Searching by Code: a New SearchBySnippet Dataset and SnippeR Retrieval Model for Searching by Code Snippets

0
📈
Sign in to get full access
Overview
- The paper proposes a new dataset called "SearchBySnippet" to address the use case of searching for code samples and bugfixing instructions using a code snippet as the query, rather than just text.
- Existing code search datasets use code comments instead of full-text descriptions, making them unsuitable for this use case.
- The authors show that existing architectures perform poorly on the SearchBySnippet dataset, even after fine-tuning, and they present a new model called SnippeR that outperforms several baselines.
Plain English Explanation
When developers encounter a problem with their code, they often turn to online resources like StackOverflow to find solutions. However, the traditional way of searching for code, using text queries, may not be the most natural or effective approach in these situations.
Instead, developers might find it more intuitive to search using a code snippet - a small piece of their own code that is causing an issue - along with any associated error messages or tracebacks. This "search-by-code" use case is not well-covered by existing code search datasets, which tend to use code comments rather than full-text descriptions.
To address this gap, the researchers have created a new dataset called SearchBySnippet, based on StackOverflow data. They show that existing code search models struggle to perform well on this dataset, even after being fine-tuned. In response, the researchers present a new model called SnippeR that outperforms several strong baselines on the SearchBySnippet benchmark.
By introducing this new dataset and model, the researchers aim to provide a more relevant and challenging benchmark for evaluating code search systems, particularly in the context of finding bugfixing instructions and code samples using a code snippet as the query.
Technical Explanation
The paper focuses on the task of code search, which is typically performed by searching for code based on a text query. However, the authors argue that a more natural use case is searching for code samples and bugfixing instructions using a code snippet (and possibly an error traceback) as the query.
To explore this use case, the researchers introduce a new dataset called SearchBySnippet, which is based on StackOverflow data. Unlike existing code search datasets that use code comments as the textual information, SearchBySnippet contains full-text descriptions, making it more suitable for the search-by-code use case.
The authors evaluate several existing code search architectures, including Training Neural Networks to Explain Binaries, ReinforEST, and Advanced Detection of Source Code Clones via Ensemble, on the SearchBySnippet dataset. They find that these models perform poorly, even after fine-tuning, and are outperformed by a simple BM25 baseline.
To address this challenge, the researchers propose a new single encoder model called SnippeR, which outperforms several strong baselines on the SearchBySnippet dataset with a Recall@10 score of 0.451.
Critical Analysis
The researchers have identified an important and underexplored use case for code search, which is searching for code samples and bugfixing instructions using a code snippet as the query. The introduction of the SearchBySnippet dataset, which is based on real-world StackOverflow data, is a valuable contribution to the field.
However, the paper does not provide a detailed analysis of the limitations of existing code search datasets and architectures in the context of the search-by-code use case. It would have been helpful to understand the specific shortcomings of these models and datasets that led to their poor performance on the SearchBySnippet benchmark.
Additionally, the paper lacks a thorough discussion of the design choices and architectural details of the SnippeR model. While the authors demonstrate its superior performance, more insight into the model's inner workings and the rationale behind its design would help the reader better understand the technical contributions of the research.
Finally, the paper could have explored the potential challenges and limitations of the SearchBySnippet dataset, such as the quality and representativeness of the StackOverflow data, the diversity of the code snippets and descriptions, and the potential for bias or noise in the dataset.
Conclusion
The paper presents a novel approach to code search, focusing on the use case of searching for code samples and bugfixing instructions using a code snippet as the query. By introducing the SearchBySnippet dataset and the SnippeR model, the researchers have made important contributions to the field of code search.
