Deep Learning and LLM-based Methods Applied to Stellar Lightcurve Classification
2404.10757
0
0
Abstract
Light curves serve as a valuable source of information on stellar formation and evolution. With the rapid advancement of machine learning techniques, it can be effectively processed to extract astronomical patterns and information. In this study, we present a comprehensive evaluation of deep-learning and large language model (LLM) based models for the automatic classification of variable star light curves, based on large datasets from the Kepler and K2 missions. Special emphasis is placed on Cepheids, RR Lyrae, and eclipsing binaries, examining the influence of observational cadence and phase distribution on classification precision. Employing AutoDL optimization, we achieve striking performance with the 1D-Convolution+BiLSTM architecture and the Swin Transformer, hitting accuracies of 94% and 99% correspondingly, with the latter demonstrating a notable 83% accuracy in discerning the elusive Type II Cepheids-comprising merely 0.02% of the total dataset.We unveil StarWhisper LightCurve (LC), an innovative Series comprising three LLM-based models: LLM, multimodal large language model (MLLM), and Large Audio Language Model (LALM). Each model is fine-tuned with strategic prompt engineering and customized training methods to explore the emergent abilities of these models for astronomical data. Remarkably, StarWhisper LC Series exhibit high accuracies around 90%, significantly reducing the need for explicit feature engineering, thereby paving the way for streamlined parallel data processing and the progression of multifaceted multimodal models in astronomical applications. The study furnishes two detailed catalogs illustrating the impacts of phase and sampling intervals on deep learning classification accuracy, showing that a substantial decrease of up to 14% in observation duration and 21% in sampling points can be realized without compromising accuracy by more than 10%.
Create account to get full access
Overview
- This paper explores the use of deep learning and large language model (LLM) techniques for classifying stellar light curves, which are measurements of the brightness of stars over time.
- The researchers investigate several different deep learning and LLM-based approaches and evaluate their performance on a dataset of Kepler and K2 mission stellar light curves.
- The findings provide insights into the potential of these advanced machine learning methods for automating the analysis of astronomical data and improving our understanding of stellar phenomena.
Plain English Explanation
The paper focuses on using modern machine learning techniques, specifically deep learning and large language models (LLMs), to classify different types of stellar light curves. Stellar light curves are graphs that show how the brightness of a star changes over time, and they can provide valuable insights into the nature and behavior of these celestial objects.
The researchers tested various deep learning and LLM-based approaches on a dataset of light curves collected by the Kepler and K2 space telescopes. These sophisticated machine learning models were able to automatically recognize patterns and features in the light curve data, which could then be used to categorize the stars into different classes, such as pulsating variables, eclipsing binaries, or transiting exoplanets.
By transforming LLMs into cross-modal and cross-lingual models, the researchers found they could leverage the powerful natural language processing capabilities of LLMs to enhance the performance of their stellar classification system. The ability of large language models to automatically engineer features from the light curve data also played a key role in the success of their approach.
Overall, this research demonstrates the potential of multi-modal large language and vision models to revolutionize the analysis of astronomical data and improve our understanding of the diverse phenomena occurring in the universe.
Technical Explanation
The paper describes the use of deep learning and LLM-based methods for the classification of stellar light curves obtained from the Kepler and K2 space missions. The researchers explored several different approaches, including convolutional neural networks (CNNs), long short-term memory (LSTMs) networks, and transformer-based language models.
To leverage the power of LLMs, the team transformed the models into cross-modal and cross-lingual architectures, allowing them to process both the time-series light curve data and associated metadata, such as the star's coordinates and other properties. They also harnessed the ability of large language models to automatically engineer features from the input data, which further enhanced the performance of their classification system.
The researchers evaluated their deep learning and LLM-based methods on a dataset of over 200,000 stellar light curves, covering a diverse range of stellar variability types. They found that the transformer-based language models, particularly when combined with the cross-modal and feature engineering capabilities, outperformed the more traditional deep learning architectures, achieving state-of-the-art classification accuracy.
