Domain-specific or Uncertainty-aware models: Does it really make a difference for biomedical text classification?

0

Sign in to get full access
Introduction
The paper examines whether using domain-specific or uncertainty-aware models makes a significant difference for biomedical text classification tasks. Biomedical text classification is an important task in the healthcare domain, with applications such as mitigating boundary ambiguity and inherent bias in text classification and developing healthcare language model embedding spaces. The researchers investigate the performance of different model architectures, including domain-specific and uncertainty-aware models, on several biomedical text classification datasets.
Related Work
The paper situates its research within the broader context of large language models for the healthcare and medical domain and studies on German language models for clinical and biomedical applications. It highlights the importance of understanding the impact of model architecture choices on text classification performance, especially in the biomedical domain, where accurate and reliable predictions are crucial.
Plain English Explanation
The researchers wanted to see if using specialized models designed for the biomedical field or models that can show their uncertainty about predictions would perform better than more general language models on biomedical text classification tasks. Biomedical text classification is important for things like automatically organizing medical documents or identifying the topics of clinical notes.
The researchers tested different model types, including ones trained specifically on biomedical data and ones that can express how confident they are in their predictions. They ran these models on several datasets of biomedical text and compared the results.
The key finding was that the specialized biomedical models and the uncertainty-aware models did not significantly outperform more general language models on these tasks. This was surprising, as the researchers expected the specialized models to have an advantage.
Technical Explanation
The paper evaluates the performance of domain-specific and uncertainty-aware models on biomedical text classification tasks. They compare the performance of these models to that of general-purpose language models across several benchmark datasets.
The domain-specific models include BioBERT, a BERT-based model pre-trained on biomedical literature, and ClinicalBERT, a BERT model fine-tuned on clinical notes. The uncertainty-aware models include Dropout-BERT, which uses dropout to estimate prediction uncertainty, and Bayes-BERT, which uses Bayesian inference to quantify uncertainty.
The researchers fine-tune these models on tasks such as disease classification, clinical code prediction, and adverse drug event detection. They measure performance using metrics like F1 score and area under the receiver operating characteristic curve (AUROC).
The results show that the domain-specific and uncertainty-aware models do not significantly outperform the general-purpose BERT model on most tasks. The authors suggest that the benefits of domain-specific pre-training and uncertainty modeling may be limited for these specific text classification problems, and that simpler models can achieve comparable performance.
Critical Analysis
The paper provides a thorough and well-designed study comparing the performance of different model architectures on biomedical text classification tasks. However, the authors acknowledge several limitations and caveats to their findings.
One potential issue is the reliance on benchmark datasets, which may not fully capture the challenges and nuances of real-world biomedical text classification problems. Uncertainty estimation in large language models for medical question answering could be an important consideration in clinical settings that the study does not address.
Additionally, the paper focuses on a limited set of model architectures and does not explore more advanced techniques for domain adaptation or uncertainty quantification. Further research may be needed to fully understand the conditions under which specialized or uncertainty-aware models can provide meaningful benefits.
Conclusion
The study suggests that for the specific biomedical text classification tasks examined, domain-specific and uncertainty-aware models do not necessarily outperform general-purpose language models. This finding challenges the assumption that specialized models are always preferable for domain-specific tasks and highlights the need to carefully evaluate model choices for particular applications.
The results of this paper contribute to the ongoing discussion around the development of healthcare language models and the role of uncertainty quantification in biomedical AI systems. While the findings may not be generalizable to all biomedical text classification problems, they provide a valuable data point for researchers and practitioners working in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Domain-specific or Uncertainty-aware models: Does it really make a difference for biomedical text classification?
Aman Sinha, Timothee Mickus, Marianne Clausel, Mathieu Constant, Xavier Coubez
The success of pretrained language models (PLMs) across a spate of use-cases has led to significant investment from the NLP community towards building domain-specific foundational models. On the other hand, in mission critical settings such as biomedical applications, other aspects also factor in-chief of which is a model's ability to produce reasonable estimates of its own uncertainty. In the present study, we discuss these two desiderata through the lens of how they shape the entropy of a model's output probability distribution. We find that domain specificity and uncertainty awareness can often be successfully combined, but the exact task at hand weighs in much more strongly.
