Conditional Variational Auto Encoder Based Dynamic Motion for Multi-task Imitation Learning

0
Sign in to get full access
Overview
- This paper presents a Conditional Variational Auto Encoder (CVAE) based approach for multi-task imitation learning of dynamic motion.
- The proposed method aims to learn a latent representation that can capture the underlying dynamics of different tasks, allowing for efficient transfer and adaptation to new tasks.
- The CVAE model is trained to generate dynamic motion trajectories conditioned on task-specific information, enabling the system to perform diverse tasks by sampling from the learned latent space.
Plain English Explanation
The researchers have developed a machine learning model called a Conditional Variational Auto Encoder (CVAE) that can learn to perform a variety of dynamic motion tasks by observing examples of those tasks. The key idea is to train the CVAE to learn a compact, flexible representation of the underlying dynamics common to different tasks.
This allows the model to efficiently adapt and apply its learned knowledge to new tasks, rather than having to start from scratch for each new task. By conditioning the CVAE on task-specific information, the model can generate the appropriate dynamic motion trajectories for a given task. This makes the system more versatile and capable of handling a broader range of challenges compared to training a separate model for each individual task.
The Enhancing Robotic Adaptability through Integrating Unsupervised Trajectory Segmentation and Variational Dynamic Self-Supervised Exploration for Deep Reinforcement papers explore related ideas of leveraging latent representations and task-conditioning to improve the adaptability and generalization of robotic systems.
Technical Explanation
The paper formulates the multi-task imitation learning problem as learning a conditional generative model that can produce dynamic motion trajectories given task-specific conditioning information. The proposed CVAE-based approach learns a latent representation that captures the underlying dynamics common across different tasks.
The CVAE model consists of an encoder that maps the input motion trajectories and task-specific information into a latent space, and a decoder that generates the output motion trajectories conditioned on the latent representation and task-specific inputs. This architecture allows the model to learn a compact, task-relevant latent space that can be efficiently reused for new tasks, as explored in the Logic-Dynamic Movement Primitives for Long-Horizon Manipulation and Unified Control Framework for Real-Time Interception of Dynamic Obstacles papers.
The training procedure involves optimizing the CVAE model to minimize the reconstruction loss of the motion trajectories while also promoting a well-structured latent space that can capture the underlying task dynamics. This is achieved through the variational autoencoder objective, which encourages the latent representation to follow a Gaussian distribution.
The authors demonstrate the effectiveness of their approach on a set of simulated robotic manipulation tasks, showing that the CVAE-based model can successfully adapt to new tasks by sampling from the learned latent space and conditioning on the task-specific information. This work relates to the Bridging Language, Vision, and Action through Multimodal VAEs for Robotic Manipulation paper, which explores similar ideas of leveraging multimodal representations for flexible task adaptation.
Critical Analysis
The paper presents a promising approach for enabling versatile and adaptable robotic systems through the use of a conditional generative model. The CVAE-based architecture and training objective seem well-designed to capture the underlying task dynamics in a compact, task-relevant latent representation.
However, the paper does not extensively explore the limitations or potential drawbacks of the proposed method. For example, it would be valuable to understand the extent to which the learned latent representation can generalize to completely novel tasks, beyond the set of training tasks. Additionally, the paper does not discuss the computational and memory requirements of the CVAE model, which could be an important practical consideration for real-world deployment.
Furthermore, the authors could have provided a more thorough analysis of the learned latent representations, such as visualizing the structure of the latent space or evaluating the degree of task-relevant information captured. This could shed light on the model's inner workings and help identify areas for further improvement.
Overall, the paper presents an interesting and innovative approach to multi-task imitation learning, but additional research and analysis would be beneficial to fully understand the capabilities and limitations of the CVAE-based framework.
Conclusion
This paper introduces a Conditional Variational Auto Encoder (CVAE) based method for multi-task imitation learning of dynamic motion. The key idea is to learn a latent representation that can capture the underlying dynamics common across different tasks, enabling efficient transfer and adaptation to new tasks.
The CVAE model is trained to generate dynamic motion trajectories conditioned on task-specific information, allowing the system to perform a variety of tasks by sampling from the learned latent space. This approach holds promise for developing more versatile and adaptable robotic systems that can leverage their learned knowledge to tackle a broader range of challenges.
