Deep-PE: A Learning-Based Pose Evaluator for Point Cloud Registration

0

Sign in to get full access
Overview
- This paper proposes Deep-PE, a deep learning-based approach for evaluating the quality of point cloud registration.
- Point cloud registration is the process of aligning two or more 3D point clouds, which is a fundamental task in computer vision and robotics.
- Deep-PE aims to predict a registration quality score that can be used to assess the accuracy of the registration result, without ground truth information.
Plain English Explanation
The paper introduces a new method called Deep-PE that uses deep learning to assess the quality of point cloud registration. Point cloud registration is an important task in computer vision and robotics where researchers try to align two or more 3D point clouds, which are collections of 3D points that represent the surface of an object or environment.
Evaluating the accuracy of point cloud registration is challenging because it often requires having access to the "ground truth" - the correct, ideal alignment of the point clouds. Deep-PE aims to solve this problem by training a deep neural network to predict a quality score that indicates how well the point clouds have been registered, without needing the ground truth information.
The key idea is that the neural network can learn to recognize patterns in well-registered point clouds and use that knowledge to assess the quality of new registrations. This could be very useful in practical applications where the ground truth is not available, as it allows researchers to automatically evaluate their registration algorithms.
Technical Explanation
The authors of the paper propose a deep learning-based approach called Deep-PE that can evaluate the quality of point cloud registration without access to ground truth information. The method takes in the source and target point clouds, as well as the estimated transformation (rotation and translation) that aligns them, and outputs a quality score that indicates how accurate the registration is.
The Deep-PE architecture consists of a PointNet-based PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation backbone that encodes the input point clouds, combined with a multi-layer perceptron that processes the encoded features and the transformation parameters to predict the quality score.
The authors train and evaluate Deep-PE on several benchmark datasets for point cloud registration, including Augmented Reality Datasets for Deep Learning on Point Clouds, FreeReg: Image-to-Point Cloud Registration Leveraging Free-Form Descriptors, and a comprehensive survey and taxonomy of point cloud registration. They show that Deep-PE can accurately predict registration quality, outperforming traditional methods that rely on geometric features.
Critical Analysis
The authors acknowledge that Deep-PE has some limitations. For example, the method may not perform as well on highly noisy or sparse point clouds, as the neural network may struggle to extract meaningful features from the data. Additionally, the authors note that the performance of Deep-PE depends on the quality and diversity of the training data, which may be difficult to obtain in some real-world scenarios.
Another potential issue is that Deep-PE is a "black box" model, meaning that it is not always clear how the neural network is making its predictions. This can make it difficult to understand the underlying factors that contribute to the quality assessment, which could be important for debugging or improving the method.
While the results of the paper are promising, further research is needed to address these limitations and expand the applicability of Deep-PE to a wider range of point cloud registration scenarios, such as those encountered in benchmarking classical and learning-based multibeam point cloud registration or fine-grained, prompt-driven 3D human pose estimation.
Conclusion
The Deep-PE approach proposed in this paper represents a significant advance in the field of point cloud registration evaluation. By using deep learning to predict registration quality without ground truth information, Deep-PE can simplify the evaluation process and enable more robust and reliable point cloud registration pipelines.
While the method has some limitations that require further research, the core idea of leveraging neural networks to assess registration quality is a promising direction that could have far-reaching implications for a wide range of computer vision and robotics applications. As the field of 3D perception continues to evolve, tools like Deep-PE will become increasingly important for enabling accurate and efficient 3D data processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Deep-PE: A Learning-Based Pose Evaluator for Point Cloud Registration
Junjie Gao, Chongjian Wang, Zhongjun Ding, Shuangmin Chen, Shiqing Xin, Changhe Tu, Wenping Wang
In the realm of point cloud registration, the most prevalent pose evaluation approaches are statistics-based, identifying the optimal transformation by maximizing the number of consistent correspondences. However, registration recall decreases significantly when point clouds exhibit a low overlap rate, despite efforts in designing feature descriptors and establishing correspondences. In this paper, we introduce Deep-PE, a lightweight, learning-based pose evaluator designed to enhance the accuracy of pose selection, especially in challenging point cloud scenarios with low overlap. Our network incorporates a Pose-Aware Attention (PAA) module to simulate and learn the alignment status of point clouds under various candidate poses, alongside a Pose Confidence Prediction (PCP) module that predicts the likelihood of successful registration. These two modules facilitate the learning of both local and global alignment priors. Extensive tests across multiple benchmarks confirm the effectiveness of Deep-PE. Notably, on 3DLoMatch with a low overlap rate, Deep-PE significantly outperforms state-of-the-art methods by at least 8% and 11% in registration recall under handcrafted FPFH and learning-based FCGF descriptors, respectively. To the best of our knowledge, this is the first study to utilize deep learning to select the optimal pose without the explicit need for input correspondences.
Read more5/28/2024
🤿
0
Deep Learning-based Point Cloud Registration for Augmented Reality-guided Surgery
Maximilian Weber, Daniel Wild, Jens Kleesiek, Jan Egger, Christina Gsaxner
Point cloud registration aligns 3D point clouds using spatial transformations. It is an important task in computer vision, with applications in areas such as augmented reality (AR) and medical imaging. This work explores the intersection of two research trends: the integration of AR into image-guided surgery and the use of deep learning for point cloud registration. The main objective is to evaluate the feasibility of applying deep learning-based point cloud registration methods for image-to-patient registration in augmented reality-guided surgery. We created a dataset of point clouds from medical imaging and corresponding point clouds captured with a popular AR device, the HoloLens 2. We evaluate three well-established deep learning models in registering these data pairs. While we find that some deep learning methods show promise, we show that a conventional registration pipeline still outperforms them on our challenging dataset.
Read more5/7/2024

