D-Rax: Domain-specific Radiologic assistant leveraging multi-modal data and eXpert model predictions

0

Sign in to get full access
Overview
• This paper presents D-Rax, a domain-specific radiologic assistant that leverages multi-modal data and expert model predictions to aid radiologists in their clinical decision-making.
• D-Rax integrates large vision-language models, specialized radiology models, and other relevant data sources to provide a comprehensive tool for radiologic analysis and interpretation.
• The key innovations of D-Rax include its ability to fuse diverse data modalities, leverage state-of-the-art expert models, and provide personalized recommendations tailored to individual radiologists' preferences and needs.
Plain English Explanation
• D-Rax is a specialized computer system designed to assist radiologists in their work. Radiologists are medical professionals who interpret medical images, such as X-rays, to help diagnose and treat patients.
• D-Rax combines different types of data, including medical images, patient records, and the knowledge of expert radiologists, to provide radiologists with more comprehensive information and recommendations when analyzing medical scans.
• For example, D-Rax may use advanced artificial intelligence (AI) models trained on millions of X-rays to automatically identify potential abnormalities or diseases. It can then cross-reference this information with the patient's medical history and feedback from experienced radiologists to suggest the most likely diagnosis and appropriate next steps.
• By integrating all of these different data sources, D-Rax aims to help radiologists make more informed and accurate decisions, ultimately leading to better patient care.
Technical Explanation
• D-Rax is a multi-modal framework that integrates large vision-language models, specialized radiology models, and other relevant data sources to enhance radiologic decision-making.
• The system leverages MedXChat, a unified multimodal large language model, to process and understand the various data inputs, including medical images, patient records, and radiologist notes.
• D-Rax also incorporates specialized radiology models, such as those described in Towards Clinically Accessible Radiology Foundation Model and MAIRA-1, to provide expert-level analysis and insights.
• The system's architecture allows for the seamless integration of these models, enabling the fusion of domain-adapted vision-language models, as discussed in Fusion: Domain-Adapted Vision-Language Models for Medical, to deliver personalized recommendations to individual radiologists.
• D-Rax also incorporates collaboration features, similar to those described in Enhancing Radiological Diagnosis: A Collaborative Approach Integrating AI, allowing radiologists to share insights and annotations, fostering a cooperative learning environment.
Critical Analysis
• The authors acknowledge that D-Rax's performance and reliability are heavily dependent on the quality and breadth of the underlying data and models. Potential biases or limitations in the training data could lead to incorrect or biased recommendations.
• The paper does not provide a comprehensive evaluation of D-Rax's real-world performance and its impact on radiologists' clinical decision-making. Further studies are needed to assess the system's practical utility and its ability to improve patient outcomes.
• While the integration of multiple data sources and expert models is a strength of D-Rax, the complexity of the system may present challenges in terms of interpretability and trust. Radiologists may be hesitant to fully rely on the system's recommendations without a clear understanding of its inner workings.
• The paper does not address potential privacy and security concerns associated with the handling of sensitive medical data, which will be critical for the deployment of such a system in clinical settings.
Conclusion
• D-Rax is a promising approach to leveraging advanced AI and multi-modal data to enhance radiologic decision-making and improve patient care.
• By fusing large vision-language models, specialized radiology models, and other relevant data sources, D-Rax aims to provide radiologists with a comprehensive and personalized tool to support their clinical practice.
• While the technical foundations of D-Rax appear sound, further research and evaluation are needed to assess its real-world impact and address potential challenges related to data quality, interpretability, and privacy.
