Computational Tradeoffs in Image Synthesis: Diffusion, Masked-Token, and Next-Token Prediction
2405.13218
0
0
🖼️
Abstract
Nearly every recent image synthesis approach, including diffusion, masked-token prediction, and next-token prediction, uses a Transformer network architecture. Despite this common backbone, there has been no direct, compute controlled comparison of how these approaches affect performance and efficiency. We analyze the scalability of each approach through the lens of compute budget measured in FLOPs. We find that token prediction methods, led by next-token prediction, significantly outperform diffusion on prompt following. On image quality, while next-token prediction initially performs better, scaling trends suggest it is eventually matched by diffusion. We compare the inference compute efficiency of each approach and find that next token prediction is by far the most efficient. Based on our findings we recommend diffusion for applications targeting image quality and low latency; and next-token prediction when prompt following or throughput is more important.
Create account to get full access
Overview
- Recent image synthesis approaches, including diffusion, masked-token prediction, and next-token prediction, all use Transformer network architecture.
- This paper provides a direct, compute-controlled comparison of how these approaches affect performance and efficiency.
- The researchers analyze the scalability of each approach based on compute budget measured in FLOPs (Floating-Point Operations).
Plain English Explanation
The paper compares the effectiveness and efficiency of three different techniques for generating images using deep learning models: diffusion, masked-token prediction, and next-token prediction.
All of these approaches use a similar underlying neural network architecture called a Transformer, but the researchers wanted to understand how the specific technique used affects the model's performance and efficiency. They looked at how well each approach can follow prompts (i.e., match the desired image) and the quality of the generated images, as well as how computationally efficient each one is during inference (i.e., when generating new images).
The key findings are:
- Next-token prediction outperforms diffusion on prompt following, meaning it does a better job of generating images that match the desired description.
- While next-token prediction initially produces higher quality images, the quality of diffusion models eventually catches up as the models are scaled up.
- Next-token prediction is by far the most computationally efficient of the three approaches, requiring much less computing power to generate new images.
Based on these results, the researchers recommend using diffusion models when image quality and low latency are priorities, and next-token prediction when prompt following or high throughput is more important.
Technical Explanation
The researchers analyzed the scalability and efficiency of three common image synthesis approaches - diffusion, masked-token prediction, and next-token prediction - all of which utilize Transformer network architectures.
To assess scalability, they evaluated the models' performance on prompt following and image quality as a function of their compute budget, measured in FLOPs (Floating-Point Operations). They found that token prediction methods, led by next-token prediction, significantly outperformed diffusion on prompt following. However, while next-token prediction initially produced higher quality images, the quality of diffusion models eventually matched it as the models were scaled up.
The researchers also compared the inference compute efficiency of each approach. They determined that next-token prediction was by far the most efficient, requiring much less computational power to generate new images compared to the other two methods.
Based on these findings, the researchers recommend using diffusion models in applications where image quality and low latency are priorities, and next-token prediction when prompt following or high throughput is more important.
Critical Analysis
The paper provides a valuable, rigorous comparison of three prominent image synthesis techniques. By controlling for compute budget and analyzing both performance and efficiency, the researchers offer compelling insights to guide the selection of appropriate models for different applications.
That said, the paper does not explore some potential limitations or caveats of the research. For example, the analysis is focused solely on FLOPs as the measure of computational cost, which may not fully capture real-world performance on various hardware platforms. Additionally, the researchers note that their findings are specific to the particular model architectures and training regimes they evaluated, and that further research is needed to understand how the techniques scale and perform under different conditions.
It would also be helpful to see the researchers engage more critically with the tradeoffs and potential downsides of the various approaches. For instance, while next-token prediction may be the most computationally efficient, there could be concerns around its robustness, safety, or understanding of the underlying semantics compared to diffusion models.
Overall, this is a well-designed and insightful study that provides a useful framework for evaluating and selecting image synthesis techniques. However, further research and analysis would be valuable to more fully understand the strengths, weaknesses, and appropriate use cases of these approaches.
Conclusion
This paper presents a comprehensive comparison of three prominent image synthesis techniques - diffusion, masked-token prediction, and next-token prediction - all of which leverage Transformer network architectures. By analyzing the scalability and efficiency of these approaches, the researchers offer valuable guidance for selecting the right model depending on the priorities of the application.
