Deep Bayesian Reinforcement Learning for Spacecraft Proximity Maneuvers and Docking

0
🤿
Sign in to get full access
Overview
- Introduces a novel Bayesian actor-critic reinforcement learning algorithm to learn a control policy for autonomous spacecraft proximity maneuvers and docking with stability guarantees.
- Formulates the proximity maneuver and docking task as a Markov decision process that accounts for the relative dynamic model, docking constraints, and cost function.
- Leverages principles from Lyapunov theory to frame the temporal difference learning as a constrained Gaussian process regression problem, enabling the state-value function to be expressed as a Lyapunov function.
- Develops a Bayesian quadrature policy optimization procedure to analytically compute the policy gradient while integrating Lyapunov-based stability constraints.
- Experimentally evaluates the proposed algorithm on a spacecraft air-bearing testbed with promising performance.
Plain English Explanation
The paper introduces a new machine learning approach to help spacecraft perform precise maneuvering and docking tasks autonomously. The researchers formulated this task as a type of decision-making problem called a Markov decision process, which captures the dynamics of the spacecraft, the constraints of the docking process, and the desired performance objectives.
To solve this decision-making problem, the researchers developed a novel reinforcement learning algorithm. Reinforcement learning is a machine learning technique where an agent (in this case, the spacecraft) learns how to act in an environment by trial-and-error and receiving rewards or penalties for its actions.
The key innovation in this paper is the integration of Lyapunov stability theory into the reinforcement learning algorithm. Lyapunov theory provides a way to ensure the long-term stability and safety of the spacecraft's control policy, which is critical for real-world space missions. The researchers achieved this by framing the reinforcement learning problem as a type of constrained optimization that satisfies the Lyapunov stability conditions.
The proposed algorithm was implemented and tested on a spacecraft simulator, demonstrating promising results in terms of the spacecraft's ability to safely and accurately perform proximity maneuvers and docking. This work represents an important step towards more autonomous and reliable spacecraft operations, which could enable future space exploration missions to be more cost-effective and flexible.
Technical Explanation
The researchers formulated the proximity maneuver and docking (PMD) task as a Markov decision process (MDP), which captures the relative dynamic model of the spacecraft, the docking constraints (represented by a "docking cone"), and a cost function that encodes the desired performance objectives.
To solve this MDP, the researchers developed a novel Bayesian actor-critic reinforcement learning algorithm. The core innovation is the integration of principles from Lyapunov stability theory into the temporal difference learning process. Specifically, the researchers framed the temporal difference learning as a constrained Gaussian process regression problem, which allows the state-value function to be expressed as a Lyapunov function.
This formulation enables the researchers to develop a Bayesian quadrature policy optimization procedure that analytically computes the policy gradient while ensuring Lyapunov-based stability constraints are satisfied. The Bayesian quadrature approach allows for efficient policy optimization that is robust to modeling uncertainties.
The proposed algorithm was experimentally evaluated on a spacecraft air-bearing testbed, which demonstrated impressive and promising performance in terms of the spacecraft's ability to safely and accurately perform proximity maneuvers and docking. This work represents an important advancement in ensuring the safety and reliability of autonomous spacecraft operations.
Critical Analysis
The paper presents a compelling approach to addressing the critical challenge of ensuring the safety and stability of autonomous spacecraft proximity maneuvers and docking. By integrating Lyapunov stability theory into the reinforcement learning framework, the researchers have developed a novel algorithm that can learn control policies that provably satisfy safety constraints.
One potential limitation of the work is the reliance on a Gaussian process model for the spacecraft dynamics. While this allows for analytical tractability in the policy optimization, it may not fully capture the complexities of real-world spacecraft dynamics, particularly in the face of disturbances or modeling uncertainties. Further research may be needed to extend the approach to handle more general non-Gaussian dynamics.
Additionally, the experimental evaluation was conducted on a spacecraft air-bearing testbed, which, while useful for validating the approach, may not fully reflect the challenges of real-world space environments. Extensive testing and validation on high-fidelity simulations or even actual spacecraft platforms would be an important next step to further assess the practical applicability of the proposed algorithm.
Overall, this work represents an important contribution to the field of autonomous spacecraft control, demonstrating the potential of integrating principles from control theory and machine learning to develop safe and reliable decision-making algorithms for critical space applications.
