Exploring the Zero-Shot Capabilities of Vision-Language Models for Improving Gaze Following
2406.03907
0
0

Abstract
Contextual cues related to a person's pose and interactions with objects and other people in the scene can provide valuable information for gaze following. While existing methods have focused on dedicated cue extraction methods, in this work we investigate the zero-shot capabilities of Vision-Language Models (VLMs) for extracting a wide array of contextual cues to improve gaze following performance. We first evaluate various VLMs, prompting strategies, and in-context learning (ICL) techniques for zero-shot cue recognition performance. We then use these insights to extract contextual cues for gaze following, and investigate their impact when incorporated into a state of the art model for the task. Our analysis indicates that BLIP-2 is the overall top performing VLM and that ICL can improve performance. We also observe that VLMs are sensitive to the choice of the text prompt although ensembling over multiple text prompts can provide more robust performance. Additionally, we discover that using the entire image along with an ellipse drawn around the target person is the most effective strategy for visual prompting. For gaze following, incorporating the extracted cues results in better generalization performance, especially when considering a larger set of cues, highlighting the potential of this approach.
Create account to get full access
Overview
- This paper explores the use of vision-language models (VLMs) for improving gaze following, which is the task of predicting where a person is looking in an image.
- The researchers investigate the zero-shot capabilities of VLMs, meaning the models' ability to perform the gaze following task without any additional training.
- They compare the zero-shot performance of VLMs to specialized gaze following models and find that VLMs can achieve comparable or even superior performance in certain scenarios.
Plain English Explanation
Vision-language models (VLMs) are a type of artificial intelligence that can understand both visual and textual information. The paper "Improved Zero-Shot Classification by Adapting Vision-Language Models" provides a helpful overview of how these models work.
In this research, the scientists wanted to see if VLMs could be used to improve a task called "gaze following." Gaze following is when you can look at an image and predict where a person is looking. This is a useful skill for things like social interactions and navigating the world.
Typically, researchers build specialized models just for gaze following. But the scientists in this paper wondered if VLMs, which are trained on a much broader set of information, could actually do a better job at gaze following without any additional training. This is called "zero-shot" performance, because the models aren't trained specifically for gaze following.
The researchers compared the zero-shot performance of VLMs to the performance of dedicated gaze following models. Surprisingly, they found that the VLMs could match or even outperform the specialized models in certain situations. This suggests that the broad knowledge and visual understanding of VLMs can be leveraged for tasks like gaze following, without the need to train a separate model from scratch.
Technical Explanation
The paper investigates the zero-shot capabilities of vision-language models (VLMs) for the task of gaze following. Gaze following involves predicting where a person is looking in an image, which is an important skill for social interactions and navigation.
Traditionally, gaze following models are trained specifically for that task. However, the researchers hypothesized that the rich visual and language understanding of VLMs, such as CLIP and ViLT, could enable them to perform well on gaze following without any additional training.
To test this, the authors evaluated the zero-shot performance of several VLMs on popular gaze following benchmarks and compared them to specialized gaze following models. They found that in certain scenarios, the VLMs were able to match or even outperform the dedicated models in terms of gaze prediction accuracy.
The researchers attribute this success to the rich multimodal representations learned by VLMs, which allow them to leverage visual cues as well as contextual information from language to infer gaze direction. This is demonstrated in the paper's experiments, where VLMs excel particularly on images with complex scenes and multiple people.
The findings suggest that VLMs can be a powerful tool for gaze following, potentially eliminating the need for training specialized models from scratch. This could have implications for applications like contextual emotion recognition and enhancing gaze estimation, where gaze information is an important component.
Critical Analysis
The paper presents an intriguing exploration of the zero-shot capabilities of vision-language models for gaze following. The researchers provide a thorough evaluation of several VLMs on established benchmarks and offer a compelling explanation for their strong performance.
However, the paper also acknowledges some limitations of the study. For example, the VLMs are primarily evaluated on static images, whereas real-world gaze following often involves dynamic scenes. It remains to be seen how well the zero-shot VLM approach would translate to more realistic, video-based gaze following tasks.
Additionally, the paper does not delve into potential biases or failure cases of the VLMs on the gaze following task. As with any AI system, it would be important to understand the edge cases and potential failure modes to ensure the reliable deployment of these models in practical applications.
Further research could also explore ways to fine-tune or adapt the VLMs for gaze following, potentially leading to even stronger performance. Integrating the VLM-based approach with specialized gaze following architectures, as suggested in the GazeCLIP paper, could be a fruitful avenue for future work.
