Detection and Positive Reconstruction of Cognitive Distortion sentences: Mandarin Dataset and Evaluation

0
Sign in to get full access
Overview
- This paper introduces a dataset and evaluation framework for detecting and positively reconstructing cognitive distortion sentences in Mandarin Chinese.
- Cognitive distortions are patterns of inaccurate or biased thinking that can contribute to mental health issues.
- The authors developed a dataset of Mandarin sentences representing different types of cognitive distortions and non-distorted counterparts.
- They also proposed models for detecting cognitive distortions and generating positive reconstructions of distorted sentences.
Plain English Explanation
The paper focuses on a problem known as "cognitive distortions" - patterns of thinking that are inaccurate or biased, and can contribute to mental health problems. The researchers created a dataset of Mandarin Chinese sentences that showcase different types of cognitive distortions, as well as non-distorted versions of those sentences. This dataset can be used to train models to detect cognitive distortions and generate reconstructed versions that are more positive. By having this standardized dataset and evaluation framework, the researchers hope to advance work on understanding and addressing cognitive distortions, which are an important issue in mental health.
Technical Explanation
The researchers collected a dataset of Mandarin Chinese sentences representing seven common types of cognitive distortions, as well as non-distorted counterpart sentences. This Mandarin Cognitive Distortion (MCD) dataset consists of over 10,000 sentence pairs.
The authors then proposed two main models:
-
A cognitive distortion detection model, which uses transformer-based neural networks to classify sentences as distorted or not.
-
A positive reconstruction model, which generates enhanced, more positive versions of distorted sentences.
They evaluated these models on the MCD dataset and found they were able to effectively detect cognitive distortions and produce plausible positive reconstructions.
Critical Analysis
The dataset and evaluation framework introduced in this paper represent an important step forward in addressing cognitive distortions computationally. Having a standardized resource for this task will enable more systematic research and development of techniques to identify and mitigate cognitive biases.
However, the authors acknowledge several limitations. The dataset is focused on Mandarin Chinese and may not generalize well to other languages. The types of cognitive distortions covered, while common, do not represent the full breadth of possible distortions. There are also open questions about the best way to evaluate the positive reconstruction task.
Further research is needed to expand the dataset, explore cross-lingual capabilities, and refine the evaluation metrics. Careful consideration should also be given to the societal implications of deploying such technologies, to ensure they are used responsibly to support mental health rather than exacerbate issues.
Conclusion
This paper introduces a valuable new resource for computational research on cognitive distortions - a Mandarin Chinese dataset and evaluation framework. The proposed models demonstrate the potential to automatically detect distortions and generate more positive reconstructions. While there are limitations to address, this work represents an important step forward in applying AI techniques to understand and address this crucial mental health challenge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Detection and Positive Reconstruction of Cognitive Distortion sentences: Mandarin Dataset and Evaluation
