Dynamic Sentiment Analysis with Local Large Language Models using Majority Voting: A Study on Factors Affecting Restaurant Evaluation

0

Sign in to get full access
Overview
- This paper explores the use of local large language models and majority voting for dynamic sentiment analysis on restaurant reviews.
- The researchers investigate factors that can affect the evaluation of restaurants, such as sentiment, review length, and reviewer characteristics.
- The study aims to provide insights into the potential and limitations of using large language models for sentiment analysis in a real-world application.
Plain English Explanation
In this paper, the researchers looked at how to use large language models and a voting system to analyze the sentiment (positive or negative feelings) in reviews of restaurants. They wanted to understand what factors might influence how people evaluate restaurants, such as the tone of the review, how long the review is, and who wrote the review.
The researchers used large language models, which are powerful artificial intelligence systems that can understand and generate human-like text. They trained these models on restaurant reviews and then used them to analyze new reviews, looking at whether the overall sentiment was positive or negative.
To make the analysis more accurate, the researchers used a "majority voting" system. This means they had multiple large language models look at each review, and they went with the sentiment that most of the models agreed on. This helped to reduce any biases or errors that a single model might make.
The goal of the study was to provide insights into how well these large language models can be used for real-world applications like analyzing customer feedback on restaurants. The researchers wanted to understand both the potential benefits and limitations of using this technology for sentiment analysis.
Technical Explanation
The researchers used a majority voting approach to combine the sentiment predictions of multiple local large language models. This helped to improve the consistency and robustness of the sentiment analysis.
They trained the language models on a dataset of restaurant reviews, then used them to analyze new reviews and classify the overall sentiment as positive or negative. The researchers also looked at factors like review length, reviewer characteristics, and the specific aspects of the restaurant mentioned in the reviews to see how they affected the sentiment analysis.
The results showed that the majority voting approach was effective at scaling the technology acceptance of the sentiment analysis system. However, the researchers also found that the large language models were not perfect, and their effectiveness as annotators varied depending on factors like the complexity of the review text.
Critical Analysis
The paper provides a thorough exploration of using large language models for sentiment analysis in a real-world application. The researchers acknowledge the limitations of the technology, noting that the large language models were not always consistent or accurate in their predictions, especially for more complex review texts.
One potential issue not addressed in the paper is the potential for large language models to exhibit biases based on the data they are trained on. This could lead to inaccuracies or blind spots in the sentiment analysis, and the researchers do not discuss how they might have addressed this concern.
Additionally, the paper does not delve deeply into the specific architectural choices or training techniques used for the large language models. More details on these elements could have provided valuable insights for researchers and practitioners interested in replicating or building upon this work.
Overall, the paper presents a meaningful and well-designed study that offers valuable insights into the practical application of large language models for sentiment analysis. The researchers' acknowledgment of the technology's limitations and areas for further exploration demonstrates a commendable level of critical thinking and objectivity.
Conclusion
This paper explores the use of local large language models and majority voting for dynamic sentiment analysis on restaurant reviews. The researchers investigate factors that can affect the evaluation of restaurants, such as sentiment, review length, and reviewer characteristics.
The study provides insights into the potential and limitations of using large language models for sentiment analysis in a real-world application. While the majority voting approach was effective at scaling the technology acceptance of the sentiment analysis system, the researchers found that the large language models were not perfect and their effectiveness varied depending on the complexity of the review text.
The paper's critical analysis of the technology's limitations and areas for further exploration highlights the importance of a nuanced understanding of the capabilities and biases of large language models. This research contributes to the growing body of work exploring the practical applications and challenges of utilizing these powerful AI systems in diverse domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dynamic Sentiment Analysis with Local Large Language Models using Majority Voting: A Study on Factors Affecting Restaurant Evaluation
Junichiro Niimi
User-generated contents (UGCs) on online platforms allow marketing researchers to understand consumer preferences for products and services. With the advance of large language models (LLMs), some studies utilized the models for annotation and sentiment analysis. However, the relationship between the accuracy and the hyper-parameters of LLMs is yet to be thoroughly examined. In addition, the issues of variability and reproducibility of results from each trial of LLMs have rarely been considered in existing literature. Since actual human annotation uses majority voting to resolve disagreements among annotators, this study introduces a majority voting mechanism to a sentiment analysis model using local LLMs. By a series of three analyses of online reviews on restaurant evaluations, we demonstrate that majority voting with multiple attempts using a medium-sized model produces more robust results than using a large model with a single attempt. Furthermore, we conducted further analysis to investigate the effect of each aspect on the overall evaluation.