Read more7/18/2024

0
Domain-specific long text classification from sparse relevant information
C'elia D'Cruz, Jean-Marc Bereder, Fr'ed'eric Precioso, Michel Riveill
Large Language Models have undoubtedly revolutionized the Natural Language Processing field, the current trend being to promote one-model-for-all tasks (sentiment analysis, translation, etc.). However, the statistical mechanisms at work in the larger language models struggle to exploit the relevant information when it is very sparse, when it is a weak signal. This is the case, for example, for the classification of long domain-specific documents, when the relevance relies on a single relevant word or on very few relevant words from technical jargon. In the medical domain, it is essential to determine whether a given report contains critical information about a patient's condition. This critical information is often based on one or few specific isolated terms. In this paper, we propose a hierarchical model which exploits a short list of potential target terms to retrieve candidate sentences and represent them into the contextualized embedding of the target term(s) they contain. A pooling of the term(s) embedding(s) entails the document representation to be classified. We evaluate our model on one public medical document benchmark in English and on one private French medical dataset. We show that our narrower hierarchical model is better than larger language models for retrieving relevant long documents in a domain-specific context.
Read more8/26/2024

0
Domain-Specific Pretraining of Language Models: A Comparative Study in the Medical Field
Tobias Kerner
There are many cases where LLMs are used for specific tasks in a single domain. These usually require less general, but more domain-specific knowledge. Highly capable, general-purpose state-of-the-art language models like GPT-4 or Claude-3-opus can often be used for such tasks, but they are very large and cannot be run locally, even if they were not proprietary. This can be a problem when working with sensitive data. This paper focuses on domain-specific and mixed-domain pretraining as potentially more efficient methods than general pretraining for specialized language models. We will take a look at work related to domain-specific pretraining, specifically in the medical area, and compare benchmark results of specialized language models to general-purpose language models.