Shuya Lin, Yuxiong Wang, Jonathan Dong, Shiguang Ni
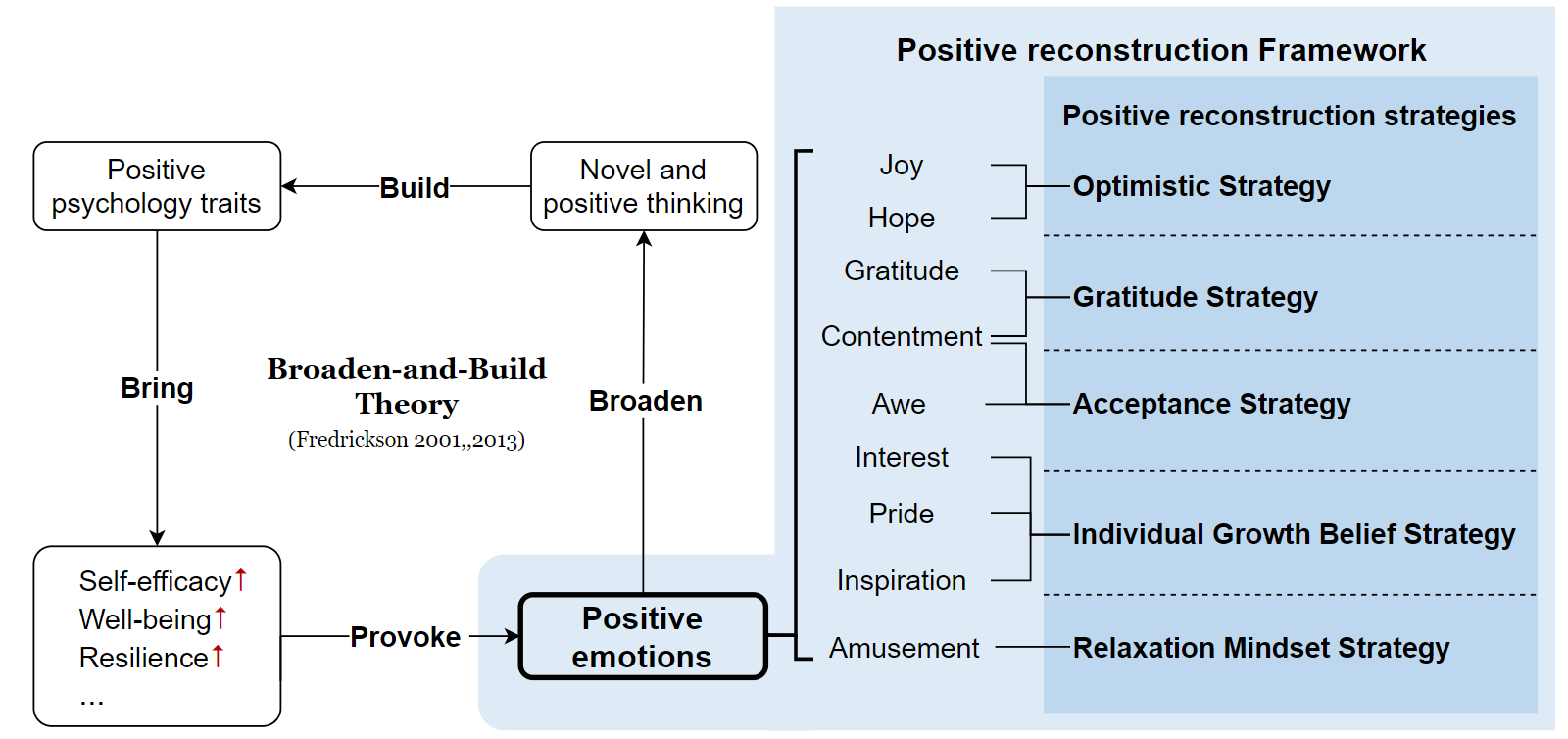
This research introduces a Positive Reconstruction Framework based on positive psychology theory. Overcoming negative thoughts can be challenging, our objective is to address and reframe them through a positive reinterpretation. To tackle this challenge, a two-fold approach is necessary: identifying cognitive distortions and suggesting a positively reframed alternative while preserving the original thought's meaning. Recent studies have investigated the application of Natural Language Processing (NLP) models in English for each stage of this process. In this study, we emphasize the theoretical foundation for the Positive Reconstruction Framework, grounded in broaden-and-build theory. We provide a shared corpus containing 4001 instances for detecting cognitive distortions and 1900 instances for positive reconstruction in Mandarin. Leveraging recent NLP techniques, including transfer learning, fine-tuning pretrained networks, and prompt engineering, we demonstrate the effectiveness of automated tools for both tasks. In summary, our study contributes to multilingual positive reconstruction, highlighting the effectiveness of NLP in cognitive distortion detection and positive reconstruction.
Read more9/9/2024
👨🏫
0
Supervised Learning and Large Language Model Benchmarks on Mental Health Datasets: Cognitive Distortions and Suicidal Risks in Chinese Social Media
Hongzhi Qi, Qing Zhao, Jianqiang Li, Changwei Song, Wei Zhai, Dan Luo, Shuo Liu, Yi Jing Yu, Fan Wang, Huijing Zou, Bing Xiang Yang, Guanghui Fu
On social media, users often express their personal feelings, which may exhibit cognitive distortions or even suicidal tendencies on certain specific topics. Early recognition of these signs is critical for effective psychological intervention. In this paper, we introduce two novel datasets from Chinese social media: SOS-HL-1K for suicidal risk classification and SocialCD-3K for cognitive distortions detection. The SOS-HL-1K dataset contained 1,249 posts and SocialCD-3K dataset was a multi-label classification dataset that containing 3,407 posts. We propose a comprehensive evaluation using two supervised learning methods and eight large language models (LLMs) on the proposed datasets. From the prompt engineering perspective, we experimented with two types of prompt strategies, including four zero-shot and five few-shot strategies. We also evaluated the performance of the LLMs after fine-tuning on the proposed tasks. The experimental results show that there is still a huge gap between LLMs relying only on prompt engineering and supervised learning. In the suicide classification task, this gap is 6.95% points in F1-score, while in the cognitive distortion task, the gap is even more pronounced, reaching 31.53% points in F1-score. However, after fine-tuning, this difference is significantly reduced. In the suicide and cognitive distortion classification tasks, the gap decreases to 4.31% and 3.14%, respectively. This research highlights the potential of LLMs in psychological contexts, but supervised learning remains necessary for more challenging tasks. All datasets and code are made available.