Conclusion
This paper introduces a novel Bayesian actor-critic reinforcement learning algorithm that integrates Lyapunov stability theory to learn control policies for autonomous spacecraft proximity maneuvers and docking. By formulating the task as a Markov decision process and leveraging constrained Gaussian process regression, the researchers have developed a framework that can provably satisfy the stringent safety requirements of real-world space missions.
The experimental evaluation of the proposed algorithm on a spacecraft air-bearing testbed has yielded promising results, highlighting the potential of this approach to enable more autonomous and reliable spacecraft operations. As the space industry continues to push the boundaries of what is possible with increasingly complex and ambitious missions, advancements like this in safe and stable decision-making algorithms will be crucial to realizing the full potential of autonomous spacecraft capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Deep Bayesian Reinforcement Learning for Spacecraft Proximity Maneuvers and Docking
Desong Du, Naiming Qi, Yanfang Liu, Wei Pan
In the pursuit of autonomous spacecraft proximity maneuvers and docking(PMD), we introduce a novel Bayesian actor-critic reinforcement learning algorithm to learn a control policy with the stability guarantee. The PMD task is formulated as a Markov decision process that reflects the relative dynamic model, the docking cone and the cost function. Drawing from the principles of Lyapunov theory, we frame the temporal difference learning as a constrained Gaussian process regression problem. This innovative approach allows the state-value function to be expressed as a Lyapunov function, leveraging the Gaussian process and deep kernel learning. We develop a novel Bayesian quadrature policy optimization procedure to analytically compute the policy gradient while integrating Lyapunov-based stability constraints. This integration is pivotal in satisfying the rigorous safety demands of spaceflight missions. The proposed algorithm has been experimentally evaluated on a spacecraft air-bearing testbed and shows impressive and promising performance.
Read more5/24/2024

0
Trajectory Planning for Teleoperated Space Manipulators Using Deep Reinforcement Learning
Bo Xia, Xianru Tian, Bo Yuan, Zhiheng Li, Bin Liang, Xueqian Wang
Trajectory planning for teleoperated space manipulators involves challenges such as accurately modeling system dynamics, particularly in free-floating modes with non-holonomic constraints, and managing time delays that increase model uncertainty and affect control precision. Traditional teleoperation methods rely on precise dynamic models requiring complex parameter identification and calibration, while data-driven methods do not require prior knowledge but struggle with time delays. A novel framework utilizing deep reinforcement learning (DRL) is introduced to address these challenges. The framework incorporates three methods: Mapping, Prediction, and State Augmentation, to handle delays when delayed state information is received at the master end. The Soft Actor Critic (SAC) algorithm processes the state information to compute the next action, which is then sent to the remote manipulator for environmental interaction. Four environments are constructed using the MuJoCo simulation platform to account for variations in base and target fixation: fixed base and target, fixed base with rotated target, free-floating base with fixed target, and free-floating base with rotated target. Extensive experiments with both constant and random delays are conducted to evaluate the proposed methods. Results demonstrate that all three methods effectively address trajectory planning challenges, with State Augmentation showing superior efficiency and robustness.
Read more8/13/2024

0
Deep Reinforcement Learning for Sim-to-Real Policy Transfer of VTOL-UAVs Offshore Docking Operations
Ali M. Ali, Aryaman Gupta, Hashim A. Hashim
This paper proposes a novel Reinforcement Learning (RL) approach for sim-to-real policy transfer of Vertical Take-Off and Landing Unmanned Aerial Vehicle (VTOL-UAV). The proposed approach is designed for VTOL-UAV landing on offshore docking stations in maritime operations. VTOL-UAVs in maritime operations encounter limitations in their operational range, primarily stemming from constraints imposed by their battery capacity. The concept of autonomous landing on a charging platform presents an intriguing prospect for mitigating these limitations by facilitating battery charging and data transfer. However, current Deep Reinforcement Learning (DRL) methods exhibit drawbacks, including lengthy training times, and modest success rates. In this paper, we tackle these concerns comprehensively by decomposing the landing procedure into a sequence of more manageable but analogous tasks in terms of an approach phase and a landing phase. The proposed architecture utilizes a model-based control scheme for the approach phase, where the VTOL-UAV is approaching the offshore docking station. In the Landing phase, DRL agents were trained offline to learn the optimal policy to dock on the offshore station. The Joint North Sea Wave Project (JONSWAP) spectrum model has been employed to create a wave model for each episode, enhancing policy generalization for sim2real transfer. A set of DRL algorithms have been tested through numerical simulations including value-based agents and policy-based agents such as Deep textit{Q} Networks (DQN) and Proximal Policy Optimization (PPO) respectively. The numerical experiments show that the PPO agent can learn complicated and efficient policies to land in uncertain environments, which in turn enhances the likelihood of successful sim-to-real transfer.
