigating their limitations in extrapolation, to obtain pessimistic yet still property calibrated value estimates. Theoretical analysis also shows that the value function learned by SCQ is still conservative, but potentially much less so than that of Conservative Q-learning (CQL). Finally, extensive evaluation on the D4RL benchmark tasks shows our proposed method outperforms state-of-the-art methods. Our code is available through url{https://github.com/purewater0901/SCQ}.
Read more6/10/2024

0
Sparsity-based Safety Conservatism for Constrained Offline Reinforcement Learning
Minjae Cho, Chuangchuang Sun
Reinforcement Learning (RL) has made notable success in decision-making fields like autonomous driving and robotic manipulation. Yet, its reliance on real-time feedback poses challenges in costly or hazardous settings. Furthermore, RL's training approach, centered on on-policy sampling, doesn't fully capitalize on data. Hence, Offline RL has emerged as a compelling alternative, particularly in conducting additional experiments is impractical, and abundant datasets are available. However, the challenge of distributional shift (extrapolation), indicating the disparity between data distributions and learning policies, also poses a risk in offline RL, potentially leading to significant safety breaches due to estimation errors (interpolation). This concern is particularly pronounced in safety-critical domains, where real-world problems are prevalent. To address both extrapolation and interpolation errors, numerous studies have introduced additional constraints to confine policy behavior, steering it towards more cautious decision-making. While many studies have addressed extrapolation errors, fewer have focused on providing effective solutions for tackling interpolation errors. For example, some works tackle this issue by incorporating potential cost-maximizing optimization by perturbing the original dataset. However, this, involving a bi-level optimization structure, may introduce significant instability or complicate problem-solving in high-dimensional tasks. This motivates us to pinpoint areas where hazards may be more prevalent than initially estimated based on the sparsity of available data by providing significant insight into constrained offline RL. In this paper, we present conservative metrics based on data sparsity that demonstrate the high generalizability to any methods and efficacy compared to using bi-level cost-ub-maximization.
Read more7/19/2024
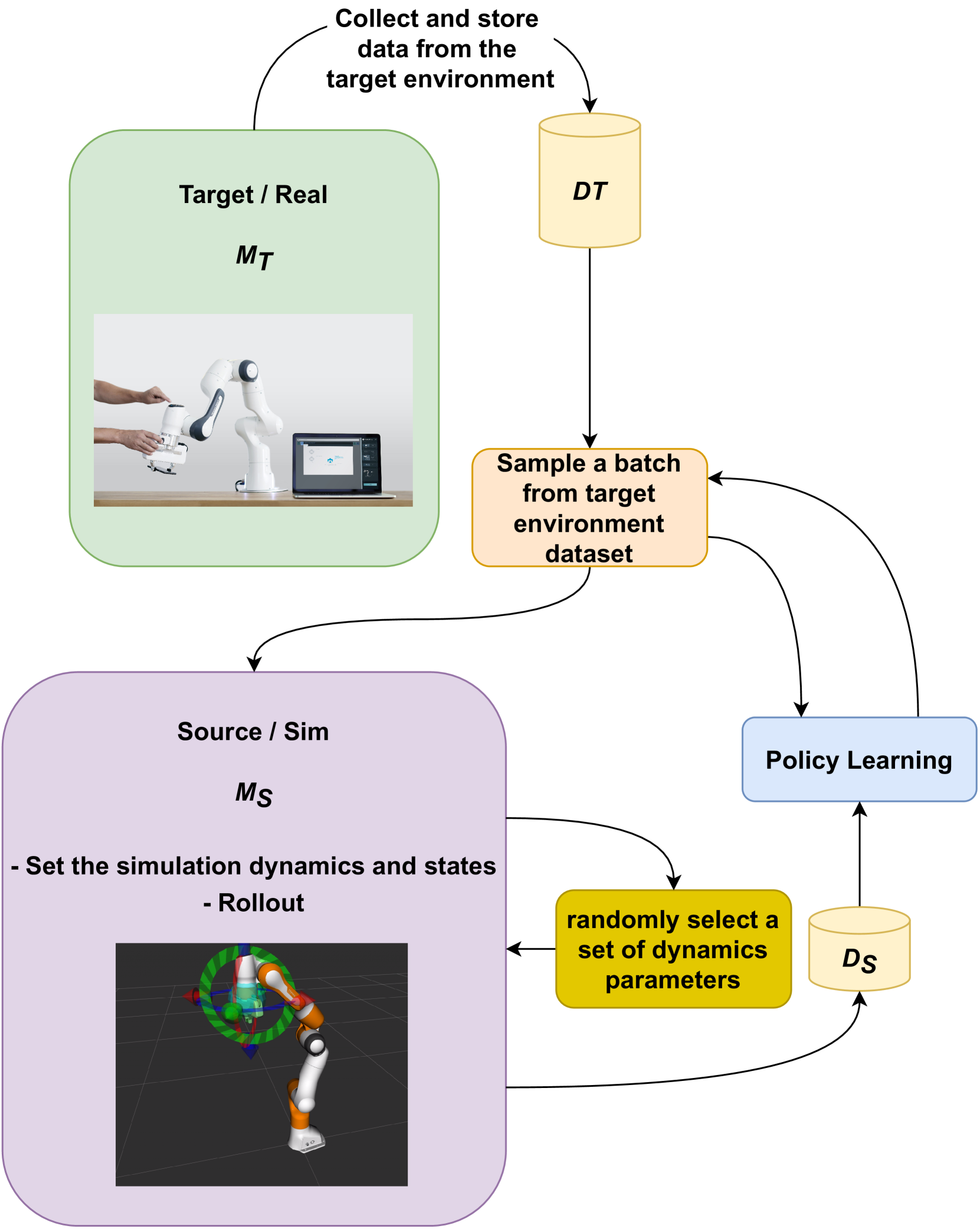
0
COSBO: Conservative Offline Simulation-Based Policy Optimization
Eshagh Kargar, Ville Kyrki
Offline reinforcement learning allows training reinforcement learning models on data from live deployments. However, it is limited to choosing the best combination of behaviors present in the training data. In contrast, simulation environments attempting to replicate the live environment can be used instead of the live data, yet this approach is limited by the simulation-to-reality gap, resulting in a bias. In an attempt to get the best of both worlds, we propose a method that combines an imperfect simulation environment with data from the target environment, to train an offline reinforcement learning policy. Our experiments demonstrate that the proposed method outperforms state-of-the-art approaches CQL, MOPO, and COMBO, especially in scenarios with diverse and challenging dynamics, and demonstrates robust behavior across a variety of experimental conditions. The results highlight that using simulator-generated data can effectively enhance offline policy learning despite the sim-to-real gap, when direct interaction with the real-world is not possible.
Read more9/24/2024