The SearchBySnippet dataset provides a more relevant and challenging benchmark for evaluating code search systems, while the SnippeR model demonstrates the potential for improvements over existing architectures in this domain. These contributions have the potential to drive further advancements in code search and help developers more effectively find the resources they need to solve their coding problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Searching by Code: a New SearchBySnippet Dataset and SnippeR Retrieval Model for Searching by Code Snippets
Ivan Sedykh, Dmitry Abulkhanov, Nikita Sorokin, Sergey Nikolenko, Valentin Malykh
Code search is an important and well-studied task, but it usually means searching for code by a text query. We argue that using a code snippet (and possibly an error traceback) as a query while looking for bugfixing instructions and code samples is a natural use case not covered by prior art. Moreover, existing datasets use code comments rather than full-text descriptions as text, making them unsuitable for this use case. We present a new SearchBySnippet dataset implementing the search-by-code use case based on StackOverflow data; we show that on SearchBySnippet, existing architectures fall short of a simple BM25 baseline even after fine-tuning. We present a new single encoder model SnippeR that outperforms several strong baselines on SearchBySnippet with a result of 0.451 Recall@10; we propose the SearchBySnippet dataset and SnippeR as a new important benchmark for code search evaluation.
Read more5/28/2024
0
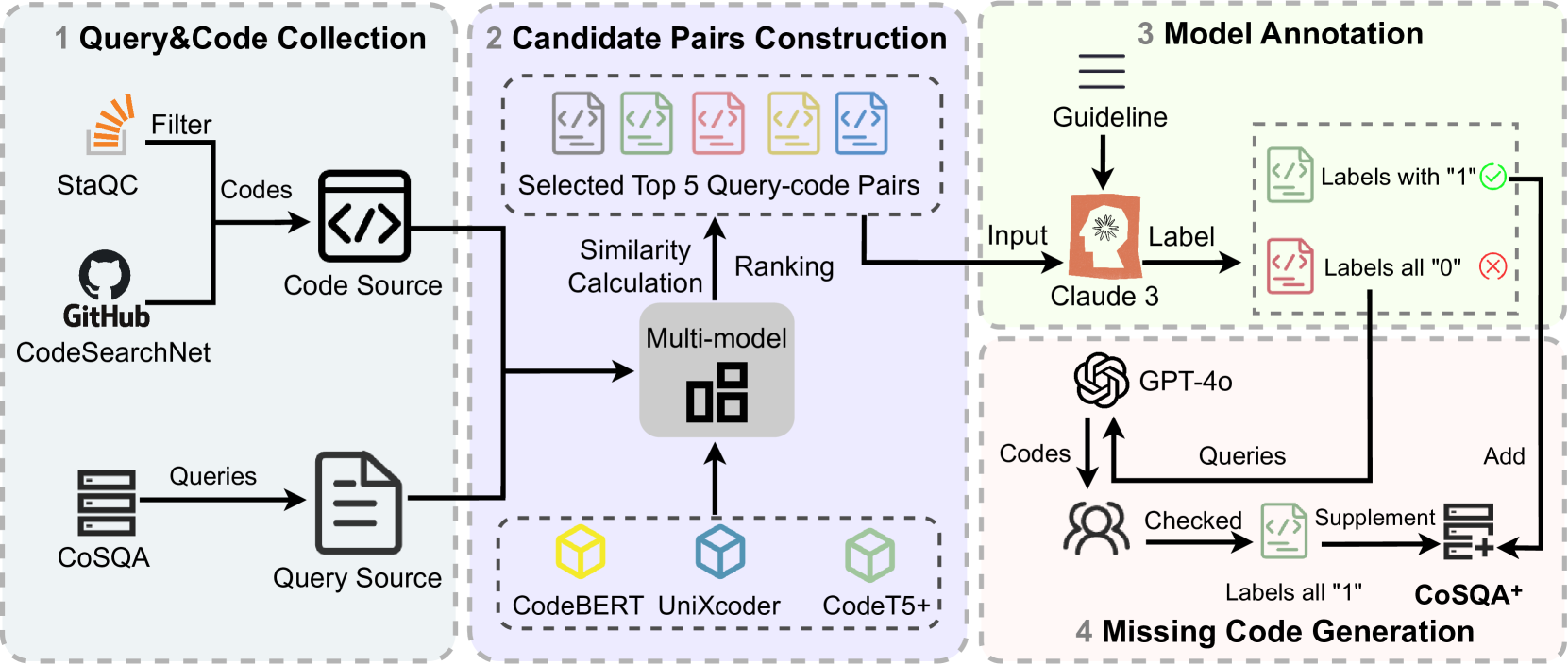
CoSQA+: Enhancing Code Search Dataset with Matching Code
Jing Gong, Yanghui Wu, Linxi Liang, Zibin Zheng, Yanlin Wang
Semantic code search, retrieving code that matches a given natural language query, is an important task to improve productivity in software engineering. Existing code search datasets are problematic: either using unrealistic queries, or with mismatched codes, and typically using one-to-one query-code pairing, which fails to reflect the reality that a query might have multiple valid code matches. This paper introduces CoSQA+, pairing high-quality queries (reused from CoSQA) with multiple suitable codes. We collect code candidates from diverse sources and