While the paper presents promising results, further research is needed to fully understand the limitations and potential of the CVAE-based framework, such as its ability to generalize to completely novel tasks and the computational requirements of the model. Continued advancements in this area could lead to significant improvements in the flexibility and performance of robotic systems, with applications across various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Conditional Variational Auto Encoder Based Dynamic Motion for Multi-task Imitation Learning
Binzhao Xu, Muhayy Ud Din, Irfan Hussain
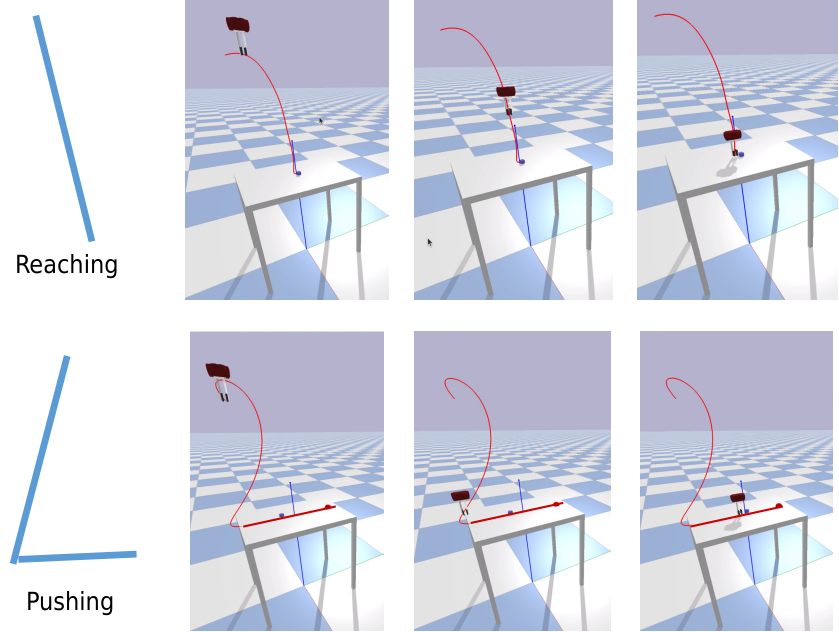
The dynamic motion primitive-based (DMP) method is an effective method of learning from demonstrations. However, most of the current DMP-based methods focus on learning one task with one module. Although, some deep learning-based frameworks can learn to multi-task at the same time. However, those methods require a large number of training data and have limited generalization of the learned behavior to the untrained state. In this paper, we propose a framework that combines the advantages of the traditional DMP-based method and conditional variational auto-encoder (CVAE). The encoder and decoder are made of a dynamic system and deep neural network. Deep neural networks are used to generate torque conditioned on the task ID. Then, this torque is used to create the desired trajectory in the dynamic system based on the final state. In this way, the generated tractory can adjust to the new goal position. We also propose a finetune method to guarantee the via-point constraint. Our model is trained on the handwriting number dataset and can be used to solve robotic tasks -- reaching and pushing directly. The proposed model is validated in the simulation environment. The results show that after training on the handwriting number dataset, it achieves a 100% success rate on pushing and reaching tasks.
Read more5/27/2024
📈
0
MoVEInt: Mixture of Variational Experts for Learning Human-Robot Interactions from Demonstrations
Vignesh Prasad, Alap Kshirsagar, Dorothea Koert, Ruth Stock-Homburg, Jan Peters, Georgia Chalvatzaki
Shared dynamics models are important for capturing the complexity and variability inherent in Human-Robot Interaction (HRI). Therefore, learning such shared dynamics models can enhance coordination and adaptability to enable successful reactive interactions with a human partner. In this work, we propose a novel approach for learning a shared latent space representation for HRIs from demonstrations in a Mixture of Experts fashion for reactively generating robot actions from human observations. We train a Variational Autoencoder (VAE) to learn robot motions regularized using an informative latent space prior that captures the multimodality of the human observations via a Mixture Density Network (MDN). We show how our formulation derives from a Gaussian Mixture Regression formulation that is typically used approaches for learning HRI from demonstrations such as using an HMM/GMM for learning a joint distribution over the actions of the human and the robot. We further incorporate an additional regularization to prevent mode collapse, a common phenomenon when using latent space mixture models with VAEs. We find that our approach of using an informative MDN prior from human observations for a VAE generates more accurate robot motions compared to previous HMM-based or recurrent approaches of learning shared latent representations, which we validate on various HRI datasets involving interactions such as handshakes, fistbumps, waving, and handovers. Further experiments in a real-world human-to-robot handover scenario show the efficacy of our approach for generating successful interactions with four different human interaction partners.
Read more7/11/2024

0
DynaMo: In-Domain Dynamics Pretraining for Visuo-Motor Control
Zichen Jeff Cui, Hengkai Pan, Aadhithya Iyer, Siddhant Haldar, Lerrel Pinto
Imitation learning has proven to be a powerful tool for training complex visuomotor policies. However, current methods often require hundreds to thousands of expert demonstrations to handle high-dimensional visual observations. A key reason for this poor data efficiency is that visual representations are predominantly either pretrained on out-of-domain data or trained directly through a behavior cloning objective. In this work, we present DynaMo, a new in-domain, self-supervised method for learning visual representations. Given a set of expert demonstrations, we jointly learn a latent inverse dynamics model and a forward dynamics model over a sequence of image embeddings, predicting the next frame in latent space, without augmentations, contrastive sampling, or access to ground truth actions. Importantly, DynaMo does not require any out-of-domain data such as Internet datasets or cross-embodied datasets. On a suite of six simulated and real environments, we show that representations learned with DynaMo significantly improve downstream imitation learning performance over prior self-supervised learning objectives, and pretrained representations. Gains from using DynaMo hold across policy classes such as Behavior Transformer, Diffusion Policy, MLP, and nearest neighbors. Finally, we ablate over key components of DynaMo and measure its impact on downstream policy performance. Robot videos are best viewed at https://dynamo-ssl.github.io
Read more9/19/2024
🤷
0
Enhancing Robotic Adaptability: Integrating Unsupervised Trajectory Segmentation and Conditional ProMPs for Dynamic Learning Environments
Tianci Gao
We propose a novel framework for enhancing robotic adaptability and learning efficiency, which integrates unsupervised trajectory segmentation with adaptive probabilistic movement primitives (ProMPs). By employing a cutting-edge deep learning architecture that combines autoencoders and Recurrent Neural Networks (RNNs), our approach autonomously pinpoints critical transitional points in continuous, unlabeled motion data, thus significantly reducing dependence on extensively labeled datasets. This innovative method dynamically adjusts motion trajectories using conditional variables, significantly enhancing the flexibility and accuracy of robotic actions under dynamic conditions while also reducing the computational overhead associated with traditional robotic programming methods. Our experimental validation demonstrates superior learning efficiency and adaptability compared to existing techniques, paving the way for advanced applications in industrial and service robotics.
Read more5/1/2024