Does Reasoning Emerge? Examining the Probabilities of Causation in Large Language Models

189

Sign in to get full access
Overview
- Examines the probabilities of causation in large language models (LLMs) to understand if reasoning emerges in these systems.
- Analyzes the abstract machine-like properties of LLMs and their potential for causal reasoning.
- Explores the limitations and caveats of the research, as well as areas for further investigation.
Plain English Explanation
The paper investigates whether large language models (LLMs) - powerful AI systems trained on vast amounts of text data - are capable of reasoning and understanding causal relationships. LLMs can generate human-like text, but it's not clear if they truly comprehend the underlying meanings and causal connections, or if they are simply pattern-matching based on statistical correlations in the data.
The researchers approach this question by treating LLMs as abstract machines - mathematical models that can perform computations and transformations on inputs to produce outputs. They examine the "probabilities of causation" within these models, looking for signs that the LLMs are going beyond simple association and grasping deeper causal relationships.
The plain English explanation covers the core ideas and significance of this research in an accessible way, using analogies and examples to make the technical concepts more understandable for a general audience.
Technical Explanation
The paper presents a comprehensive analysis of LLMs as abstract machines, exploring their potential for causal reasoning. The researchers investigate the probabilities of causation within these models, looking for evidence of higher-order cognitive abilities beyond simple pattern matching.
The study involves designing experiments to evaluate the interventional reasoning capabilities of LLMs, assessing their ability to understand and reason about causal relationships. The researchers also characterize the nature and limitations of causal reasoning in these systems, identifying areas for further research and development.
Critical Analysis
The paper acknowledges the limitations of the research, noting that the ability to reason causally is still an open question. While the analysis of probabilities of causation provides insights, the researchers caution that more work is needed to fully understand the reasoning capabilities of LLMs.
Additionally, the study raises concerns about the potential for LLMs to make unreliable causal inferences based on statistical correlations in the training data, rather than true causal understanding. This highlights the importance of further research and safeguards to ensure the responsible development and deployment of these powerful AI systems.
Conclusion
This paper represents a significant step in understanding the reasoning capabilities of large language models. By examining the probabilities of causation within these abstract machines, the researchers have shed light on the potential for LLMs to go beyond simple pattern matching and engage in more sophisticated forms of reasoning.
While the findings suggest that some causal reasoning capabilities may be emerging in LLMs, the researchers emphasize the need for continued investigation and caution against over-interpreting the results. Ongoing research in this area will be crucial for advancing the field of AI and ensuring the responsible development of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
189
Does Reasoning Emerge? Examining the Probabilities of Causation in Large Language Models
Javier Gonz'alez, Aditya V. Nori
Recent advances in AI have been significantly driven by the capabilities of large language models (LLMs) to solve complex problems in ways that resemble human thinking. However, there is an ongoing debate about the extent to which LLMs are capable of actual reasoning. Central to this debate are two key probabilistic concepts that are essential for connecting causes to their effects: the probability of necessity (PN) and the probability of sufficiency (PS). This paper introduces a framework that is both theoretical and practical, aimed at assessing how effectively LLMs are able to replicate real-world reasoning mechanisms using these probabilistic measures. By viewing LLMs as abstract machines that process information through a natural language interface, we examine the conditions under which it is possible to compute suitable approximations of PN and PS. Our research marks an important step towards gaining a deeper understanding of when LLMs are capable of reasoning, as illustrated by a series of math examples.
Read more8/16/2024
💬
4
Causal Reasoning and Large Language Models: Opening a New Frontier for Causality
Emre K{i}c{i}man, Robert Ness, Amit Sharma, Chenhao Tan
The causal capabilities of large language models (LLMs) are a matter of significant debate, with critical implications for the use of LLMs in societally impactful domains such as medicine, science, law, and policy. We conduct a behavorial study of LLMs to benchmark their capability in generating causal arguments. Across a wide range of tasks, we find that LLMs can generate text corresponding to correct causal arguments with high probability, surpassing the best-performing existing methods. Algorithms based on GPT-3.5 and 4 outperform existing algorithms on a pairwise causal discovery task (97%, 13 points gain), counterfactual reasoning task (92%, 20 points gain) and event causality (86% accuracy in determining necessary and sufficient causes in vignettes). We perform robustness checks across tasks and show that the capabilities cannot be explained by dataset memorization alone, especially since LLMs generalize to novel datasets that were created after the training cutoff date. That said, LLMs exhibit unpredictable failure modes, and we discuss the kinds of errors that may be improved and what are the fundamental limits of LLM-based answers. Overall, by operating on the text metadata, LLMs bring capabilities so far understood to be restricted to humans, such as using collected knowledge to generate causal graphs or identifying background causal context from natural language. As a result, LLMs may be used by human domain experts to save effort in setting up a causal analysis, one of the biggest impediments to the widespread adoption of causal methods. Given that LLMs ignore the actual data, our results also point to a fruitful research direction of developing algorithms that combine LLMs with existing causal techniques. Code and datasets are available at https://github.com/py-why/pywhy-llm.
