Conformal Prediction via Regression-as-Classification
2404.08168
0
0
Abstract
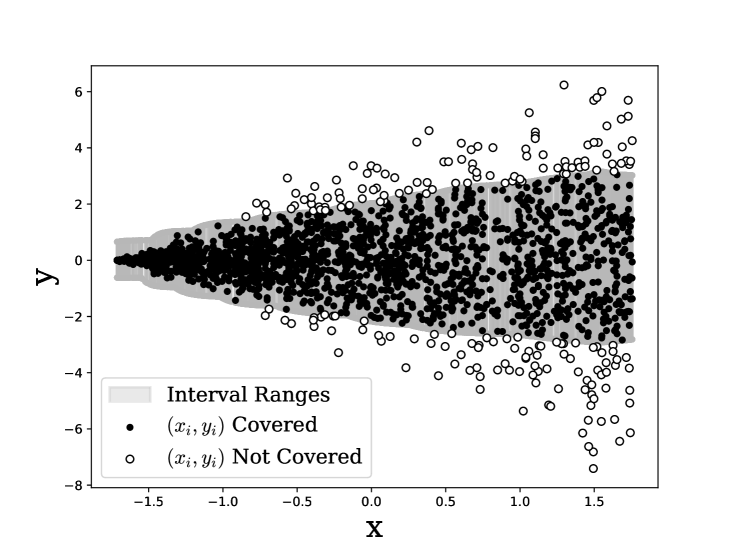
Conformal prediction (CP) for regression can be challenging, especially when the output distribution is heteroscedastic, multimodal, or skewed. Some of the issues can be addressed by estimating a distribution over the output, but in reality, such approaches can be sensitive to estimation error and yield unstable intervals.~Here, we circumvent the challenges by converting regression to a classification problem and then use CP for classification to obtain CP sets for regression.~To preserve the ordering of the continuous-output space, we design a new loss function and make necessary modifications to the CP classification techniques.~Empirical results on many benchmarks shows that this simple approach gives surprisingly good results on many practical problems.
Create account to get full access
Overview
- This paper proposes a new method for conformal prediction, which is a framework for constructing prediction sets with guaranteed coverage properties.
- The key idea is to reframe regression tasks as classification problems, allowing the use of powerful classification techniques for conformal prediction.
- The authors demonstrate the effectiveness of their approach on several real-world datasets, showing it can outperform traditional conformal prediction methods.
Plain English Explanation
Conformal prediction is a way to create prediction sets that come with a guarantee - for example, you might want a model that is 95% sure its predictions are correct. Regression-as-Classification is a new technique that the authors propose to achieve this.
The core idea is to take a regression problem, where you're trying to predict a numerical value, and reframe it as a classification problem. Instead of predicting the exact value, you classify whether the true value is inside or outside of a certain range. This allows you to leverage powerful classification algorithms and methods like Conformal Prediction to get prediction sets with the desired coverage guarantees.
The authors show that this regression-as-classification approach works well on real-world datasets, often outperforming traditional conformal prediction methods. This suggests it could be a useful tool for applications where reliable, well-calibrated predictions are important, like financial forecasting or renewable energy planning.
Technical Explanation
The paper introduces a new conformal prediction framework based on reframing regression tasks as classification problems. Traditional conformal prediction methods directly apply the conformal principle to regression models, but the authors argue that this can be limiting.
Instead, they propose a "regression-as-classification" approach. The key idea is to define a set of classifiers, each of which predicts whether the true regression target falls within a certain prediction interval. These classifiers are then used within the conformal prediction framework to construct prediction sets with the desired coverage guarantees.
The authors show that this approach has several advantages. First, it allows the use of powerful classification techniques that may be more effective than direct regression modeling. Second, it provides a natural way to handle heteroscedastic (non-uniform) noise in the regression problem. And third, the classification formulation enables the use of calibration techniques from the rich literature on conformal prediction.
The authors evaluate their method on several real-world regression datasets, including ones related to electricity load forecasting and chemical manufacturing. They demonstrate that the regression-as-classification approach can outperform traditional conformal prediction techniques in terms of prediction set size and calibration.
Critical Analysis
The paper presents a compelling approach to conformal prediction that builds on recent advances in classification methods. The authors provide a clear theoretical framework and demonstrate the effectiveness of their technique on several real-world datasets.
One potential limitation is the requirement to define a set of classifiers, each of which predicts whether the true regression target falls within a certain interval. While the authors show this can be done effectively, it may add complexity compared to direct regression-based conformal prediction methods. Additionally, the choice of interval boundaries and number of classifiers could impact the performance of the approach.
The paper also does not extensively explore the computational efficiency of the regression-as-classification method. As the number of classifiers grows, the computational cost of the approach may become prohibitive, especially for large-scale or time-sensitive applications.