Critical Analysis
The paper provides a comprehensive and well-designed study, demonstrating the effectiveness of deep learning and LLM-based approaches for stellar light curve classification. However, there are a few caveats and areas for further research that could be considered:
-
The dataset used in the study, while large, may not be fully representative of the diversity of stellar light curves observed in the universe. Expanding the evaluation to include a wider range of stellar types and variability patterns could help validate the generalizability of the proposed methods.
-
The paper does not delve deeply into the interpretability of the trained models, i.e., the ability to understand the specific features and patterns that the models are using to make their classifications. Improving the interpretability of large language models could lead to further insights into the underlying stellar physics.
-
The performance of the LLM-based methods is impressive, but the computational and memory requirements of these models may limit their practical deployment in resource-constrained astronomical observatories. Exploring strategies to distill the knowledge from large language models into more efficient architectures could be a valuable direction for future research.
Conclusion
This paper demonstrates the powerful capabilities of deep learning and LLM-based techniques for the classification of stellar light curves, a critical task in the field of astronomy. By leveraging the cross-modal and feature engineering abilities of large language models, the researchers have pushed the state-of-the-art in automated stellar analysis, paving the way for more efficient and accurate exploration of the diverse phenomena occurring in our universe. The findings of this study have significant implications for the future of astronomical data processing and our understanding of the stars.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

The Scaling Law in Stellar Light Curves
Jia-Shu Pan, Yuan-Sen Ting, Yang Huang, Jie Yu, Ji-Feng Liu
0
0
Analyzing time series of fluxes from stars, known as stellar light curves, can reveal valuable information about stellar properties. However, most current methods rely on extracting summary statistics, and studies using deep learning have been limited to supervised approaches. In this research, we investigate the scaling law properties that emerge when learning from astronomical time series data using self-supervised techniques. By employing the GPT-2 architecture, we show the learned representation improves as the number of parameters increases from $10^4$ to $10^9$, with no signs of performance plateauing. We demonstrate that a self-supervised Transformer model achieves 3-10 times the sample efficiency compared to the state-of-the-art supervised learning model when inferring the surface gravity of stars as a downstream task. Our research lays the groundwork for analyzing stellar light curves by examining them through large-scale auto-regressive generative models.
6/18/2024
🔎
Machine learning for exoplanet detection in high-contrast spectroscopy Combining cross correlation maps and deep learning on medium-resolution integral-field spectra
Rakesh Nath-Ranga, Olivier Absil, Valentin Christiaens, Emily O. Garvin
0
0
The advent of high-contrast imaging instruments combined with medium-resolution spectrographs allows spectral and temporal dimensions to be combined with spatial dimensions to detect and potentially characterize exoplanets with higher sensitivity. We develop a new method to effectively leverage the spectral and spatial dimensions in integral-field spectroscopy (IFS) datasets using a supervised deep-learning algorithm to improve the detection sensitivity to high-contrast exoplanets. We begin by applying a data transform whereby the IFS datasets are replaced by cross-correlation coefficient tensors obtained by cross-correlating our data with young gas giant spectral template spectra. This transformed data is then used to train machine learning (ML) algorithms. We train a 2D CNN and 3D LSTM with our data. We compare the ML models with a non-ML algorithm, based on the STIM map of arXiv:1810.06895. We test our algorithms on simulated young gas giants in a dataset that contains no known exoplanet, and explore the sensitivity of algorithms to detect these exoplanets at contrasts ranging from 1e-3 to 1e-4 at different radial separations. We quantify the sensitivity using modified receiver operating characteristic curves (mROC). We discover that the ML algorithms produce fewer false positives and have a higher true positive rate than the STIM-based algorithm, and the true positive rate of ML algorithms is less impacted by changing radial separation. We discover that the velocity dimension is an important differentiating factor. Through this paper, we demonstrate that ML techniques have the potential to improve the detection limits and reduce false positives for directly imaged planets in IFS datasets, after transforming the spectral dimension into a radial velocity dimension through a cross-correlation operation.
