Depth from Coupled Optical Differentiation

0

Sign in to get full access
Overview
- The paper proposes a novel depth estimation technique called "Depth from Coupled Optical Differentiation" (DCOD).
- DCOD leverages the physics of light propagation to recover depth information from a single image.
- The approach involves capturing two images with different optical configurations and then performing coupled optical differentiation to estimate depth.
Plain English Explanation
The paper describes a method for estimating the depth of objects in a scene using a single image. The key idea is to capture two images of the same scene using slightly different camera settings. By analyzing the differences between these two images, the system can deduce information about the 3D structure of the scene.
Specifically, the authors propose a technique called "Depth from Coupled Optical Differentiation" (DCOD). This involves using a special optical setup that manipulates the light entering the camera in a controlled way. The system captures one image with the normal optics, and a second image with a modified optical path. By comparing these two images, the system can calculate depth information about the objects in the scene.
The advantage of this approach is that it can recover depth without requiring multiple cameras, complex sensor arrays, or time-of-flight measurements. Instead, it leverages the physics of light propagation to extract 3D information from a single 2D image. This could enable more compact and cost-effective depth sensing solutions for a variety of applications, such as 3D imaging or augmented reality.
Technical Explanation
The core of the DCOD approach is the use of coupled optical differentiation to estimate depth from a single image. This involves capturing two images of the same scene using slightly different optical configurations.
The first image is captured with the normal camera optics. The second image is captured with an additional optical element, such as a diffractive optical element (DOE), inserted into the optical path. This modifies the wavefront of the light entering the camera in a known way.
By comparing the two images, the system can calculate the optical differentiation between them. This optical differentiation is directly related to the depth of objects in the scene through the physics of light propagation. The authors show how this relationship can be modeled mathematically and used to recover a depth map from the two input images.
The key insight is that this approach avoids the need for multiple cameras, active illumination, or complex sensor arrays. Instead, it leverages the inherent physics of the optical system to extract 3D information from a pair of 2D images. The authors demonstrate the effectiveness of DCOD through experiments on both synthetic and real-world data.
Critical Analysis
The paper presents a compelling approach to depth estimation that has several potential advantages over existing techniques. By using a single camera and passive optical elements, the DCOD method could enable more compact and cost-effective depth sensing solutions compared to methods that require specialized hardware.
However, the paper does not fully address the practical limitations and challenges of implementing DCOD in real-world scenarios. For example, the optical setup required to achieve the desired wavefront modulation may be challenging to integrate into a compact camera system. Additionally, the sensitivity of the depth estimation to factors like image noise, scene texture, and illumination conditions is not thoroughly explored.
Further research would be needed to assess the robustness and limitations of DCOD in diverse environments and applications. The authors acknowledge that their method may be most suitable for controlled settings, and more work is required to address the challenges of real-world deployment.
Conclusion
The "Depth from Coupled Optical Differentiation" (DCOD) technique presented in this paper offers a novel approach to depth estimation from a single image. By leveraging the physics of light propagation and a specialized optical setup, DCOD can recover 3D information without requiring multiple cameras or active illumination.
While the theoretical foundations of the method are sound, the practical implementation and real-world performance remain open questions that warrant further investigation. Addressing the challenges of robustness, scalability, and integration into compact camera systems could unlock the potential of this approach to enable more accessible and widespread 3D imaging capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Depth from Coupled Optical Differentiation
Junjie Luo, Yuxuan Liu, Emma Alexander, Qi Guo
We propose depth from coupled optical differentiation, a low-computation passive-lighting 3D sensing mechanism. It is based on our discovery that per-pixel object distance can be rigorously determined by a coupled pair of optical derivatives of a defocused image using a simple, closed-form relationship. Unlike previous depth-from-defocus (DfD) methods that leverage spatial derivatives of the image to estimate scene depths, the proposed mechanism's use of only optical derivatives makes it significantly more robust to noise. Furthermore, unlike many previous DfD algorithms with requirements on aperture code, this relationship is proved to be universal to a broad range of aperture codes. We build the first 3D sensor based on depth from coupled optical differentiation. Its optical assembly includes a deformable lens and a motorized iris, which enables dynamic adjustments to the optical power and aperture radius. The sensor captures two pairs of images: one pair with a differential change of optical power and the other with a differential change of aperture scale. From the four images, a depth and confidence map can be generated with only 36 floating point operations per output pixel (FLOPOP), more than ten times lower than the previous lowest passive-lighting depth sensing solution to our knowledge. Additionally, the depth map generated by the proposed sensor demonstrates more than twice the working range of previous DfD methods while using significantly lower computation.