form candidate pairs by pairing queries with these codes. Utilizing the power of large language models (LLMs), we automate pair annotation, filtering, and code generation for queries without suitable matches. Through extensive experiments, CoSQA+ has demonstrated superior quality over CoSQA. Models trained on CoSQA+ exhibit improved performance. Furthermore, we propose a new metric Mean Multi-choice Reciprocal Rank (MMRR), to assess one-to-N code search performance. We provide the code and data at https://github.com/DeepSoftwareAnalytics/CoSQA_Plus.
Read more8/27/2024

0
CoIR: A Comprehensive Benchmark for Code Information Retrieval Models
Xiangyang Li, Kuicai Dong, Yi Quan Lee, Wei Xia, Yichun Yin, Hao Zhang, Yong Liu, Yasheng Wang, Ruiming Tang
Despite the substantial success of Information Retrieval (IR) in various NLP tasks, most IR systems predominantly handle queries and corpora in natural language, neglecting the domain of code retrieval. Code retrieval is critically important yet remains under-explored, with existing methods and benchmarks inadequately representing the diversity of code in various domains and tasks. Addressing this gap, we present textbf{name} (textbf{Co}de textbf{I}nformation textbf{R}etrieval Benchmark), a robust and comprehensive benchmark specifically designed to assess code retrieval capabilities. name comprises textbf{ten} meticulously curated code datasets, spanning textbf{eight} distinctive retrieval tasks across textbf{seven} diverse domains. We first discuss the construction of name and its diverse dataset composition. Further, we evaluate nine widely used retrieval models using name, uncovering significant difficulties in performing code retrieval tasks even with state-of-the-art systems. To facilitate easy adoption and integration within existing research workflows, name has been developed as a user-friendly Python framework, readily installable via pip. It shares same data schema as other popular benchmarks like MTEB and BEIR, enabling seamless cross-benchmark evaluations. Through name, we aim to invigorate research in the code retrieval domain, providing a versatile benchmarking tool that encourages further development and exploration of code retrieval systemsfootnote{url{ https://github.com/CoIR-team/coir}}.