Read more8/21/2024
0
Is Knowledge All Large Language Models Needed for Causal Reasoning?
Hengrui Cai, Shengjie Liu, Rui Song
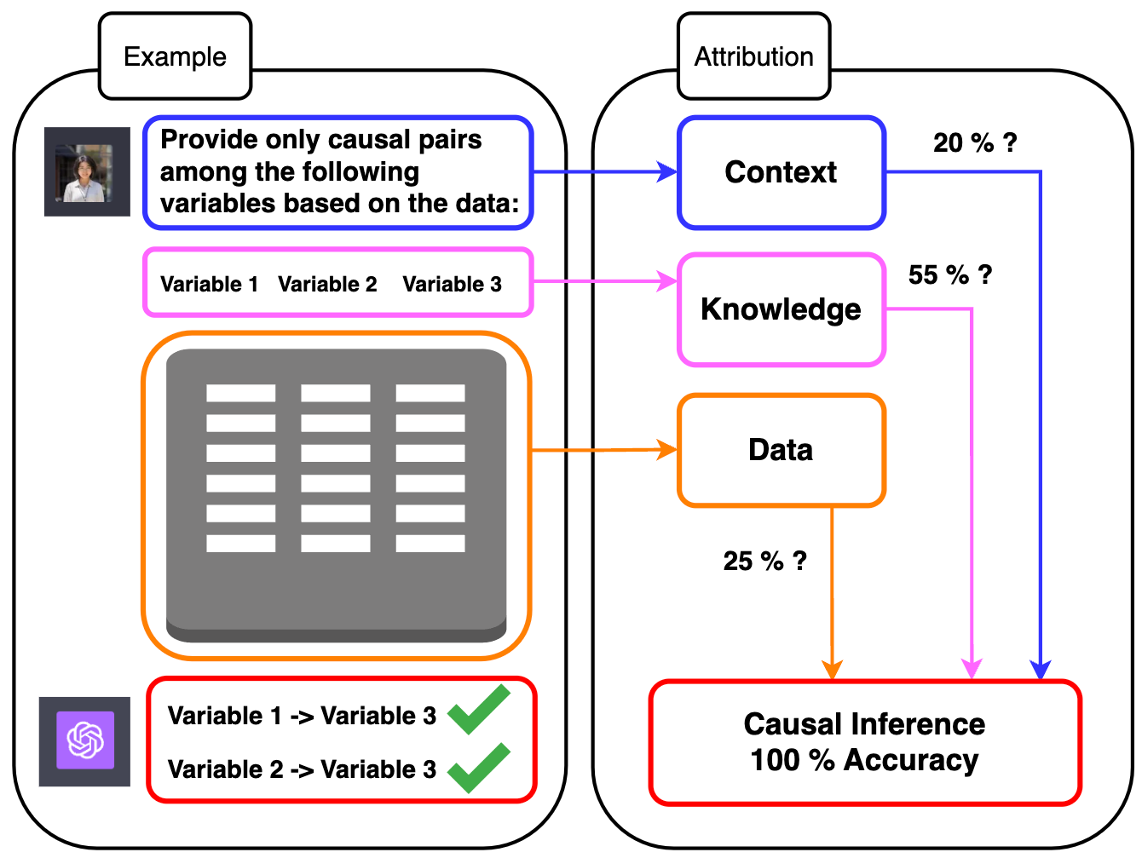
This paper explores the causal reasoning of large language models (LLMs) to enhance their interpretability and reliability in advancing artificial intelligence. Despite the proficiency of LLMs in a range of tasks, their potential for understanding causality requires further exploration. We propose a novel causal attribution model that utilizes ``do-operators for constructing counterfactual scenarios, allowing us to systematically quantify the influence of input numerical data and LLMs' pre-existing knowledge on their causal reasoning processes. Our newly developed experimental setup assesses LLMs' reliance on contextual information and inherent knowledge across various domains. Our evaluation reveals that LLMs' causal reasoning ability mainly depends on the context and domain-specific knowledge provided. In the absence of such knowledge, LLMs can still maintain a degree of causal reasoning using the available numerical data, albeit with limitations in the calculations. This motivates the proposed fine-tuned LLM for pairwise causal discovery, effectively leveraging both knowledge and numerical information.