Read more9/18/2024
0
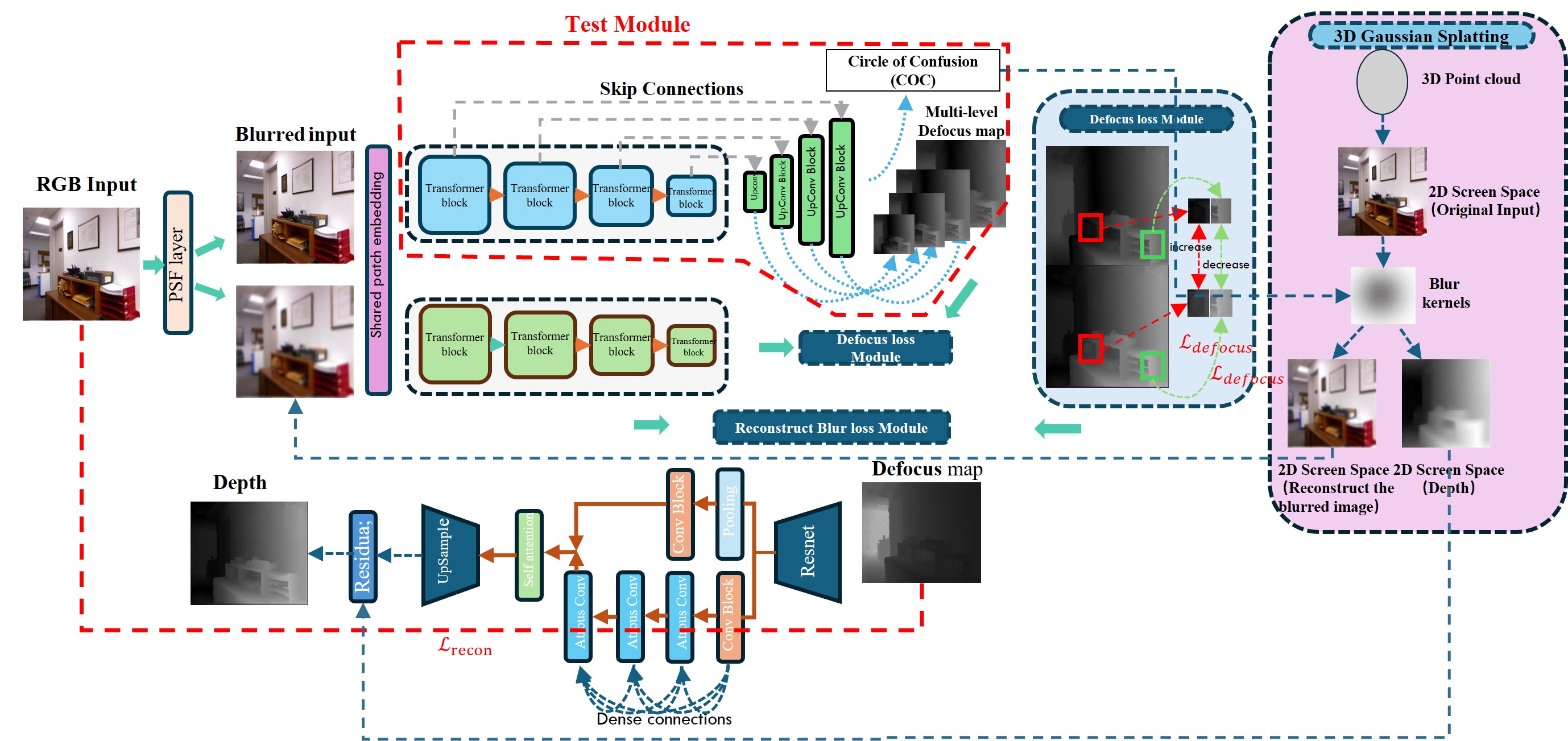
Depth Estimation Based on 3D Gaussian Splatting Siamese Defocus
Jinchang Zhang, Ningning Xu, Hao Zhang, Guoyu Lu
Depth estimation is a fundamental task in 3D geometry. While stereo depth estimation can be achieved through triangulation methods, it is not as straightforward for monocular methods, which require the integration of global and local information. The Depth from Defocus (DFD) method utilizes camera lens models and parameters to recover depth information from blurred images and has been proven to perform well. However, these methods rely on All-In-Focus (AIF) images for depth estimation, which is nearly impossible to obtain in real-world applications. To address this issue, we propose a self-supervised framework based on 3D Gaussian splatting and Siamese networks. By learning the blur levels at different focal distances of the same scene in the focal stack, the framework predicts the defocus map and Circle of Confusion (CoC) from a single defocused image, using the defocus map as input to DepthNet for monocular depth estimation. The 3D Gaussian splatting model renders defocused images using the predicted CoC, and the differences between these and the real defocused images provide additional supervision signals for the Siamese Defocus self-supervised network. This framework has been validated on both artificially synthesized and real blurred datasets. Subsequent quantitative and visualization experiments demonstrate that our proposed framework is highly effective as a DFD method.