Finally, the paper focuses primarily on evaluating the prediction set size and calibration performance of the method. While these are important metrics, it would be valuable to also consider other factors such as the interpretability of the prediction sets, the robustness to distributional shift, and the extensibility to hierarchical or multi-task regression problems.
Conclusion
This paper presents a novel conformal prediction framework that reframes regression tasks as classification problems. The key insight is that this allows the use of powerful classification techniques to construct prediction sets with guaranteed coverage properties. The authors demonstrate the effectiveness of their approach on several real-world datasets, showing it can outperform traditional conformal prediction methods.
This work suggests that regression-as-classification could be a useful tool for applications where reliable, well-calibrated predictions are crucial, such as financial forecasting, renewable energy planning, or chemical manufacturing. As the field of conformal prediction continues to evolve, techniques like this that leverage advances in machine learning may become increasingly important for building robust and trustworthy predictive systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Adapting Conformal Prediction to Distribution Shifts Without Labels
Kevin Kasa, Zhiyu Zhang, Heng Yang, Graham W. Taylor
0
0
Conformal prediction (CP) enables machine learning models to output prediction sets with guaranteed coverage rate, assuming exchangeable data. Unfortunately, the exchangeability assumption is frequently violated due to distribution shifts in practice, and the challenge is often compounded by the lack of ground truth labels at test time. Focusing on classification in this paper, our goal is to improve the quality of CP-generated prediction sets using only unlabeled data from the test domain. This is achieved by two new methods called ECP and EACP, that adjust the score function in CP according to the base model's uncertainty on the unlabeled test data. Through extensive experiments on a number of large-scale datasets and neural network architectures, we show that our methods provide consistent improvement over existing baselines and nearly match the performance of supervised algorithms.
6/4/2024
🔮
An Information Theoretic Perspective on Conformal Prediction
Alvaro H. C. Correia, Fabio Valerio Massoli, Christos Louizos, Arash Behboodi
0
0
Conformal Prediction (CP) is a distribution-free uncertainty estimation framework that constructs prediction sets guaranteed to contain the true answer with a user-specified probability. Intuitively, the size of the prediction set encodes a general notion of uncertainty, with larger sets associated with higher degrees of uncertainty. In this work, we leverage information theory to connect conformal prediction to other notions of uncertainty. More precisely, we prove three different ways to upper bound the intrinsic uncertainty, as described by the conditional entropy of the target variable given the inputs, by combining CP with information theoretical inequalities. Moreover, we demonstrate two direct and useful applications of such connection between conformal prediction and information theory: (i) more principled and effective conformal training objectives that generalize previous approaches and enable end-to-end training of machine learning models from scratch, and (ii) a natural mechanism to incorporate side information into conformal prediction. We empirically validate both applications in centralized and federated learning settings, showing our theoretical results translate to lower inefficiency (average prediction set size) for popular CP methods.
6/27/2024
🤯
Exact and Approximate Conformal Inference for Multi-Output Regression
Chancellor Johnstone, Eugene Ndiaye
0
0
It is common in machine learning to estimate a response $y$ given covariate information $x$. However, these predictions alone do not quantify any uncertainty associated with said predictions. One way to overcome this deficiency is with conformal inference methods, which construct a set containing the unobserved response $y$ with a prescribed probability. Unfortunately, even with a one-dimensional response, conformal inference is computationally expensive despite recent encouraging advances. In this paper, we explore multi-output regression, delivering exact derivations of conformal inference $p$-values when the predictive model can be described as a linear function of $y$. Additionally, we propose texttt{unionCP} and a multivariate extension of texttt{rootCP} as efficient ways of approximating the conformal prediction region for a wide array of multi-output predictors, both linear and nonlinear, while preserving computational advantages. We also provide both theoretical and empirical evidence of the effectiveness of these methods using both real-world and simulated data.
6/26/2024

Normalizing Flows for Conformal Regression
Nicolo Colombo
0
0
Conformal Prediction (CP) algorithms estimate the uncertainty of a prediction model by calibrating its outputs on labeled data. The same calibration scheme usually applies to any model and data without modifications. The obtained prediction intervals are valid by construction but could be inefficient, i.e. unnecessarily big, if the prediction errors are not uniformly distributed over the input space. We present a general scheme to localize the intervals by training the calibration process. The standard prediction error is replaced by an optimized distance metric that depends explicitly on the object attributes. Learning the optimal metric is equivalent to training a Normalizing Flow that acts on the joint distribution of the errors and the inputs. Unlike the Error Reweighting CP algorithm of Papadopoulos et al. (2008), the framework allows estimating the gap between nominal and empirical conditional validity. The approach is compatible with existing locally-adaptive CP strategies based on re-weighting the calibration samples and applies to any point-prediction model without retraining.
6/27/2024