Read more6/6/2024
0
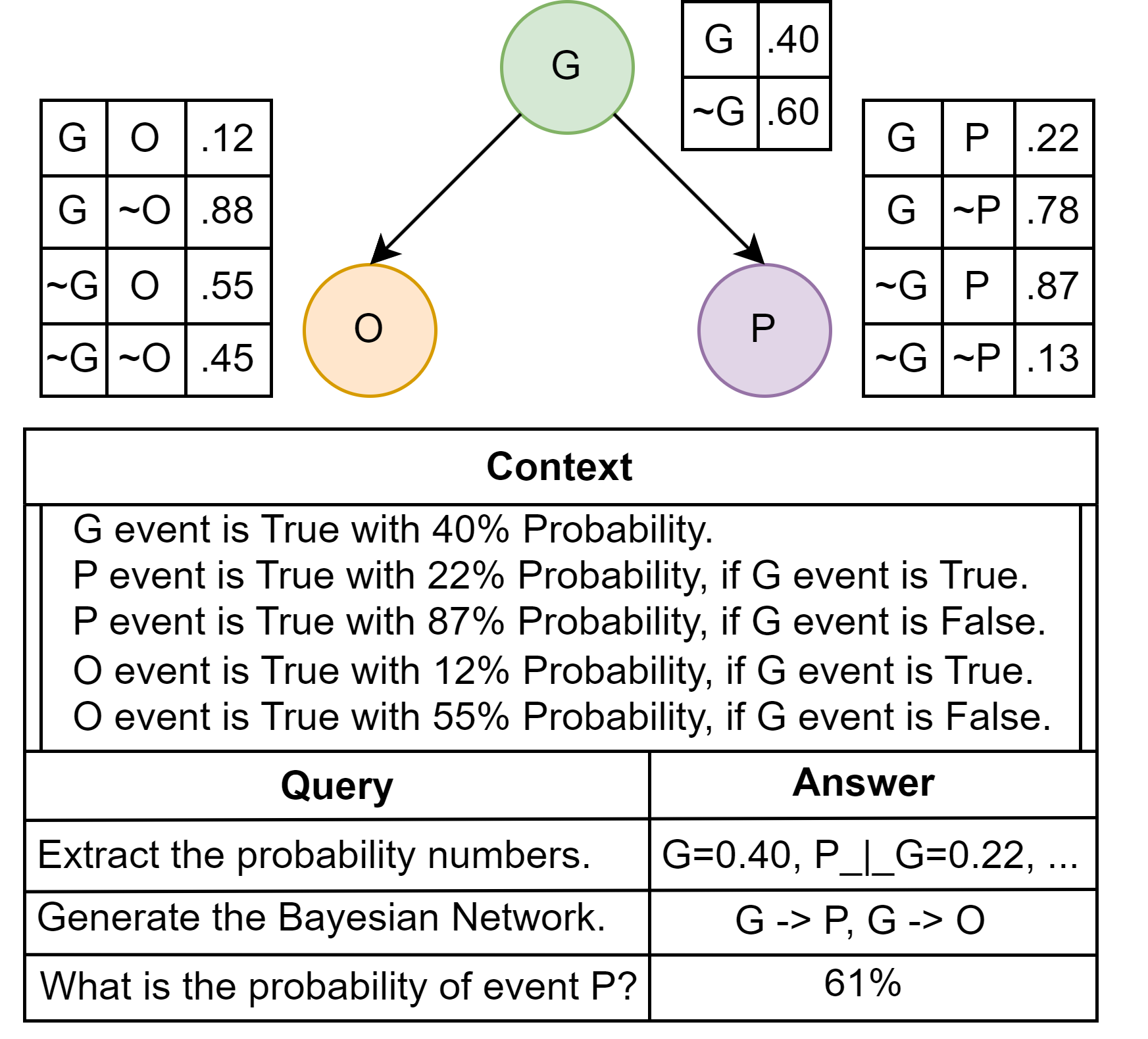
Probabilistic Reasoning in Generative Large Language Models
Aliakbar Nafar, Kristen Brent Venable, Parisa Kordjamshidi
This paper considers the challenges Large Language Models (LLMs) face when reasoning over text that includes information involving uncertainty explicitly quantified via probability values. This type of reasoning is relevant to a variety of contexts ranging from everyday conversations to medical decision-making. Despite improvements in the mathematical reasoning capabilities of LLMs, they still exhibit significant difficulties when it comes to probabilistic reasoning. To deal with this problem, we introduce the Bayesian Linguistic Inference Dataset (BLInD), a new dataset specifically designed to test the probabilistic reasoning capabilities of LLMs. We use BLInD to find out the limitations of LLMs for tasks involving probabilistic reasoning. In addition, we present several prompting strategies that map the problem to different formal representations, including Python code, probabilistic algorithms, and probabilistic logical programming. We conclude by providing an evaluation of our methods on BLInD and an adaptation of a causal reasoning question-answering dataset. Our empirical results highlight the effectiveness of our proposed strategies for multiple LLMs.
Read more6/18/2024