Direct May Not Be the Best: An Incremental Evolution View of Pose Generation
2404.08419
0
0

Abstract
Pose diversity is an inherent representative characteristic of 2D images. Due to the 3D to 2D projection mechanism, there is evident content discrepancy among distinct pose images. This is the main obstacle bothering pose transformation related researches. To deal with this challenge, we propose a fine-grained incremental evolution centered pose generation framework, rather than traditional direct one-to-one in a rush. Since proposed approach actually bypasses the theoretical difficulty of directly modeling dramatic non-linear variation, the incurred content distortion and blurring could be effectively constrained, at the same time the various individual pose details, especially clothes texture, could be precisely maintained. In order to systematically guide the evolution course, both global and incremental evolution constraints are elaborately designed and merged into the overall framework. And a novel triple-path knowledge fusion structure is worked out to take full advantage of all available valuable knowledge to conduct high-quality pose synthesis. In addition, our framework could generate a series of valuable byproducts, namely the various intermediate poses. Extensive experiments have been conducted to verify the effectiveness of the proposed approach. Code is available at https://github.com/Xiaofei-CN/Incremental-Evolution-Pose-Generation.
Create account to get full access
Overview
- This paper explores an "incremental evolution" approach to pose generation, challenging the common assumption that direct pose generation is the best method.
- The authors propose a novel method that aims to generate poses through a gradual, iterative process, rather than a direct mapping from input to output.
- The paper presents experimental results and insights that suggest this incremental approach can outperform direct pose generation models in certain scenarios.
Plain English Explanation
The paper looks at a new way of generating human poses, which are the positions and orientations of the different parts of the body. Traditionally, pose generation models have tried to directly map input data (like images or text) to the final pose. However, the authors of this paper argue that a more gradual, "incremental" approach might actually work better in some cases.
The idea is that instead of trying to generate the full pose all at once, the model could generate it step-by-step, building up the pose in an iterative fashion. This might allow the model to better capture the complex relationships between different body parts and produce more natural-looking poses.
The paper presents a new method that follows this incremental approach, and the authors show through experiments that it can outperform direct pose generation models in certain situations. This suggests that the traditional assumption that direct mapping is the best approach may not always be correct, and that more nuanced methods could lead to better results.
Technical Explanation
The paper proposes an "Incremental Evolution View of Pose Generation", which challenges the common assumption that direct pose generation is the optimal approach. Instead, the authors argue that a more gradual, iterative process of pose generation may be advantageous in certain scenarios.
The proposed method works by breaking down the pose generation task into a series of smaller, incremental steps. Rather than trying to generate the full pose all at once, the model generates the pose in an iterative fashion, gradually refining and building up the final output. This allows the model to better capture the complex relationships between different body parts and produce more natural-looking poses.
The authors evaluate their approach through extensive experiments, comparing it to traditional direct pose generation models on a variety of datasets and tasks. The results suggest that the incremental evolution approach can outperform direct mapping in certain scenarios, providing evidence that a more nuanced view of pose generation may be warranted.
Critical Analysis
The paper presents a compelling argument for reconsidering the assumption that direct pose generation is the optimal approach. By introducing the "incremental evolution" perspective, the authors open up new avenues for exploration in the field of pose estimation and generation.
One potential limitation of the approach is the increased complexity and computational overhead associated with the iterative process. The authors note that the incremental generation may be more computationally intensive than direct mapping, which could be a drawback in certain real-time applications or resource-constrained environments.
Additionally, the paper focuses primarily on the pose generation task and does not extensively explore the broader implications of the incremental evolution view. It would be interesting to see if this perspective could be applied to other areas of computer vision and machine learning, such as Towards Simultaneous Granular Identity-Expression Control for Personalized or ReposedM: Recurrent Pose Alignment with Gradient Guidance for Pose generation.
Furthermore, the paper could have delved deeper into the potential limitations or failure cases of the incremental evolution approach, as well as discussing areas for future research and improvement, such as Incremental Joint Learning of Depth and Pose from Implicit Scene Representation or Multi-Person 3D Pose Estimation from Unlabelled Images.
Overall, the paper presents a thought-provoking and potentially impactful perspective on pose generation, which could inspire further research and development in the field. The authors' willingness to challenge existing assumptions and explore alternative approaches is commendable and may lead to significant advances in Morphable Diffusion: 3D-Consistent Diffusion from Single Image generation and related areas.