• Overall, the development of systems like D-Rax represents an important step towards the integration of AI-powered tools in the medical field, with the potential to transform radiologic diagnosis and patient outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
D-Rax: Domain-specific Radiologic assistant leveraging multi-modal data and eXpert model predictions
Hareem Nisar, Syed Muhammad Anwar, Zhifan Jiang, Abhijeet Parida, Ramon Sanchez-Jacob, Vishwesh Nath, Holger R. Roth, Marius George Linguraru
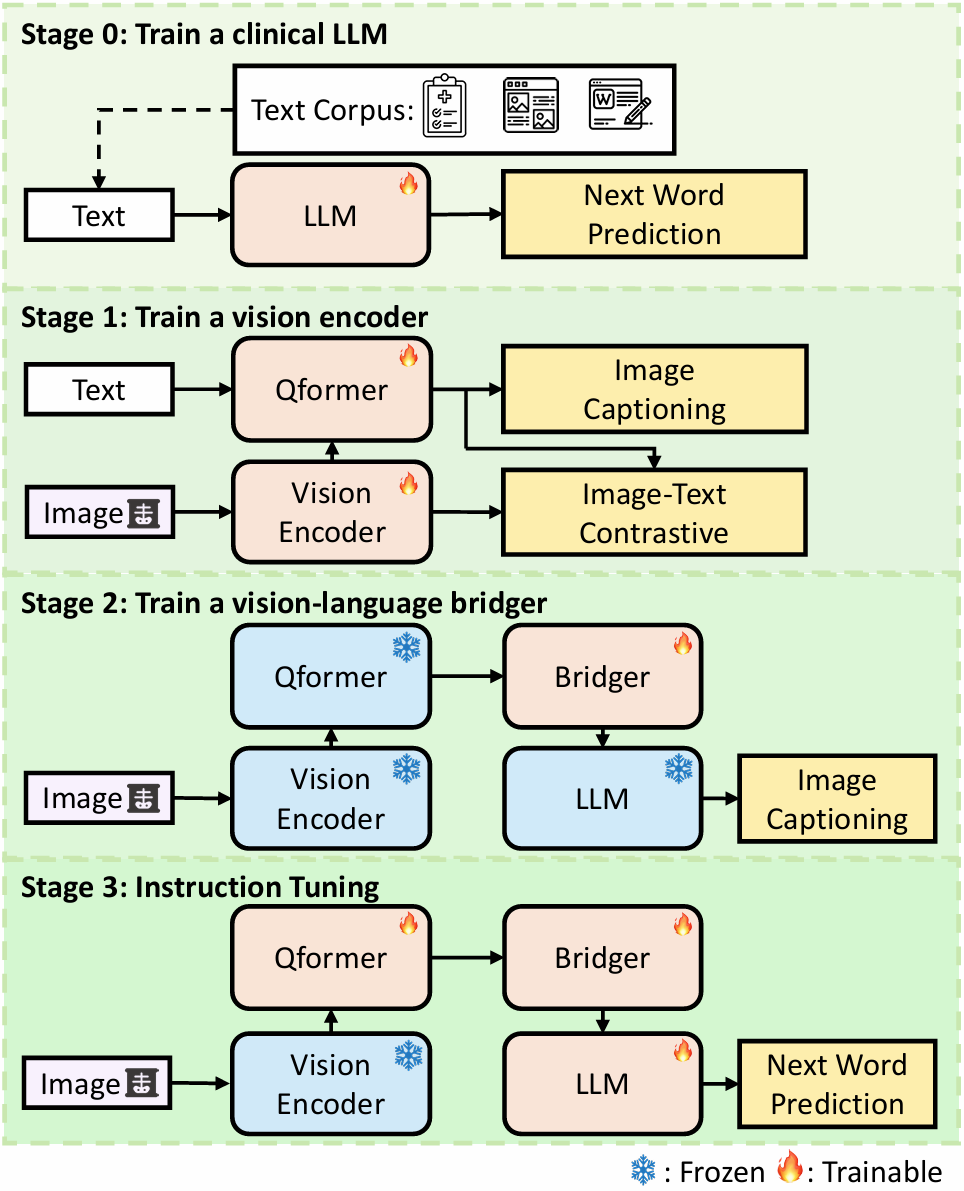
Large vision language models (VLMs) have progressed incredibly from research to applicability for general-purpose use cases. LLaVA-Med, a pioneering large language and vision assistant for biomedicine, can perform multi-modal biomedical image and data analysis to provide a natural language interface for radiologists. While it is highly generalizable and works with multi-modal data, it is currently limited by well-known challenges that exist in the large language model space. Hallucinations and imprecision in responses can lead to misdiagnosis which currently hinder the clinical adaptability of VLMs. To create precise, user-friendly models in healthcare, we propose D-Rax -- a domain-specific, conversational, radiologic assistance tool that can be used to gain insights about a particular radiologic image. In this study, we enhance the conversational analysis of chest X-ray (CXR) images to support radiological reporting, offering comprehensive insights from medical imaging and aiding in the formulation of accurate diagnosis. D-Rax is achieved by fine-tuning the LLaVA-Med architecture on our curated enhanced instruction-following data, comprising of images, instructions, as well as disease diagnosis and demographic predictions derived from MIMIC-CXR imaging data, CXR-related visual question answer (VQA) pairs, and predictive outcomes from multiple expert AI models. We observe statistically significant improvement in responses when evaluated for both open and close-ended conversations. Leveraging the power of state-of-the-art diagnostic models combined with VLMs, D-Rax empowers clinicians to interact with medical images using natural language, which could potentially streamline their decision-making process, enhance diagnostic accuracy, and conserve their time.