Read more7/30/2024
0
Biomedical Large Languages Models Seem not to be Superior to Generalist Models on Unseen Medical Data
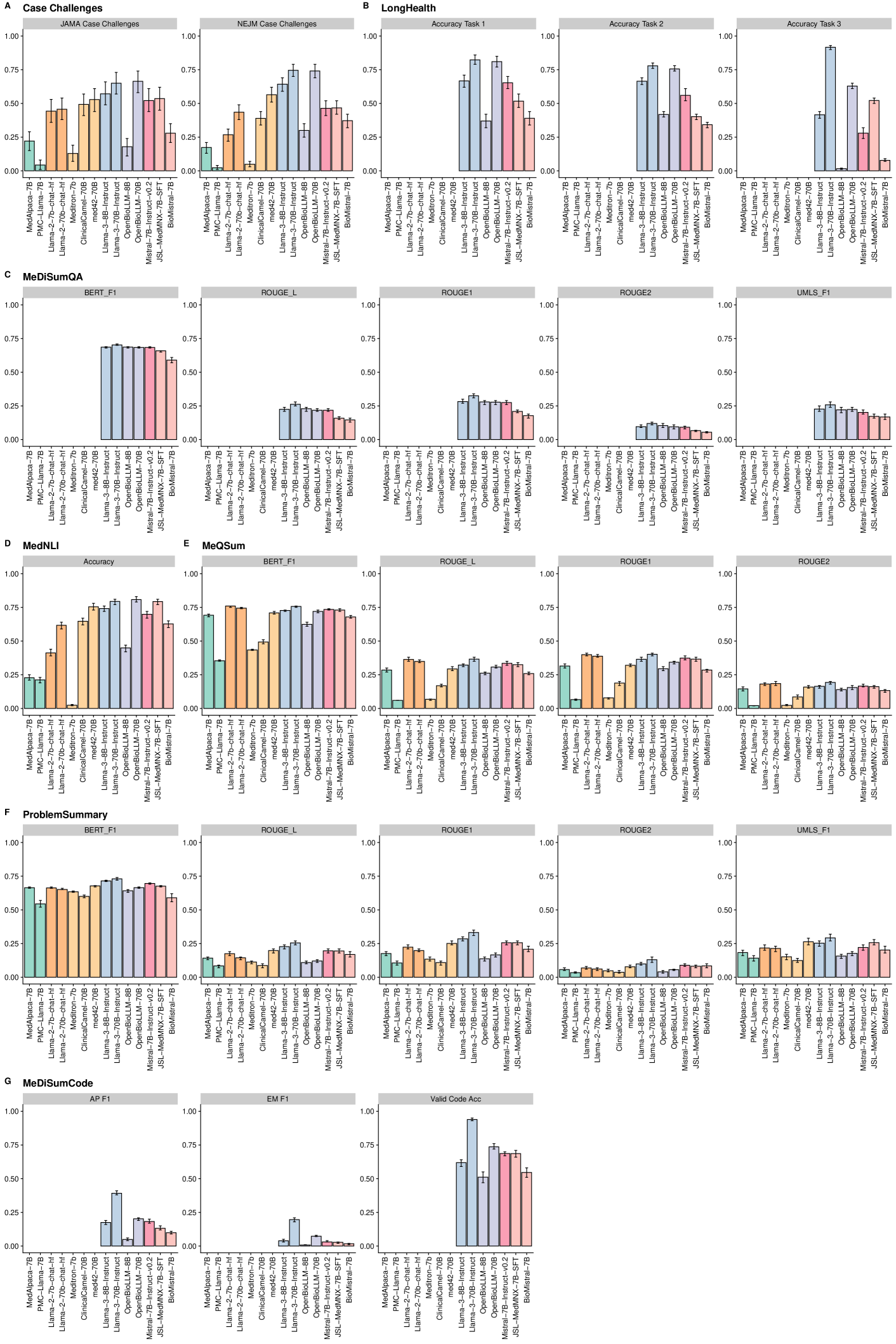
Felix J. Dorfner, Amin Dada, Felix Busch, Marcus R. Makowski, Tianyu Han, Daniel Truhn, Jens Kleesiek, Madhumita Sushil, Jacqueline Lammert, Lisa C. Adams, Keno K. Bressem
Large language models (LLMs) have shown potential in biomedical applications, leading to efforts to fine-tune them on domain-specific data. However, the effectiveness of this approach remains unclear. This study evaluates the performance of biomedically fine-tuned LLMs against their general-purpose counterparts on a variety of clinical tasks. We evaluated their performance on clinical case challenges from the New England Journal of Medicine (NEJM) and the Journal of the American Medical Association (JAMA) and on several clinical tasks (e.g., information extraction, document summarization, and clinical coding). Using benchmarks specifically chosen to be likely outside the fine-tuning datasets of biomedical models, we found that biomedical LLMs mostly perform inferior to their general-purpose counterparts, especially on tasks not focused on medical knowledge. While larger models showed similar performance on case tasks (e.g., OpenBioLLM-70B: 66.4% vs. Llama-3-70B-Instruct: 65% on JAMA cases), smaller biomedical models showed more pronounced underperformance (e.g., OpenBioLLM-8B: 30% vs. Llama-3-8B-Instruct: 64.3% on NEJM cases). Similar trends were observed across the CLUE (Clinical Language Understanding Evaluation) benchmark tasks, with general-purpose models often performing better on text generation, question answering, and coding tasks. Our results suggest that fine-tuning LLMs to biomedical data may not provide the expected benefits and may potentially lead to reduced performance, challenging prevailing assumptions about domain-specific adaptation of LLMs and highlighting the need for more rigorous evaluation frameworks in healthcare AI. Alternative approaches, such as retrieval-augmented generation, may be more effective in enhancing the biomedical capabilities of LLMs without compromising their general knowledge.
Read more8/27/2024