Read more7/19/2024

0
Do Large Language Models Possess Sensitive to Sentiment?
Yang Liu, Xichou Zhu, Zhou Shen, Yi Liu, Min Li, Yujun Chen, Benzi John, Zhenzhen Ma, Tao Hu, Zhiyang Xu, Wei Luo, Junhui Wang
Large Language Models (LLMs) have recently displayed their extraordinary capabilities in language understanding. However, how to comprehensively assess the sentiment capabilities of LLMs continues to be a challenge. This paper investigates the ability of LLMs to detect and react to sentiment in text modal. As the integration of LLMs into diverse applications is on the rise, it becomes highly critical to comprehend their sensitivity to emotional tone, as it can influence the user experience and the efficacy of sentiment-driven tasks. We conduct a series of experiments to evaluate the performance of several prominent LLMs in identifying and responding appropriately to sentiments like positive, negative, and neutral emotions. The models' outputs are analyzed across various sentiment benchmarks, and their responses are compared with human evaluations. Our discoveries indicate that although LLMs show a basic sensitivity to sentiment, there are substantial variations in their accuracy and consistency, emphasizing the requirement for further enhancements in their training processes to better capture subtle emotional cues. Take an example in our findings, in some cases, the models might wrongly classify a strongly positive sentiment as neutral, or fail to recognize sarcasm or irony in the text. Such misclassifications highlight the complexity of sentiment analysis and the areas where the models need to be refined. Another aspect is that different LLMs might perform differently on the same set of data, depending on their architecture and training datasets. This variance calls for a more in-depth study of the factors that contribute to the performance differences and how they can be optimized.
Read more9/5/2024
💬
0
Scaling Technology Acceptance Analysis with Large Language Model (LLM) Annotation Systems
Pawel Robert Smolinski, Joseph Januszewicz, Jacek Winiarski
Technology acceptance models effectively predict how users will adopt new technology products. Traditional surveys, often expensive and cumbersome, are commonly used for this assessment. As an alternative to surveys, we explore the use of large language models for annotating online user-generated content, like digital reviews and comments. Our research involved designing an LLM annotation system that transform reviews into structured data based on the Unified Theory of Acceptance and Use of Technology model. We conducted two studies to validate the consistency and accuracy of the annotations. Results showed moderate-to-strong consistency of LLM annotation systems, improving further by lowering the model temperature. LLM annotations achieved close agreement with human expert annotations and outperformed the agreement between experts for UTAUT variables. These results suggest that LLMs can be an effective tool for analyzing user sentiment, offering a practical alternative to traditional survey methods and enabling deeper insights into technology design and adoption.
