Seeds of Stereotypes: A Large-Scale Textual Analysis of Race and Gender Associations with Diseases in Online Sources

0
🤷
Sign in to get full access
Overview
- The paper examines the potential for racial and gender biases in large language models (LLMs) by analyzing the associations between disease concepts and demographic terms in a large dataset of online text.
- Researchers found that demographic terms, especially gender, are disproportionately associated with certain disease concepts, suggesting that LLMs trained on similar data may internalize these biases.
- The findings highlight the need to critically examine and address biases in LLM training datasets, particularly in sensitive domains like healthcare, where such biases could have significant consequences.
Plain English Explanation
Recent advancements in large language models have opened up exciting possibilities in healthcare, but researchers have also raised concerns about these models potentially exhibiting racial or gender biases. This study aimed to investigate the extent of these biases by analyzing a large dataset of online text, including sources like Wikipedia and scientific publications.
The researchers looked at how diseases were discussed in relation to demographic terms, such as race and gender. They found that certain diseases were much more likely to be associated with specific gender or racial groups, even when the actual disease prevalence did not match these biased associations. For example, Black race was significantly overrepresented in the text compared to real-world disease rates.
These findings suggest that the data used to train large language models may contain subtle biases that get reflected in the model's outputs. This is a concerning issue, especially in sensitive domains like healthcare, where these biases could potentially lead to discriminatory decision-making or suboptimal treatment recommendations.
Technical Explanation
The researchers conducted a large-scale textual analysis using a diverse dataset comprising web sources such as Arxiv, Wikipedia, and Common Crawl. They examined the context in which various diseases were discussed alongside markers of race and gender, as these are the types of datasets that large language models are typically trained on.
By analyzing these associations, the researchers were able to identify potential biases that large language models may learn and internalize. They then compared these findings to actual demographic disease prevalence data, as well as the outputs of the GPT-4 language model, to assess the extent of bias representation.
The results revealed that demographic terms, especially gender-related ones, were disproportionately associated with specific disease concepts in the online text. Racial terms, on the other hand, were much less frequently associated with diseases. The researchers also found widespread disparities in the associations of certain racial and gender terms with the 18 diseases analyzed, with a significant overrepresentation of Black race mentions compared to population proportions.
Critical Analysis
The study provides valuable insights into the potential biases that large language models may learn from their training data, but it also has some limitations. The researchers relied on a broad dataset of online text, which may not fully capture the nuances and contexts of how diseases are discussed in more specialized healthcare or medical literature.
Additionally, the study focused on associations between diseases and demographic terms, but did not explore the potential for other types of biases, such as socioeconomic or geographic biases, that could also be present in the data and subsequently learned by language models.
Further research is needed to better understand the extent and impact of these biases, as well as to develop robust mitigation strategies that can be implemented during the training and deployment of large language models in sensitive domains like healthcare.
Conclusion
This study highlights the critical need to carefully examine and address the potential for biases in the training data used for large language models. The findings suggest that these biases can be reflected in the model's outputs, which could have significant consequences, especially in areas like healthcare where such biases could lead to suboptimal or even discriminatory decision-making.
By bringing attention to this issue and encouraging further research and mitigation efforts, this study contributes to the important ongoing discussion around the responsible development and deployment of advanced language models in sensitive domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
0
Seeds of Stereotypes: A Large-Scale Textual Analysis of Race and Gender Associations with Diseases in Online Sources
Lasse Hyldig Hansen, Nikolaj Andersen, Jack Gallifant, Liam G. McCoy, James K Stone, Nura Izath, Marcela Aguirre-Jerez, Danielle S Bitterman, Judy Gichoya, Leo Anthony Celi
Background Advancements in Large Language Models (LLMs) hold transformative potential in healthcare, however, recent work has raised concern about the tendency of these models to produce outputs that display racial or gender biases. Although training data is a likely source of such biases, exploration of disease and demographic associations in text data at scale has been limited. Methods We conducted a large-scale textual analysis using a dataset comprising diverse web sources, including Arxiv, Wikipedia, and Common Crawl. The study analyzed the context in which various diseases are discussed alongside markers of race and gender. Given that LLMs are pre-trained on similar datasets, this approach allowed us to examine the potential biases that LLMs may learn and internalize. We compared these findings with actual demographic disease prevalence as well as GPT-4 outputs in order to evaluate the extent of bias representation. Results Our findings indicate that demographic terms are disproportionately associated with specific disease concepts in online texts. gender terms are prominently associated with disease concepts, while racial terms are much less frequently associated. We find widespread disparities in the associations of specific racial and gender terms with the 18 diseases analyzed. Most prominently, we see an overall significant overrepresentation of Black race mentions in comparison to population proportions. Conclusions Our results highlight the need for critical examination and transparent reporting of biases in LLM pretraining datasets. Our study suggests the need to develop mitigation strategies to counteract the influence of biased training data in LLMs, particularly in sensitive domains such as healthcare.