Read more8/1/2024
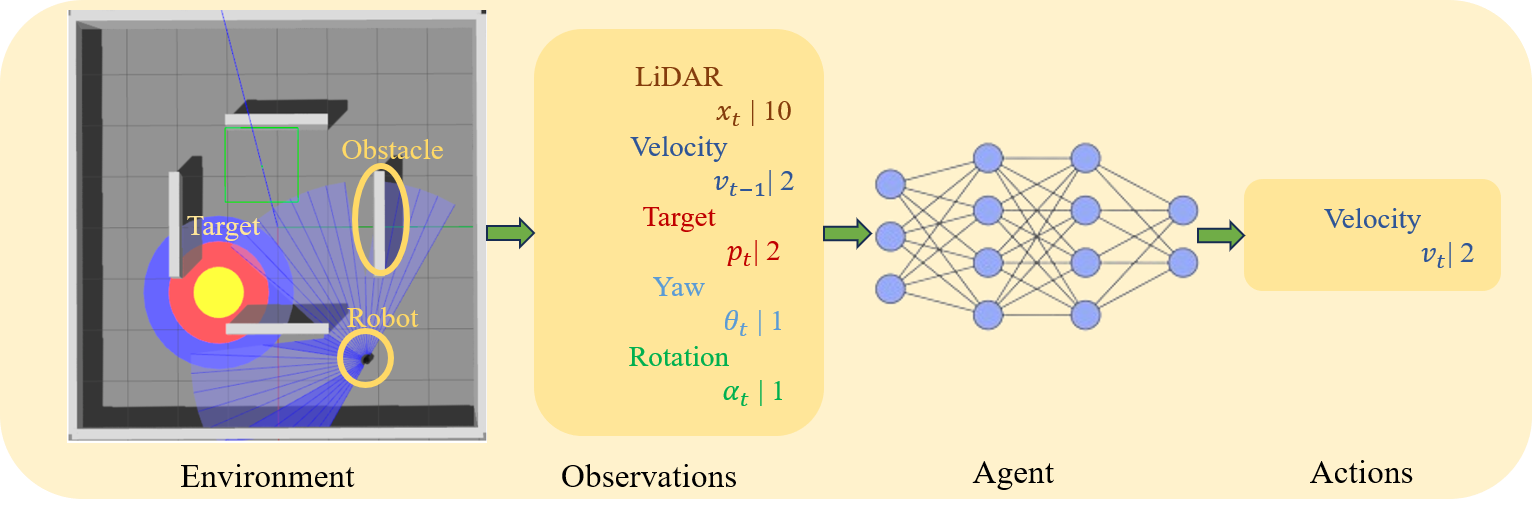
0
Deep Reinforcement Learning with Enhanced PPO for Safe Mobile Robot Navigation
Hamid Taheri, Seyed Rasoul Hosseini, Mohammad Ali Nekoui
Collision-free motion is essential for mobile robots. Most approaches to collision-free and efficient navigation with wheeled robots require parameter tuning by experts to obtain good navigation behavior. This study investigates the application of deep reinforcement learning to train a mobile robot for autonomous navigation in a complex environment. The robot utilizes LiDAR sensor data and a deep neural network to generate control signals guiding it toward a specified target while avoiding obstacles. We employ two reinforcement learning algorithms in the Gazebo simulation environment: Deep Deterministic Policy Gradient and proximal policy optimization. The study introduces an enhanced neural network structure in the Proximal Policy Optimization algorithm to boost performance, accompanied by a well-designed reward function to improve algorithm efficacy. Experimental results conducted in both obstacle and obstacle-free environments underscore the effectiveness of the proposed approach. This research significantly contributes to the advancement of autonomous robotics in complex environments through the application of deep reinforcement learning.
Read more8/9/2024