The key takeaways are:
- Next-token prediction outperforms diffusion on prompt following, but the image quality of diffusion models eventually catches up as the models are scaled up.
- Next-token prediction is the most computationally efficient of the three approaches, requiring significantly less computing power to generate new images.
Based on these findings, the researchers recommend using diffusion models when image quality and low latency are priorities, and next-token prediction when prompt following or high throughput is more important. This research provides a helpful framework for developers and researchers to make informed choices when designing image synthesis systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

An Image is Worth 32 Tokens for Reconstruction and Generation
Qihang Yu, Mark Weber, Xueqing Deng, Xiaohui Shen, Daniel Cremers, Liang-Chieh Chen
0
0
Recent advancements in generative models have highlighted the crucial role of image tokenization in the efficient synthesis of high-resolution images. Tokenization, which transforms images into latent representations, reduces computational demands compared to directly processing pixels and enhances the effectiveness and efficiency of the generation process. Prior methods, such as VQGAN, typically utilize 2D latent grids with fixed downsampling factors. However, these 2D tokenizations face challenges in managing the inherent redundancies present in images, where adjacent regions frequently display similarities. To overcome this issue, we introduce Transformer-based 1-Dimensional Tokenizer (TiTok), an innovative approach that tokenizes images into 1D latent sequences. TiTok provides a more compact latent representation, yielding substantially more efficient and effective representations than conventional techniques. For example, a 256 x 256 x 3 image can be reduced to just 32 discrete tokens, a significant reduction from the 256 or 1024 tokens obtained by prior methods. Despite its compact nature, TiTok achieves competitive performance to state-of-the-art approaches. Specifically, using the same generator framework, TiTok attains 1.97 gFID, outperforming MaskGIT baseline significantly by 4.21 at ImageNet 256 x 256 benchmark. The advantages of TiTok become even more significant when it comes to higher resolution. At ImageNet 512 x 512 benchmark, TiTok not only outperforms state-of-the-art diffusion model DiT-XL/2 (gFID 2.74 vs. 3.04), but also reduces the image tokens by 64x, leading to 410x faster generation process. Our best-performing variant can significantly surpasses DiT-XL/2 (gFID 2.13 vs. 3.04) while still generating high-quality samples 74x faster.
6/12/2024
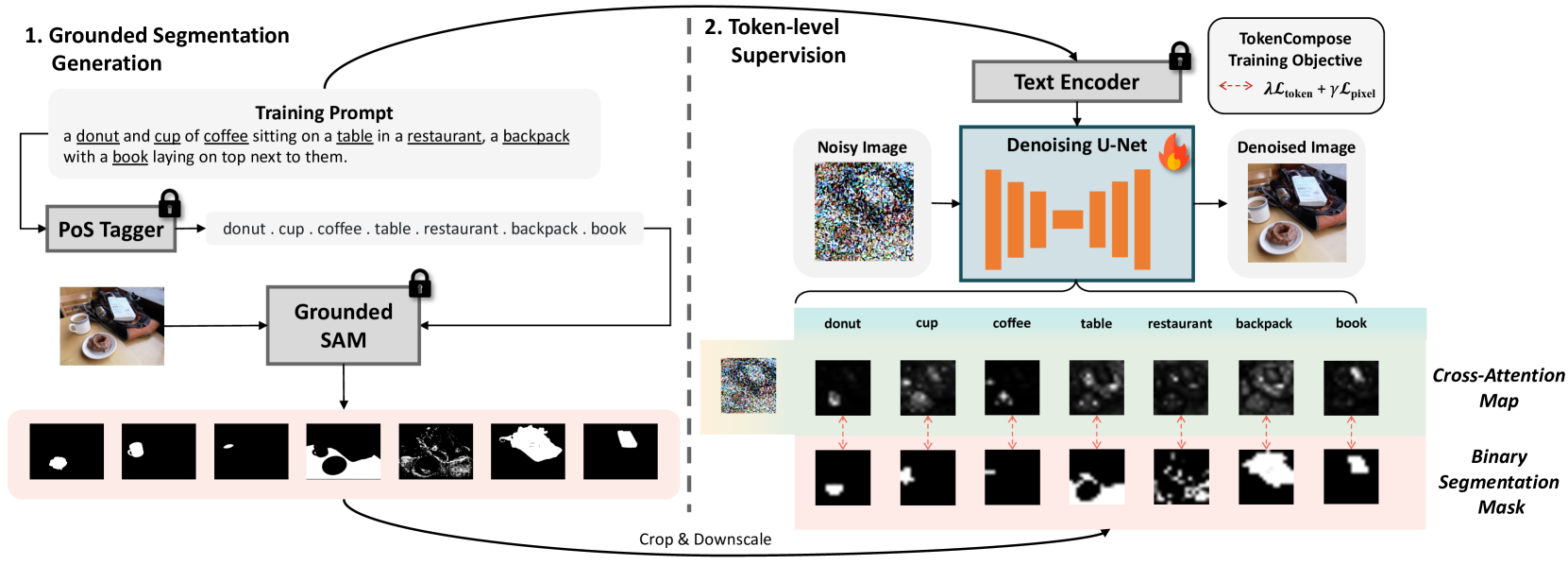