5/24/2024
🤿
Using autoencoders and deep transfer learning to determine the stellar parameters of 286 CARMENES M dwarfs
P. Mas-Buitrago, A. Gonz'alez-Marcos, E. Solano, V. M. Passegger, M. Cort'es-Contreras, J. Ordieres-Mer'e, A. Bello-Garc'ia, J. A. Caballero, A. Schweitzer, H. M. Tabernero, D. Montes, C. Cifuentes
0
0
Deep learning (DL) techniques are a promising approach among the set of methods used in the ever-challenging determination of stellar parameters in M dwarfs. In this context, transfer learning could play an important role in mitigating uncertainties in the results due to the synthetic gap (i.e. difference in feature distributions between observed and synthetic data). We propose a feature-based deep transfer learning (DTL) approach based on autoencoders to determine stellar parameters from high-resolution spectra. Using this methodology, we provide new estimations for the effective temperature, surface gravity, metallicity, and projected rotational velocity for 286 M dwarfs observed by the CARMENES survey. Using autoencoder architectures, we projected synthetic PHOENIX-ACES spectra and observed CARMENES spectra onto a new feature space of lower dimensionality in which the differences between the two domains are reduced. We used this low-dimensional new feature space as input for a convolutional neural network to obtain the stellar parameter determinations. We performed an extensive analysis of our estimated stellar parameters, ranging from 3050 to 4300 K, 4.7 to 5.1 dex, and -0.53 to 0.25 dex for Teff, logg, and [Fe/H], respectively. Our results are broadly consistent with those of recent studies using CARMENES data, with a systematic deviation in our Teff scale towards hotter values for estimations above 3750 K. Furthermore, our methodology mitigates the deviations in metallicity found in previous DL techniques due to the synthetic gap. We consolidated a DTL-based methodology to determine stellar parameters in M dwarfs from synthetic spectra, with no need for high-quality measurements involved in the knowledge transfer. These results suggest the great potential of DTL to mitigate the differences in feature distributions between the observations and the PHOENIX-ACES spectra.
5/15/2024
UnibucLLM: Harnessing LLMs for Automated Prediction of Item Difficulty and Response Time for Multiple-Choice Questions
Ana-Cristina Rogoz, Radu Tudor Ionescu
0
0
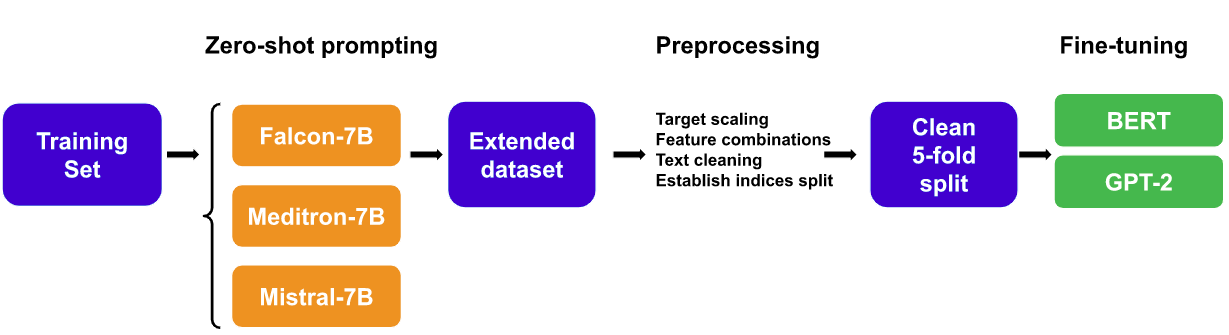
This work explores a novel data augmentation method based on Large Language Models (LLMs) for predicting item difficulty and response time of retired USMLE Multiple-Choice Questions (MCQs) in the BEA 2024 Shared Task. Our approach is based on augmenting the dataset with answers from zero-shot LLMs (Falcon, Meditron, Mistral) and employing transformer-based models based on six alternative feature combinations. The results suggest that predicting the difficulty of questions is more challenging. Notably, our top performing methods consistently include the question text, and benefit from the variability of LLM answers, highlighting the potential of LLMs for improving automated assessment in medical licensing exams. We make our code available https://github.com/ana-rogoz/BEA-2024.
4/23/2024