Read more9/20/2024

0
DCPI-Depth: Explicitly Infusing Dense Correspondence Prior to Unsupervised Monocular Depth Estimation
Mengtan Zhang, Yi Feng, Qijun Chen, Rui Fan
There has been a recent surge of interest in learning to perceive depth from monocular videos in an unsupervised fashion. A key challenge in this field is achieving robust and accurate depth estimation in challenging scenarios, particularly in regions with weak textures or where dynamic objects are present. This study makes three major contributions by delving deeply into dense correspondence priors to provide existing frameworks with explicit geometric constraints. The first novelty is a contextual-geometric depth consistency loss, which employs depth maps triangulated from dense correspondences based on estimated ego-motion to guide the learning of depth perception from contextual information, since explicitly triangulated depth maps capture accurate relative distances among pixels. The second novelty arises from the observation that there exists an explicit, deducible relationship between optical flow divergence and depth gradient. A differential property correlation loss is, therefore, designed to refine depth estimation with a specific emphasis on local variations. The third novelty is a bidirectional stream co-adjustment strategy that enhances the interaction between rigid and optical flows, encouraging the former towards more accurate correspondence and making the latter more adaptable across various scenarios under the static scene hypotheses. DCPI-Depth, a framework that incorporates all these innovative components and couples two bidirectional and collaborative streams, achieves state-of-the-art performance and generalizability across multiple public datasets, outperforming all existing prior arts. Specifically, it demonstrates accurate depth estimation in texture-less and dynamic regions, and shows more reasonable smoothness.
Read more5/28/2024

0
D3RoMa: Disparity Diffusion-based Depth Sensing for Material-Agnostic Robotic Manipulation
Songlin Wei, Haoran Geng, Jiayi Chen, Congyue Deng, Wenbo Cui, Chengyang Zhao, Xiaomeng Fang, Leonidas Guibas, He Wang
Depth sensing is an important problem for 3D vision-based robotics. Yet, a real-world active stereo or ToF depth camera often produces noisy and incomplete depth which bottlenecks robot performances. In this work, we propose D3RoMa, a learning-based depth estimation framework on stereo image pairs that predicts clean and accurate depth in diverse indoor scenes, even in the most challenging scenarios with translucent or specular surfaces where classical depth sensing completely fails. Key to our method is that we unify depth estimation and restoration into an image-to-image translation problem by predicting the disparity map with a denoising diffusion probabilistic model. At inference time, we further incorporated a left-right consistency constraint as classifier guidance to the diffusion process. Our framework combines recently advanced learning-based approaches and geometric constraints from traditional stereo vision. For model training, we create a large scene-level synthetic dataset with diverse transparent and specular objects to compensate for existing tabletop datasets. The trained model can be directly applied to real-world in-the-wild scenes and achieve state-of-the-art performance in multiple public depth estimation benchmarks. Further experiments in real environments show that accurate depth prediction significantly improves robotic manipulation in various scenarios.
Read more9/26/2024