Overall, this paper makes a strong case for the potential of vision-language models to tackle gaze following tasks, with potential implications for a range of applications that rely on understanding human attention and visual focus.
Conclusion
This paper presents a novel approach to gaze following by leveraging the zero-shot capabilities of vision-language models (VLMs). The researchers demonstrate that VLMs can achieve comparable or even superior performance to specialized gaze following models without any additional training.
The findings suggest that the rich multimodal representations learned by VLMs can be effectively applied to tasks like gaze prediction, potentially eliminating the need for training dedicated models from scratch. This could have significant implications for applications that rely on understanding human attention and focus, such as social interactions, navigation, and contextual emotion recognition.
While the paper acknowledges some limitations, such as the need to explore dynamic scenes and address potential biases, the overall results highlight the versatility and power of VLMs. This research contributes to the growing body of work demonstrating the broad applicability of these large-scale multimodal models, and it encourages further exploration of their zero-shot capabilities across a wide range of tasks and domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Improved Zero-Shot Classification by Adapting VLMs with Text Descriptions
Oindrila Saha, Grant Van Horn, Subhransu Maji
0
0
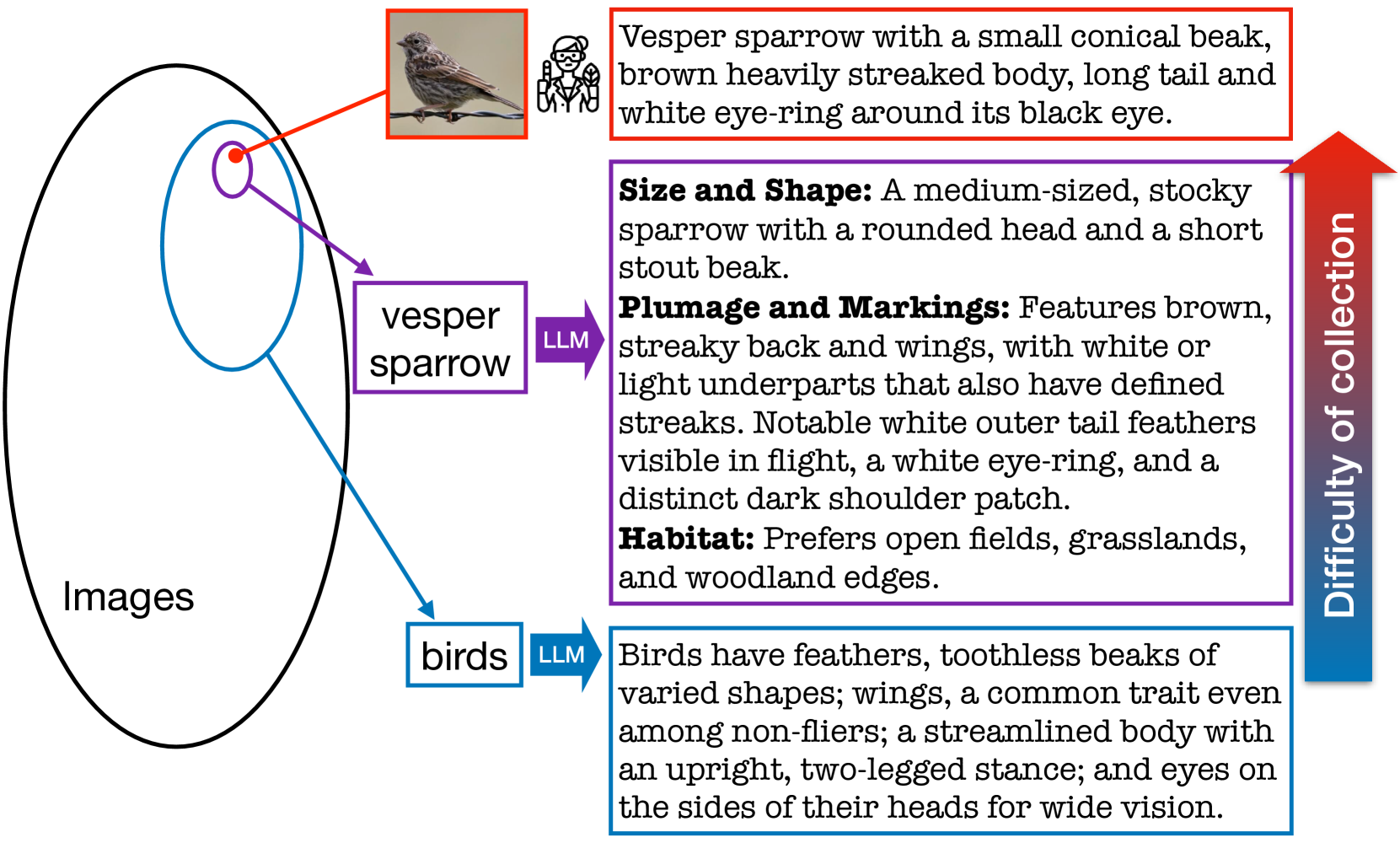
The zero-shot performance of existing vision-language models (VLMs) such as CLIP is limited by the availability of large-scale, aligned image and text datasets in specific domains. In this work, we leverage two complementary sources of information -- descriptions of categories generated by large language models (LLMs) and abundant, fine-grained image classification datasets -- to improve the zero-shot classification performance of VLMs across fine-grained domains. On the technical side, we develop methods to train VLMs with this bag-level image-text supervision. We find that simply using these attributes at test-time does not improve performance, but our training strategy, for example, on the iNaturalist dataset, leads to an average improvement of 4-5% in zero-shot classification accuracy for novel categories of birds and flowers. Similar improvements are observed in domains where a subset of the categories was used to fine-tune the model. By prompting LLMs in various ways, we generate descriptions that capture visual appearance, habitat, and geographic regions and pair them with existing attributes such as the taxonomic structure of the categories. We systematically evaluate their ability to improve zero-shot categorization in natural domains. Our findings suggest that geographic priors can be just as effective and are complementary to visual appearance. Our method also outperforms prior work on prompt-based tuning of VLMs. We release the benchmark, consisting of 14 datasets at https://github.com/cvl-umass/AdaptCLIPZS , which will contribute to future research in zero-shot recognition.