TokenCompose: Text-to-Image Diffusion with Token-level Supervision
Zirui Wang, Zhizhou Sha, Zheng Ding, Yilin Wang, Zhuowen Tu
0
0
We present TokenCompose, a Latent Diffusion Model for text-to-image generation that achieves enhanced consistency between user-specified text prompts and model-generated images. Despite its tremendous success, the standard denoising process in the Latent Diffusion Model takes text prompts as conditions only, absent explicit constraint for the consistency between the text prompts and the image contents, leading to unsatisfactory results for composing multiple object categories. TokenCompose aims to improve multi-category instance composition by introducing the token-wise consistency terms between the image content and object segmentation maps in the finetuning stage. TokenCompose can be applied directly to the existing training pipeline of text-conditioned diffusion models without extra human labeling information. By finetuning Stable Diffusion, the model exhibits significant improvements in multi-category instance composition and enhanced photorealism for its generated images. Project link: https://mlpc-ucsd.github.io/TokenCompose
6/26/2024
🏋️
Exploring Limits of Diffusion-Synthetic Training with Weakly Supervised Semantic Segmentation
Ryota Yoshihashi, Yuya Otsuka, Kenji Doi, Tomohiro Tanaka, Hirokatsu Kataoka
0
0
The advance of generative models for images has inspired various training techniques for image recognition utilizing synthetic images. In semantic segmentation, one promising approach is extracting pseudo-masks from attention maps in text-to-image diffusion models, which enables real-image-and-annotation-free training. However, the pioneering training method using the diffusion-synthetic images and pseudo-masks, i.e., DiffuMask has limitations in terms of mask quality, scalability, and ranges of applicable domains. To overcome these limitations, this work introduces three techniques for diffusion-synthetic semantic segmentation training. First, reliability-aware robust training, originally used in weakly supervised learning, helps segmentation with insufficient synthetic mask quality. %Second, large-scale pretraining of whole segmentation models, not only backbones, on synthetic ImageNet-1k-class images with pixel-labels benefits downstream segmentation tasks. Second, we introduce prompt augmentation, data augmentation to the prompt text set to scale up and diversify training images with a limited text resources. Finally, LoRA-based adaptation of Stable Diffusion enables the transfer to a distant domain, e.g., auto-driving images. Experiments in PASCAL VOC, ImageNet-S, and Cityscapes show that our method effectively closes gap between real and synthetic training in semantic segmentation.