Read more6/11/2024

0
Positive Text Reframing under Multi-strategy Optimization
Shutong Jia, Biwei Cao, Qingqing Gao, Jiuxin Cao, Bo Liu
Differing from sentiment transfer, positive reframing seeks to substitute negative perspectives with positive expressions while preserving the original meaning. With the emergence of pre-trained language models (PLMs), it is possible to achieve acceptable results by fine-tuning PLMs. Nevertheless, generating fluent, diverse and task-constrained reframing text remains a significant challenge. To tackle this issue, a textbf{m}ulti-textbf{s}trategy textbf{o}ptimization textbf{f}ramework (MSOF) is proposed in this paper. Starting from the objective of positive reframing, we first design positive sentiment reward and content preservation reward to encourage the model to transform the negative expressions of the original text while ensuring the integrity and consistency of the semantics. Then, different decoding optimization approaches are introduced to improve the quality of text generation. Finally, based on the modeling formula of positive reframing, we propose a multi-dimensional re-ranking method that further selects candidate sentences from three dimensions: strategy consistency, text similarity and fluency. Extensive experiments on two Seq2Seq PLMs, BART and T5, demonstrate our framework achieves significant improvements on unconstrained and controlled positive reframing tasks.
Read more7/30/2024
0
Connected Speech-Based Cognitive Assessment in Chinese and English
Saturnino Luz, Sofia De La Fuente Garcia, Fasih Haider, Davida Fromm, Brian MacWhinney, Alyssa Lanzi, Ya-Ning Chang, Chia-Ju Chou, Yi-Chien Liu
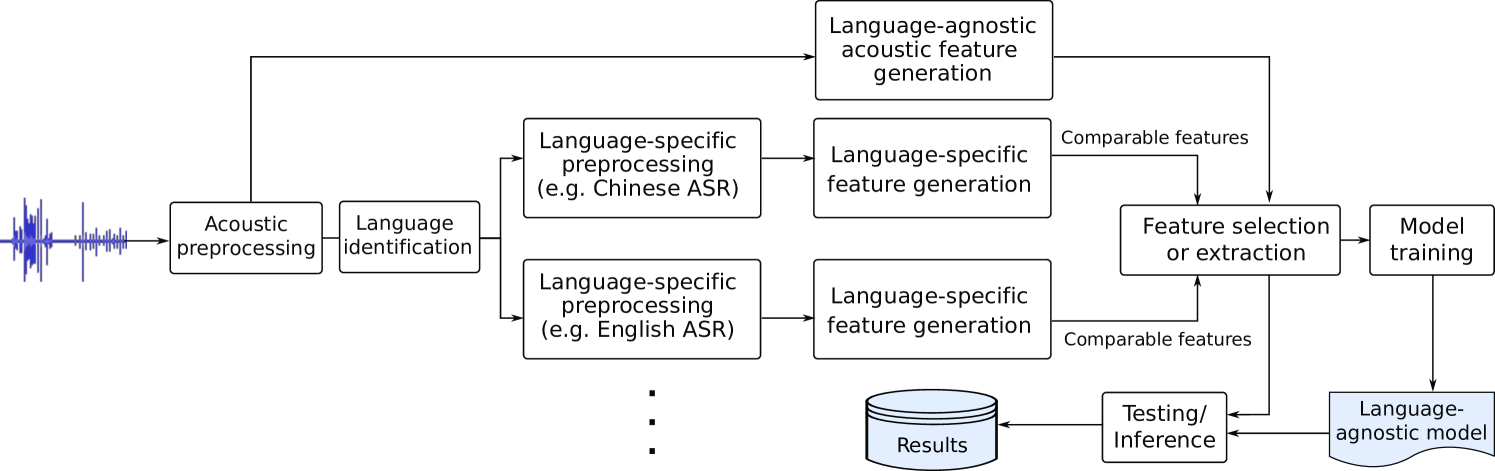
We present a novel benchmark dataset and prediction tasks for investigating approaches to assess cognitive function through analysis of connected speech. The dataset consists of speech samples and clinical information for speakers of Mandarin Chinese and English with different levels of cognitive impairment as well as individuals with normal cognition. These data have been carefully matched by age and sex by propensity score analysis to ensure balance and representativity in model training. The prediction tasks encompass mild cognitive impairment diagnosis and cognitive test score prediction. This framework was designed to encourage the development of approaches to speech-based cognitive assessment which generalise across languages. We illustrate it by presenting baseline prediction models that employ language-agnostic and comparable features for diagnosis and cognitive test score prediction. The models achieved unweighted average recall was 59.2% in diagnosis, and root mean squared error of 2.89 in score prediction.
Read more6/19/2024