4/5/2024

Benchmarking Zero-Shot Recognition with Vision-Language Models: Challenges on Granularity and Specificity
Zhenlin Xu, Yi Zhu, Tiffany Deng, Abhay Mittal, Yanbei Chen, Manchen Wang, Paolo Favaro, Joseph Tighe, Davide Modolo
0
0
This paper presents novel benchmarks for evaluating vision-language models (VLMs) in zero-shot recognition, focusing on granularity and specificity. Although VLMs excel in tasks like image captioning, they face challenges in open-world settings. Our benchmarks test VLMs' consistency in understanding concepts across semantic granularity levels and their response to varying text specificity. Findings show that VLMs favor moderately fine-grained concepts and struggle with specificity, often misjudging texts that differ from their training data. Extensive evaluations reveal limitations in current VLMs, particularly in distinguishing between correct and subtly incorrect descriptions. While fine-tuning offers some improvements, it doesn't fully address these issues, highlighting the need for VLMs with enhanced generalization capabilities for real-world applications. This study provides insights into VLM limitations and suggests directions for developing more robust models.
6/19/2024

The Neglected Tails in Vision-Language Models
Shubham Parashar, Zhiqiu Lin, Tian Liu, Xiangjue Dong, Yanan Li, Deva Ramanan, James Caverlee, Shu Kong
0
0
Vision-language models (VLMs) excel in zero-shot recognition but their performance varies greatly across different visual concepts. For example, although CLIP achieves impressive accuracy on ImageNet (60-80%), its performance drops below 10% for more than ten concepts like night snake, presumably due to their limited presence in the pretraining data. However, measuring the frequency of concepts in VLMs' large-scale datasets is challenging. We address this by using large language models (LLMs) to count the number of pretraining texts that contain synonyms of these concepts. Our analysis confirms that popular datasets, such as LAION, exhibit a long-tailed concept distribution, yielding biased performance in VLMs. We also find that downstream applications of VLMs, including visual chatbots (e.g., GPT-4V) and text-to-image models (e.g., Stable Diffusion), often fail to recognize or generate images of rare concepts identified by our method. To mitigate the imbalanced performance of zero-shot VLMs, we propose REtrieval-Augmented Learning (REAL). First, instead of prompting VLMs using the original class names, REAL uses their most frequent synonyms found in pretraining texts. This simple change already outperforms costly human-engineered and LLM-enriched prompts over nine benchmark datasets. Second, REAL trains a linear classifier on a small yet balanced set of pretraining data retrieved using concept synonyms. REAL surpasses the previous zero-shot SOTA, using 400x less storage and 10,000x less training time!