Read more7/2/2024
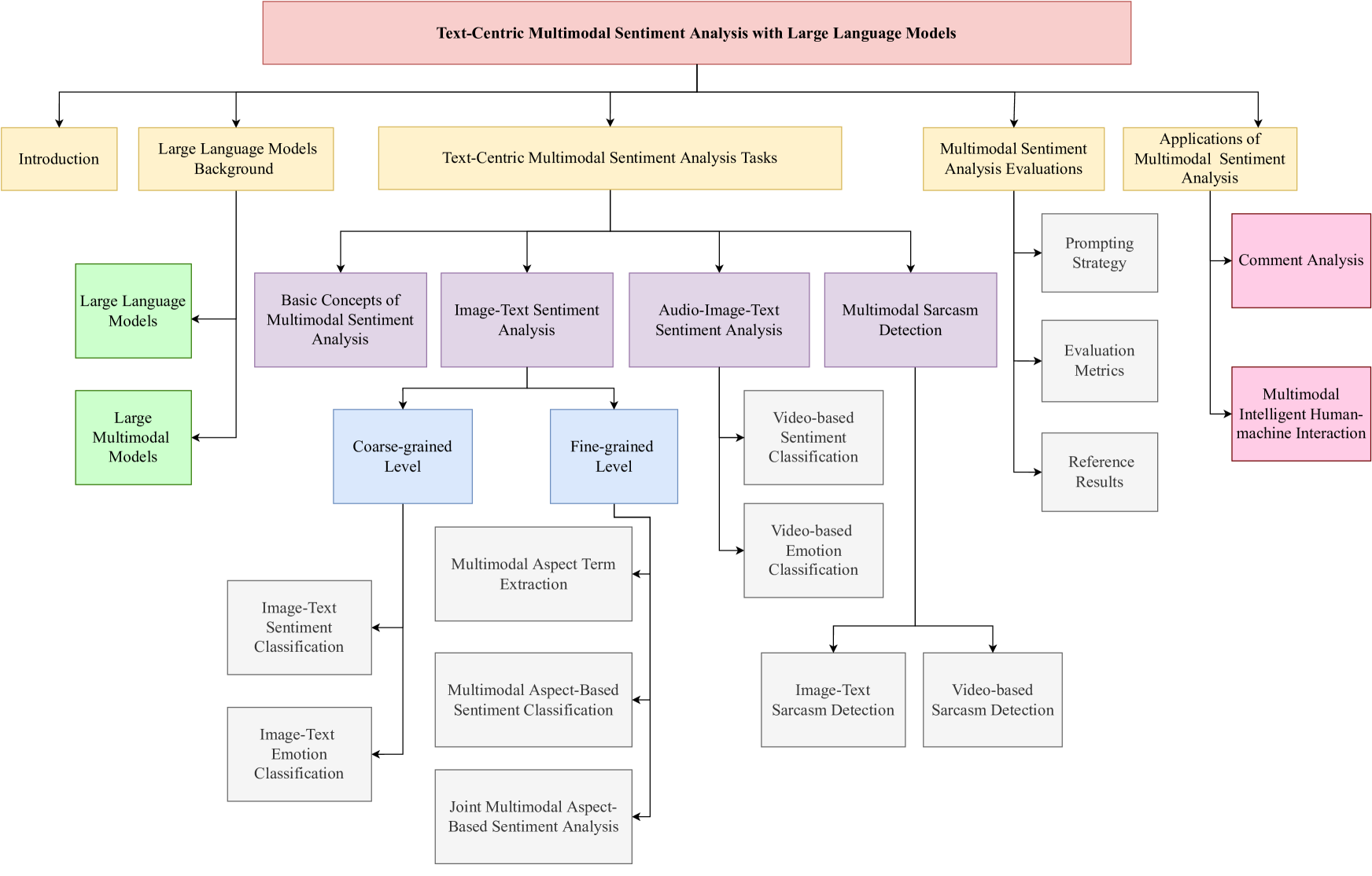
0
Large Language Models Meet Text-Centric Multimodal Sentiment Analysis: A Survey
Hao Yang, Yanyan Zhao, Yang Wu, Shilong Wang, Tian Zheng, Hongbo Zhang, Zongyang Ma, Wanxiang Che, Bing Qin
Compared to traditional sentiment analysis, which only considers text, multimodal sentiment analysis needs to consider emotional signals from multimodal sources simultaneously and is therefore more consistent with the way how humans process sentiment in real-world scenarios. It involves processing emotional information from various sources such as natural language, images, videos, audio, physiological signals, etc. However, although other modalities also contain diverse emotional cues, natural language usually contains richer contextual information and therefore always occupies a crucial position in multimodal sentiment analysis. The emergence of ChatGPT has opened up immense potential for applying large language models (LLMs) to text-centric multimodal tasks. However, it is still unclear how existing LLMs can adapt better to text-centric multimodal sentiment analysis tasks. This survey aims to (1) present a comprehensive review of recent research in text-centric multimodal sentiment analysis tasks, (2) examine the potential of LLMs for text-centric multimodal sentiment analysis, outlining their approaches, advantages, and limitations, (3) summarize the application scenarios of LLM-based multimodal sentiment analysis technology, and (4) explore the challenges and potential research directions for multimodal sentiment analysis in the future.
Read more8/19/2024