Read more8/6/2024
0
CXR-Agent: Vision-language models for chest X-ray interpretation with uncertainty aware radiology reporting
Naman Sharma
Recently large vision-language models have shown potential when interpreting complex images and generating natural language descriptions using advanced reasoning. Medicine's inherently multimodal nature incorporating scans and text-based medical histories to write reports makes it conducive to benefit from these leaps in AI capabilities. We evaluate the publicly available, state of the art, foundational vision-language models for chest X-ray interpretation across several datasets and benchmarks. We use linear probes to evaluate the performance of various components including CheXagent's vision transformer and Q-former, which outperform the industry-standard Torch X-ray Vision models across many different datasets showing robust generalisation capabilities. Importantly, we find that vision-language models often hallucinate with confident language, which slows down clinical interpretation. Based on these findings, we develop an agent-based vision-language approach for report generation using CheXagent's linear probes and BioViL-T's phrase grounding tools to generate uncertainty-aware radiology reports with pathologies localised and described based on their likelihood. We thoroughly evaluate our vision-language agents using NLP metrics, chest X-ray benchmarks and clinical evaluations by developing an evaluation platform to perform a user study with respiratory specialists. Our results show considerable improvements in accuracy, interpretability and safety of the AI-generated reports. We stress the importance of analysing results for normal and abnormal scans separately. Finally, we emphasise the need for larger paired (scan and report) datasets alongside data augmentation to tackle overfitting seen in these large vision-language models.
Read more7/15/2024

0
Beyond the Hype: A dispassionate look at vision-language models in medical scenario
Yang Nan, Huichi Zhou, Xiaodan Xing, Guang Yang
Recent advancements in Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities across diverse tasks, garnering significant attention in AI communities. However, their performance and reliability in specialized domains such as medicine remain insufficiently assessed. In particular, most assessments over-concentrate in evaluating VLMs based on simple Visual Question Answering (VQA) on multi-modality data, while ignoring the in-depth characteristic of LVLMs. In this study, we introduce RadVUQA, a novel Radiological Visual Understanding and Question Answering benchmark, to comprehensively evaluate existing LVLMs. RadVUQA mainly validates LVLMs across five dimensions: 1) Anatomical understanding, assessing the models' ability to visually identify biological structures; 2) Multimodal comprehension, which involves the capability of interpreting linguistic and visual instructions to produce desired outcomes; 3) Quantitative and spatial reasoning, evaluating the models' spatial awareness and proficiency in combining quantitative analysis with visual and linguistic information; 4) Physiological knowledge, measuring the models' capability to comprehend functions and mechanisms of organs and systems; and 5) Robustness, which assesses the models' capabilities against unharmonised and synthetic data. The results indicate that both generalized LVLMs and medical-specific LVLMs have critical deficiencies with weak multimodal comprehension and quantitative reasoning capabilities. Our findings reveal the large gap between existing LVLMs and clinicians, highlighting the urgent need for more robust and intelligent LVLMs. The code and dataset will be available after the acceptance of this paper.