Conclusion
This paper challenges the conventional wisdom that direct pose generation is the optimal approach, proposing an "incremental evolution" view as an alternative. The authors present a novel method that generates poses through a gradual, iterative process, and demonstrate through experiments that this approach can outperform direct mapping models in certain scenarios.
The findings of this research suggest that a more nuanced understanding of pose generation may be warranted, and that exploring alternative approaches beyond the direct mapping paradigm could lead to significant advances in the field. While the incremental evolution view introduces some additional complexity, the potential benefits in terms of producing more natural-looking and realistic poses make it a promising area for further exploration and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
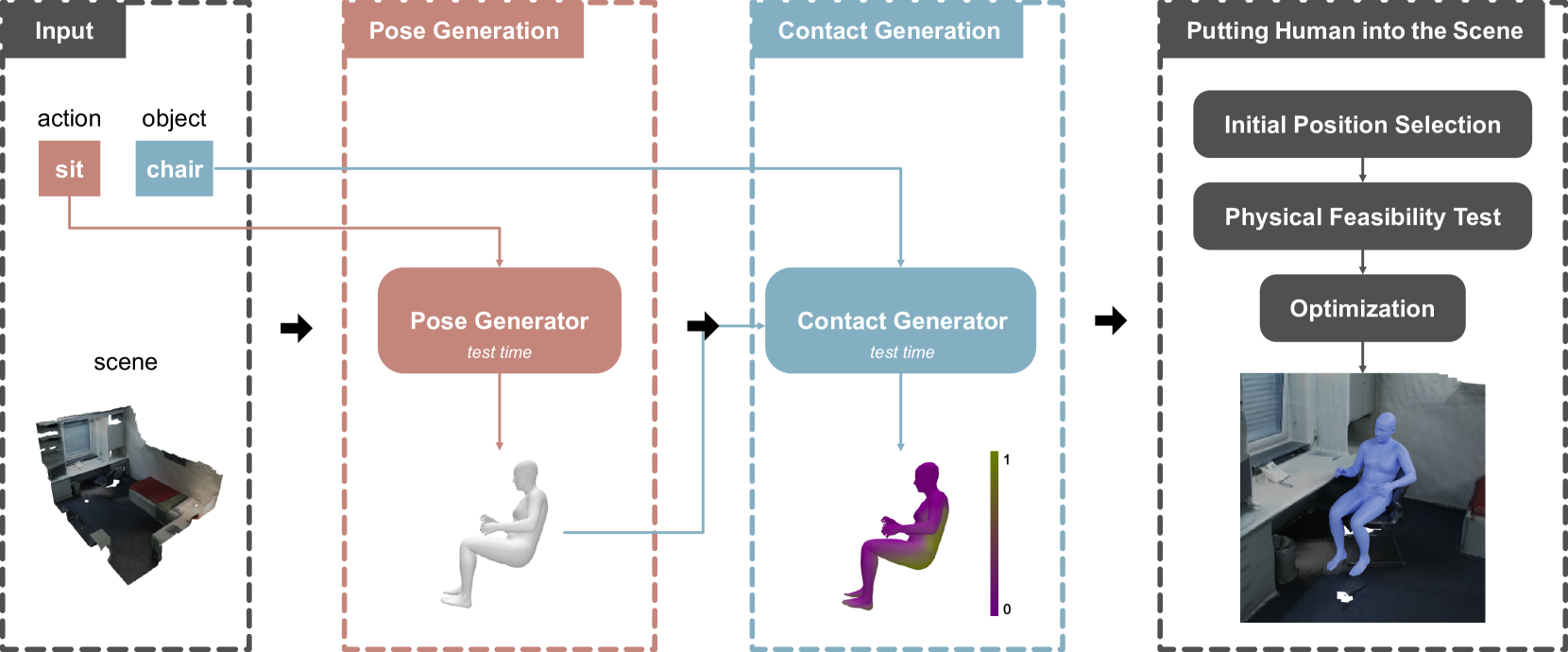
Diverse 3D Human Pose Generation in Scenes based on Decoupled Structure
Bowen Dang, Xi Zhao
0
0
This paper presents a novel method for generating diverse 3D human poses in scenes with semantic control. Existing methods heavily rely on the human-scene interaction dataset, resulting in a limited diversity of the generated human poses. To overcome this challenge, we propose to decouple the pose and interaction generation process. Our approach consists of three stages: pose generation, contact generation, and putting human into the scene. We train a pose generator on the human dataset to learn rich pose prior, and a contact generator on the human-scene interaction dataset to learn human-scene contact prior. Finally, the placing module puts the human body into the scene in a suitable and natural manner. The experimental results on the PROX dataset demonstrate that our method produces more physically plausible interactions and exhibits more diverse human poses. Furthermore, experiments on the MP3D-R dataset further validates the generalization ability of our method.