0
MaFreeI2P: A Matching-Free Image-to-Point Cloud Registration Paradigm with Active Camera Pose Retrieval
Gongxin Yao, Xinyang Li, Yixin Xuan, Yu Pan
Image-to-point cloud registration seeks to estimate their relative camera pose, which remains an open question due to the data modality gaps. The recent matching-based methods tend to tackle this by building 2D-3D correspondences. In this paper, we reveal the information loss inherent in these methods and propose a matching-free paradigm, named MaFreeI2P. Our key insight is to actively retrieve the camera pose in SE(3) space by contrasting the geometric features between the point cloud and the query image. To achieve this, we first sample a set of candidate camera poses and construct their cost volume using the cross-modal features. Superior to matching, cost volume can preserve more information and its feature similarity implicitly reflects the confidence level of the sampled poses. Afterwards, we employ a convolutional network to adaptively formulate a similarity assessment function, where the input cost volume is further improved by filtering and pose-based weighting. Finally, we update the camera pose based on the similarity scores, and adopt a heuristic strategy to iteratively shrink the pose sampling space for convergence. Our MaFreeI2P achieves a very competitive registration accuracy and recall on the KITTI-Odometry and Apollo-DaoxiangLake datasets.
Read more8/6/2024
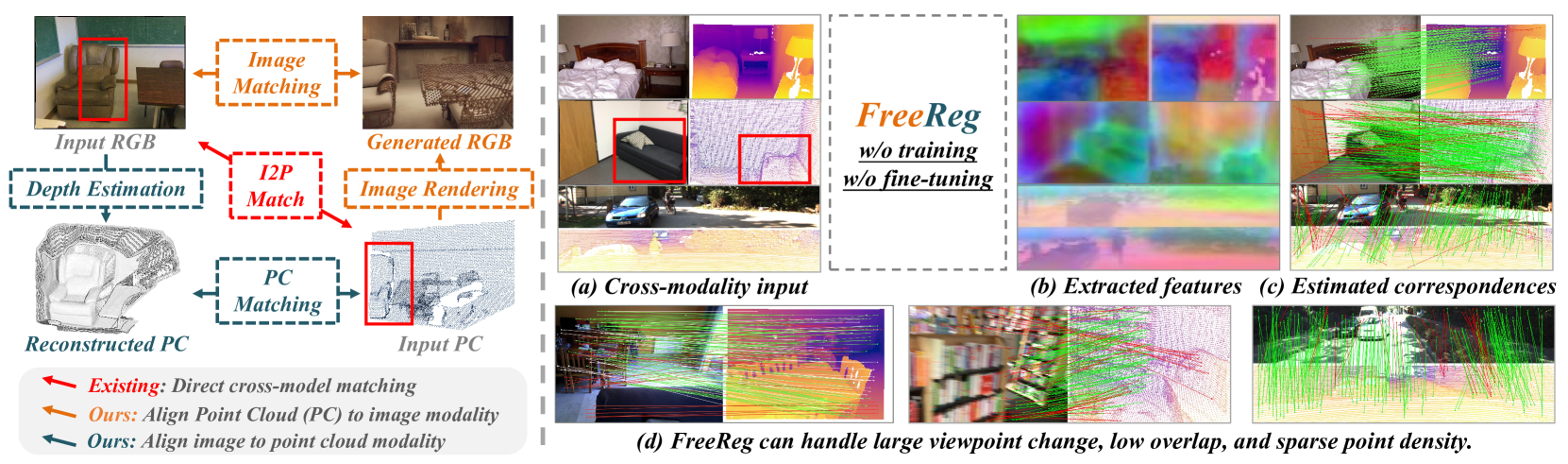
0
FreeReg: Image-to-Point Cloud Registration Leveraging Pretrained Diffusion Models and Monocular Depth Estimators
Haiping Wang, Yuan Liu, Bing Wang, Yujing Sun, Zhen Dong, Wenping Wang, Bisheng Yang
Matching cross-modality features between images and point clouds is a fundamental problem for image-to-point cloud registration. However, due to the modality difference between images and points, it is difficult to learn robust and discriminative cross-modality features by existing metric learning methods for feature matching. Instead of applying metric learning on cross-modality data, we propose to unify the modality between images and point clouds by pretrained large-scale models first, and then establish robust correspondence within the same modality. We show that the intermediate features, called diffusion features, extracted by depth-to-image diffusion models are semantically consistent between images and point clouds, which enables the building of coarse but robust cross-modality correspondences. We further extract geometric features on depth maps produced by the monocular depth estimator. By matching such geometric features, we significantly improve the accuracy of the coarse correspondences produced by diffusion features. Extensive experiments demonstrate that without any task-specific training, direct utilization of both features produces accurate image-to-point cloud registration. On three public indoor and outdoor benchmarks, the proposed method averagely achieves a 20.6 percent improvement in Inlier Ratio, a three-fold higher Inlier Number, and a 48.6 percent improvement in Registration Recall than existing state-of-the-arts.
Read more4/16/2024