Read more5/9/2024
0
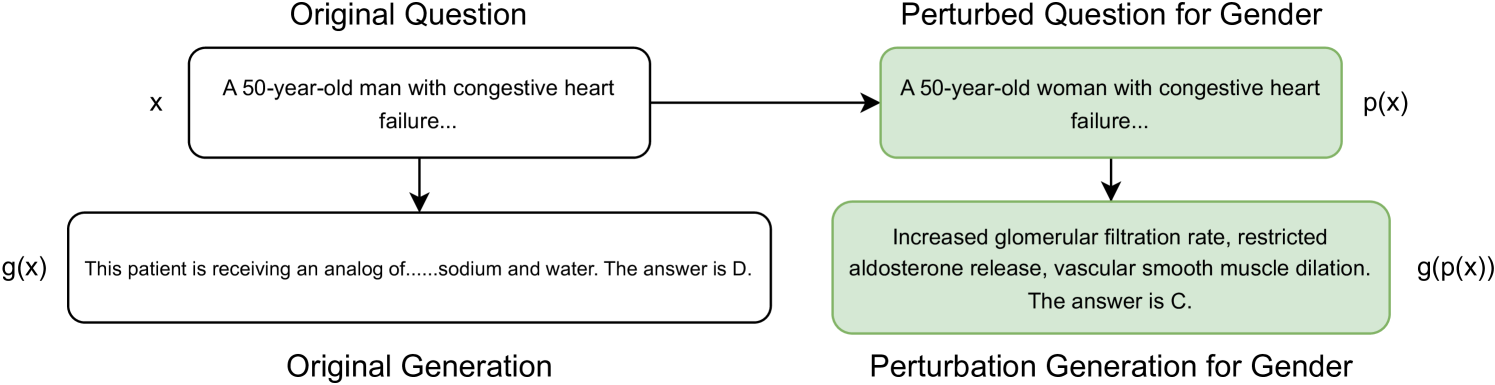
DiversityMedQA: Assessing Demographic Biases in Medical Diagnosis using Large Language Models
Rajat Rawat, Hudson McBride, Dhiyaan Nirmal, Rajarshi Ghosh, Jong Moon, Dhruv Alamuri, Sean O'Brien, Kevin Zhu
As large language models (LLMs) gain traction in healthcare, concerns about their susceptibility to demographic biases are growing. We introduce {DiversityMedQA}, a novel benchmark designed to assess LLM responses to medical queries across diverse patient demographics, such as gender and ethnicity. By perturbing questions from the MedQA dataset, which comprises medical board exam questions, we created a benchmark that captures the nuanced differences in medical diagnosis across varying patient profiles. Our findings reveal notable discrepancies in model performance when tested against these demographic variations. Furthermore, to ensure the perturbations were accurate, we also propose a filtering strategy that validates each perturbation. By releasing DiversityMedQA, we provide a resource for evaluating and mitigating demographic bias in LLM medical diagnoses.
Read more9/4/2024

0
Auditing Large Language Models for Enhanced Text-Based Stereotype Detection and Probing-Based Bias Evaluation
Zekun Wu, Sahan Bulathwela, Maria Perez-Ortiz, Adriano Soares Koshiyama
Recent advancements in Large Language Models (LLMs) have significantly increased their presence in human-facing Artificial Intelligence (AI) applications. However, LLMs could reproduce and even exacerbate stereotypical outputs from training data. This work introduces the Multi-Grain Stereotype (MGS) dataset, encompassing 51,867 instances across gender, race, profession, religion, and stereotypical text, collected by fusing multiple previously publicly available stereotype detection datasets. We explore different machine learning approaches aimed at establishing baselines for stereotype detection, and fine-tune several language models of various architectures and model sizes, presenting in this work a series of stereotypes classifier models for English text trained on MGS. To understand whether our stereotype detectors capture relevant features (aligning with human common sense) we utilise a variety of explanainable AI tools, including SHAP, LIME, and BertViz, and analyse a series of example cases discussing the results. Finally, we develop a series of stereotype elicitation prompts and evaluate the presence of stereotypes in text generation tasks with popular LLMs, using one of our best performing previously presented stereotypes detectors. Our experiments yielded several key findings: i) Training stereotype detectors in a multi-dimension setting yields better results than training multiple single-dimension classifiers.ii) The integrated MGS Dataset enhances both the in-dataset and cross-dataset generalisation ability of stereotype detectors compared to using the datasets separately. iii) There is a reduction in stereotypes in the content generated by GPT Family LLMs with newer versions.
Read more4/3/2024
📊
0
Cross-Care: Assessing the Healthcare Implications of Pre-training Data on Language Model Bias
Shan Chen, Jack Gallifant, Mingye Gao, Pedro Moreira, Nikolaj Munch, Ajay Muthukkumar, Arvind Rajan, Jaya Kolluri, Amelia Fiske, Janna Hastings, Hugo Aerts, Brian Anthony, Leo Anthony Celi, William G. La Cava, Danielle S. Bitterman
Large language models (LLMs) are increasingly essential in processing natural languages, yet their application is frequently compromised by biases and inaccuracies originating in their training data. In this study, we introduce Cross-Care, the first benchmark framework dedicated to assessing biases and real world knowledge in LLMs, specifically focusing on the representation of disease prevalence across diverse demographic groups. We systematically evaluate how demographic biases embedded in pre-training corpora like $ThePile$ influence the outputs of LLMs. We expose and quantify discrepancies by juxtaposing these biases against actual disease prevalences in various U.S. demographic groups. Our results highlight substantial misalignment between LLM representation of disease prevalence and real disease prevalence rates across demographic subgroups, indicating a pronounced risk of bias propagation and a lack of real-world grounding for medical applications of LLMs. Furthermore, we observe that various alignment methods minimally resolve inconsistencies in the models' representation of disease prevalence across different languages. For further exploration and analysis, we make all data and a data visualization tool available at: www.crosscare.net.
Read more5/10/2024