6/11/2024

Diversifying Human Pose in Synthetic Data for Aerial-view Human Detection
Yi-Ting Shen, Hyungtae Lee, Heesung Kwon, Shuvra S. Bhattacharyya
0
0
We present a framework for diversifying human poses in a synthetic dataset for aerial-view human detection. Our method firstly constructs a set of novel poses using a pose generator and then alters images in the existing synthetic dataset to assume the novel poses while maintaining the original style using an image translator. Since images corresponding to the novel poses are not available in training, the image translator is trained to be applicable only when the input and target poses are similar, thus training does not require the novel poses and their corresponding images. Next, we select a sequence of target novel poses from the novel pose set, using Dijkstra's algorithm to ensure that poses closer to each other are located adjacently in the sequence. Finally, we repeatedly apply the image translator to each target pose in sequence to produce a group of novel pose images representing a variety of different limited body movements from the source pose. Experiments demonstrate that, regardless of how the synthetic data is used for training or the data size, leveraging the pose-diversified synthetic dataset in training generally presents remarkably better accuracy than using the original synthetic dataset on three aerial-view human detection benchmarks (VisDrone, Okutama-Action, and ICG) in the few-shot regime.
5/28/2024
📶
InvertAvatar: Incremental GAN Inversion for Generalized Head Avatars
Xiaochen Zhao, Jingxiang Sun, Lizhen Wang, Jinli Suo, Yebin Liu
0
0
While high fidelity and efficiency are central to the creation of digital head avatars, recent methods relying on 2D or 3D generative models often experience limitations such as shape distortion, expression inaccuracy, and identity flickering. Additionally, existing one-shot inversion techniques fail to fully leverage multiple input images for detailed feature extraction. We propose a novel framework, textbf{Incremental 3D GAN Inversion}, that enhances avatar reconstruction performance using an algorithm designed to increase the fidelity from multiple frames, resulting in improved reconstruction quality proportional to frame count. Our method introduces a unique animatable 3D GAN prior with two crucial modifications for enhanced expression controllability alongside an innovative neural texture encoder that categorizes texture feature spaces based on UV parameterization. Differentiating from traditional techniques, our architecture emphasizes pixel-aligned image-to-image translation, mitigating the need to learn correspondences between observation and canonical spaces. Furthermore, we incorporate ConvGRU-based recurrent networks for temporal data aggregation from multiple frames, boosting geometry and texture detail reconstruction. The proposed paradigm demonstrates state-of-the-art performance on one-shot and few-shot avatar animation tasks. Code will be available at https://github.com/XChenZ/invertAvatar.
5/28/2024

VividPose: Advancing Stable Video Diffusion for Realistic Human Image Animation
Qilin Wang, Zhengkai Jiang, Chengming Xu, Jiangning Zhang, Yabiao Wang, Xinyi Zhang, Yun Cao, Weijian Cao, Chengjie Wang, Yanwei Fu
0
0
Human image animation involves generating a video from a static image by following a specified pose sequence. Current approaches typically adopt a multi-stage pipeline that separately learns appearance and motion, which often leads to appearance degradation and temporal inconsistencies. To address these issues, we propose VividPose, an innovative end-to-end pipeline based on Stable Video Diffusion (SVD) that ensures superior temporal stability. To enhance the retention of human identity, we propose an identity-aware appearance controller that integrates additional facial information without compromising other appearance details such as clothing texture and background. This approach ensures that the generated videos maintain high fidelity to the identity of human subject, preserving key facial features across various poses. To accommodate diverse human body shapes and hand movements, we introduce a geometry-aware pose controller that utilizes both dense rendering maps from SMPL-X and sparse skeleton maps. This enables accurate alignment of pose and shape in the generated videos, providing a robust framework capable of handling a wide range of body shapes and dynamic hand movements. Extensive qualitative and quantitative experiments on the UBCFashion and TikTok benchmarks demonstrate that our method achieves state-of-the-art performance. Furthermore, VividPose exhibits superior generalization capabilities on our proposed in-the-wild dataset. Codes and models will be available.
5/29/2024