4/16/2024
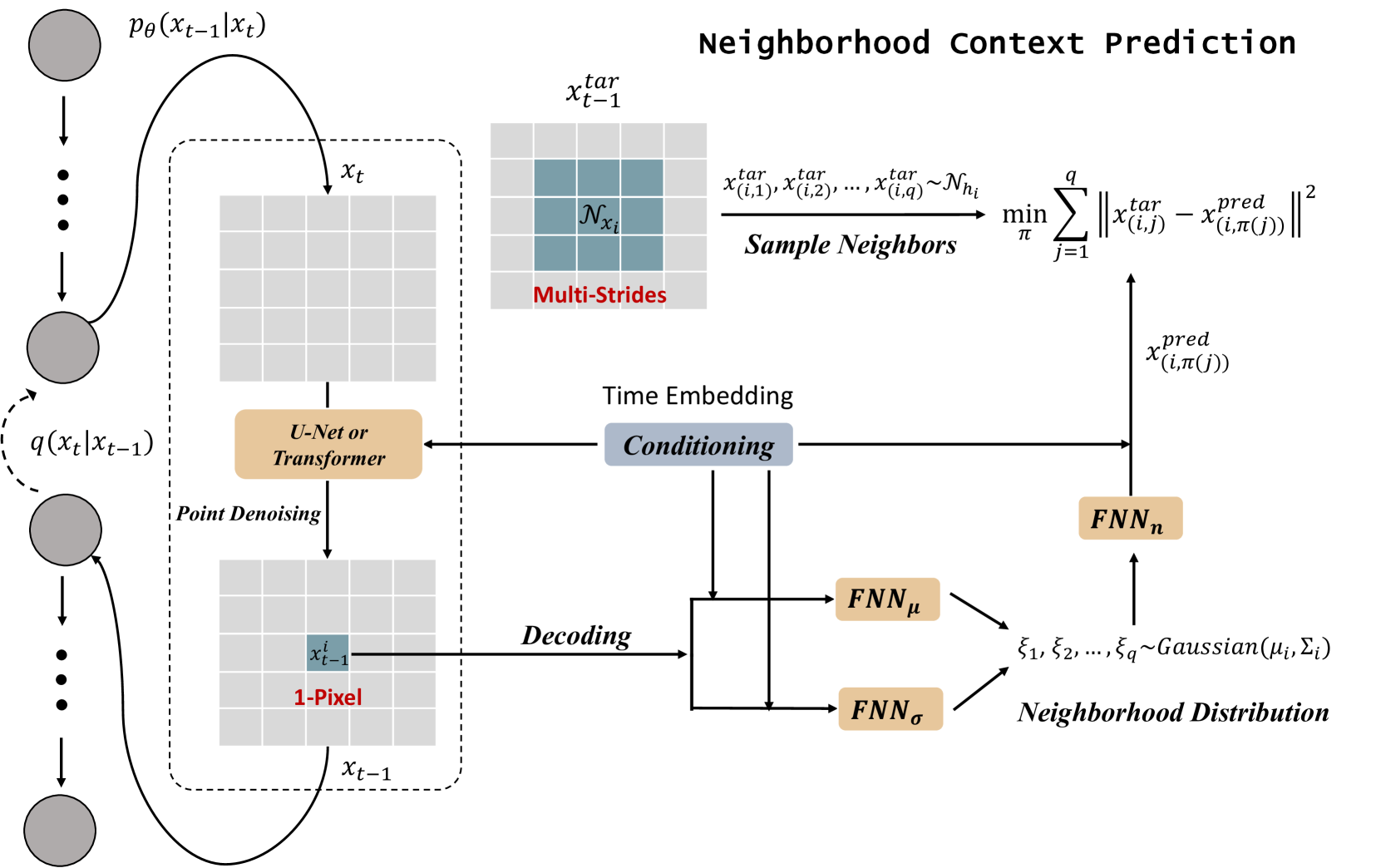
Improving Diffusion-Based Image Synthesis with Context Prediction
Ling Yang, Jingwei Liu, Shenda Hong, Zhilong Zhang, Zhilin Huang, Zheming Cai, Wentao Zhang, Bin Cui
0
0
Diffusion models are a new class of generative models, and have dramatically promoted image generation with unprecedented quality and diversity. Existing diffusion models mainly try to reconstruct input image from a corrupted one with a pixel-wise or feature-wise constraint along spatial axes. However, such point-based reconstruction may fail to make each predicted pixel/feature fully preserve its neighborhood context, impairing diffusion-based image synthesis. As a powerful source of automatic supervisory signal, context has been well studied for learning representations. Inspired by this, we for the first time propose ConPreDiff to improve diffusion-based image synthesis with context prediction. We explicitly reinforce each point to predict its neighborhood context (i.e., multi-stride features/tokens/pixels) with a context decoder at the end of diffusion denoising blocks in training stage, and remove the decoder for inference. In this way, each point can better reconstruct itself by preserving its semantic connections with neighborhood context. This new paradigm of ConPreDiff can generalize to arbitrary discrete and continuous diffusion backbones without introducing extra parameters in sampling procedure. Extensive experiments are conducted on unconditional image generation, text-to-image generation and image inpainting tasks. Our ConPreDiff consistently outperforms previous methods and achieves a new SOTA text-to-image generation results on MS-COCO, with a zero-shot FID score of 6.21.
6/5/2024