5/24/2024
Contextual Emotion Recognition using Large Vision Language Models
Yasaman Etesam, Ozge Nilay Yalc{c}{i}n, Chuxuan Zhang, Angelica Lim
0
0
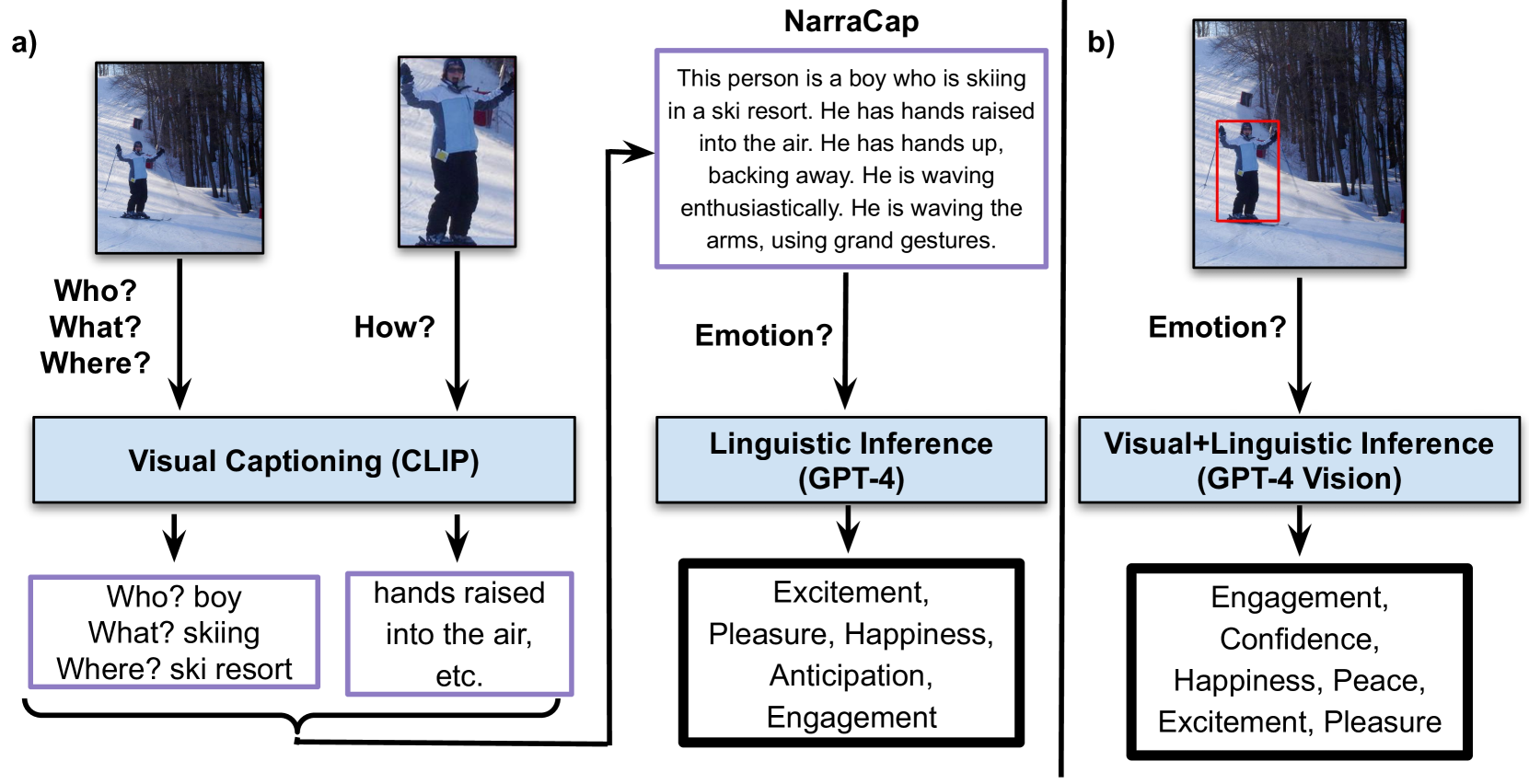
How does the person in the bounding box feel? Achieving human-level recognition of the apparent emotion of a person in real world situations remains an unsolved task in computer vision. Facial expressions are not enough: body pose, contextual knowledge, and commonsense reasoning all contribute to how humans perform this emotional theory of mind task. In this paper, we examine two major approaches enabled by recent large vision language models: 1) image captioning followed by a language-only LLM, and 2) vision language models, under zero-shot and fine-tuned setups. We evaluate the methods on the Emotions in Context (EMOTIC) dataset and demonstrate that a vision language model, fine-tuned even on a small dataset, can significantly outperform traditional baselines. The results of this work aim to help robots and agents perform emotionally sensitive decision-making and interaction in the future.
5/16/2024