Read more7/4/2024
0
On Training a Neural Network to Explain Binaries
Alexander Interrante-Grant, Andy Davis, Heather Preslier, Tim Leek
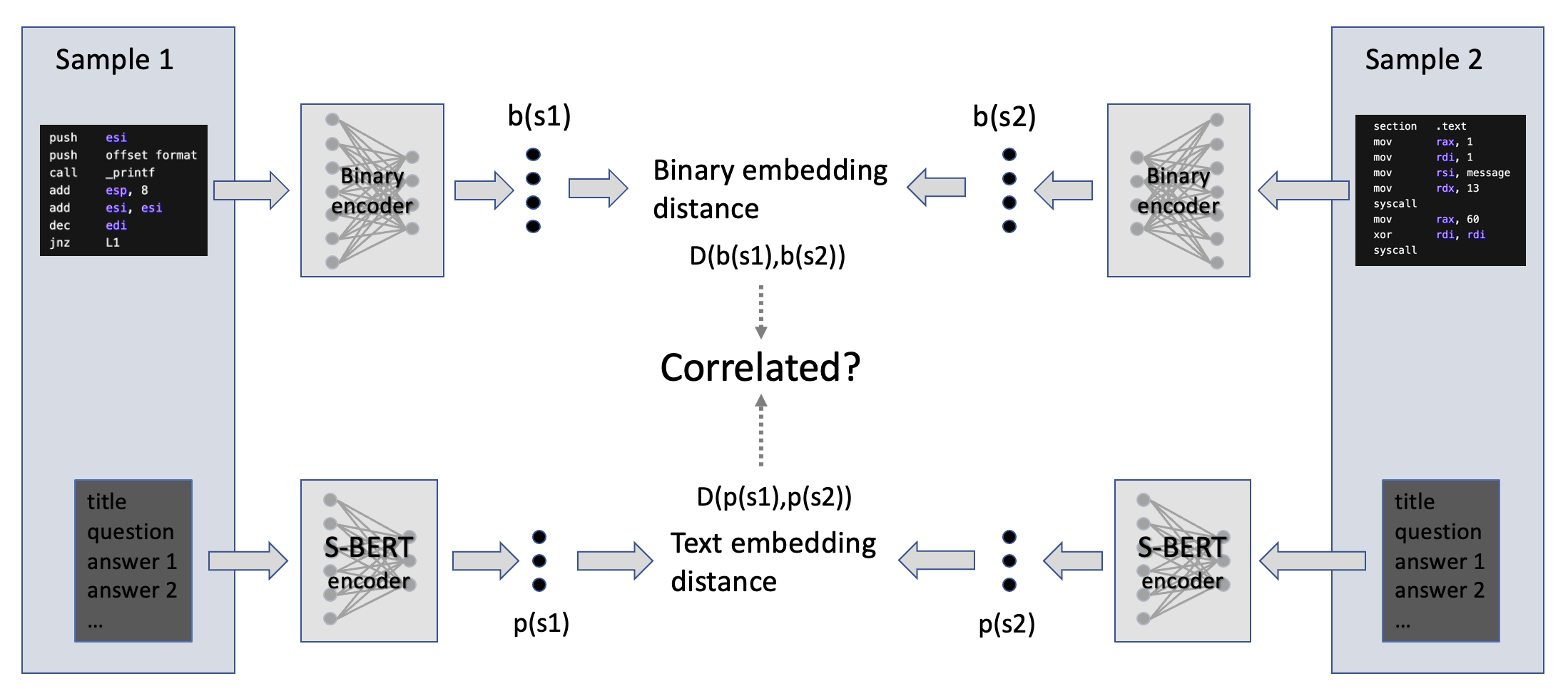
In this work, we begin to investigate the possibility of training a deep neural network on the task of binary code understanding. Specifically, the network would take, as input, features derived directly from binaries and output English descriptions of functionality to aid a reverse engineer in investigating the capabilities of a piece of closed-source software, be it malicious or benign. Given recent success in applying large language models (generative AI) to the task of source code summarization, this seems a promising direction. However, in our initial survey of the available datasets, we found nothing of sufficiently high quality and volume to train these complex models. Instead, we build our own dataset derived from a capture of Stack Overflow containing 1.1M entries. A major result of our work is a novel dataset evaluation method using the correlation between two distances on sample pairs: one distance in the embedding space of inputs and the other in the embedding space of outputs. Intuitively, if two samples have inputs close in the input embedding space, their outputs should also be close in the output embedding space. We found this Embedding Distance Correlation (EDC) test to be highly diagnostic, indicating that our collected dataset and several existing open-source datasets are of low quality as the distances are not well correlated. We proceed to explore the general applicability of EDC, applying it to a number of qualitatively known good datasets and a number of synthetically known bad ones and found it to be a reliable indicator of dataset value.
Read more5/1/2024