Read more8/19/2024
0
MedXChat: A Unified Multimodal Large Language Model Framework towards CXRs Understanding and Generation
Ling Yang, Zhanyu Wang, Zhenghao Chen, Xinyu Liang, Luping Zhou
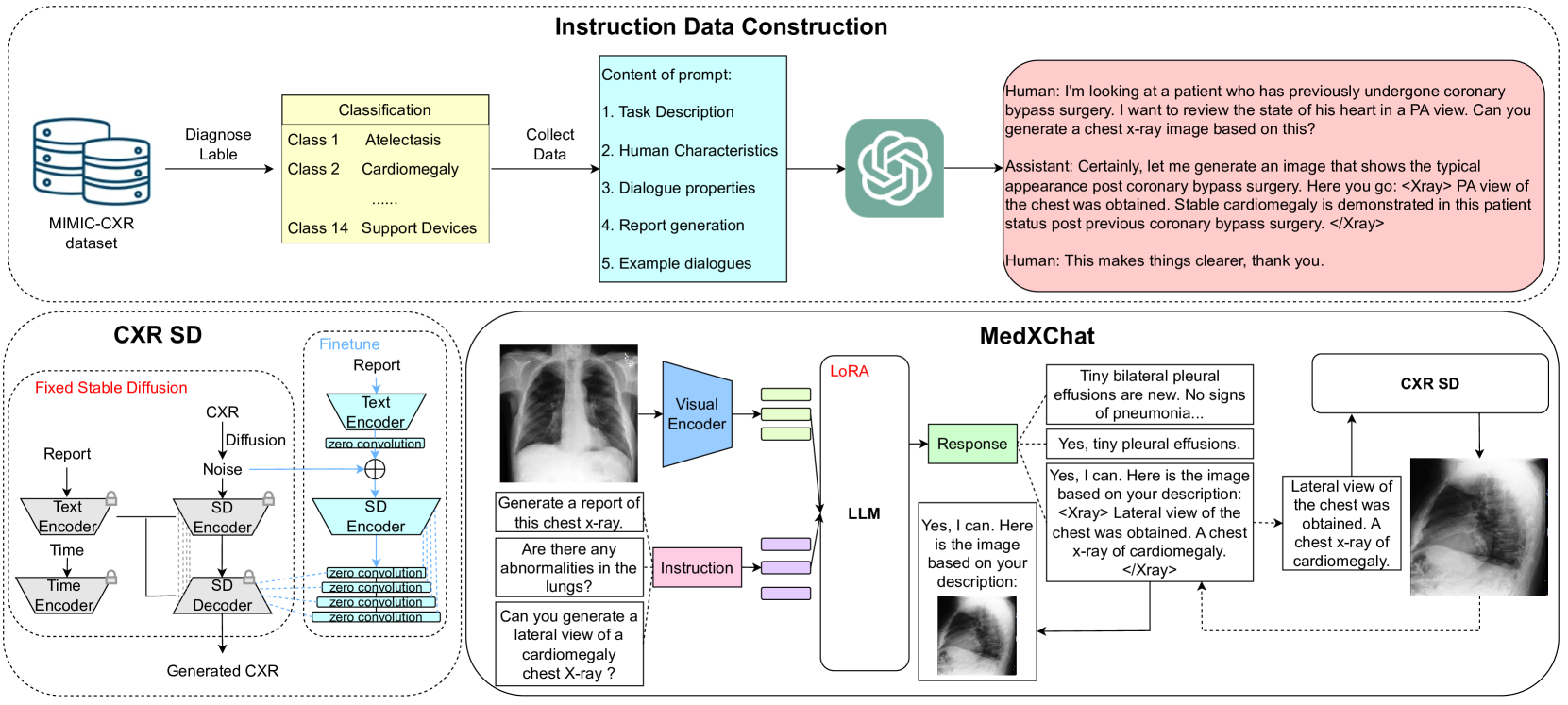
Multimodal Large Language Models (MLLMs) have shown success in various general image processing tasks, yet their application in medical imaging is nascent, lacking tailored models. This study investigates the potential of MLLMs in improving the understanding and generation of Chest X-Rays (CXRs). We introduce MedXChat, a unified framework facilitating seamless interactions between medical assistants and users for diverse CXR tasks, including text report generation, visual question-answering (VQA), and Text-to-CXR generation. Our MLLMs using natural language as the input breaks task boundaries, maximally simplifying medical professional training by allowing diverse tasks within a single environment. For CXR understanding, we leverage powerful off-the-shelf visual encoders (e.g., ViT) and LLMs (e.g., mPLUG-Owl) to convert medical imagery into language-like features, and subsequently fine-tune our large pre-trained models for medical applications using a visual adapter network and a delta-tuning approach. For CXR generation, we introduce an innovative synthesis approach that utilizes instruction-following capabilities within the Stable Diffusion (SD) architecture. This technique integrates smoothly with the existing model framework, requiring no extra parameters, thereby maintaining the SD's generative strength while also bestowing upon it the capacity to render fine-grained medical images with high fidelity. Through comprehensive experiments, our model demonstrates exceptional cross-task adaptability, displaying adeptness across all three defined tasks. Our MedXChat model and the instruction dataset utilized in this research will be made publicly available to encourage further exploration in the field.
Read more5/13/2024