EconNLI: Evaluating Large Language Models on Economics Reasoning

0

Sign in to get full access
Overview
- This paper, "EconNLI: Evaluating Large Language Models on Economics Reasoning," presents a new benchmark dataset and evaluation framework for assessing the performance of large language models (LLMs) on economic reasoning tasks.
- The authors create EconNLI, a dataset of over 10,000 natural language inference problems related to economic concepts and principles, to test the ability of LLMs to understand and reason about economic phenomena.
- They evaluate several prominent LLMs, including GPT-3, PaLM, and Megatron-Turing NLG, on the EconNLI dataset and provide insights into the strengths and limitations of these models in tackling economic reasoning challenges.
Plain English Explanation
The paper introduces a new way to test how well large AI language models, such as GPT-3 and PaLM, can understand and reason about economic concepts and principles. The researchers created a dataset called EconNLI, which contains over 10,000 questions that require economic reasoning to answer correctly.
For example, one question might ask whether a raise in the minimum wage would lead to higher unemployment. To answer this, the AI model would need to understand economic principles like supply and demand, and how changes in the labor market can impact employment. The researchers then evaluated several prominent language models on this EconNLI dataset to see how well they could perform on these types of economic reasoning tasks.
The results provide insights into the capabilities and limitations of these large language models when it comes to economic understanding. This information can help guide the development of more economically-aware AI systems in the future. By creating specialized benchmarks like EconNLI, researchers can better assess and improve the economic reasoning abilities of AI models over time.
Technical Explanation
The authors introduce the EconNLI dataset, a new benchmark for evaluating the economic reasoning capabilities of large language models (LLMs). EconNLI contains over 10,000 natural language inference problems designed to test an LLM's understanding of core economic concepts and principles.
The authors evaluate several prominent LLMs, including GPT-3, PaLM, and Megatron-Turing NLG, on the EconNLI dataset. They find that while these models exhibit some economic reasoning capabilities, they also have significant limitations. For example, the models struggle with tasks that require understanding of economic concepts like opportunity cost, comparative advantage, and the impacts of policy changes.
The authors also investigate the factors that contribute to an LLM's economic reasoning performance, such as model size, pretraining data, and fine-tuning. Their analysis provides insights into how to improve the economic reasoning abilities of future LLMs.
Critical Analysis
The EconNLI benchmark represents an important step towards more comprehensive evaluation of LLMs' reasoning capabilities beyond just language understanding. By focusing on economic reasoning, the authors highlight a key limitation of current LLMs and the need for further advancements in this area.
However, the paper acknowledges several caveats and limitations of the study. For instance, the dataset may not fully capture the breadth and complexity of real-world economic reasoning, and the evaluation is limited to a set of predefined tasks. Additionally, the paper does not explore the potential of fine-tuning or other techniques to improve the economic reasoning of LLMs.
Further research is needed to better understand the factors that contribute to economic reasoning in LLMs, as well as to develop more comprehensive evaluation frameworks that capture a wider range of economic phenomena. Exploring the interpretability and transparency of LLMs' economic reasoning processes could also yield valuable insights.
Conclusion
The "EconNLI: Evaluating Large Language Models on Economics Reasoning" paper presents a novel benchmark for assessing the economic reasoning capabilities of large language models. By creating the EconNLI dataset and evaluating prominent LLMs, the authors provide valuable insights into the current limitations of these models when it comes to understanding and reasoning about economic concepts and principles.
This research highlights the importance of developing more economically-aware AI systems and the need for continued advancements in language model architecture and training. The EconNLI benchmark can serve as a foundation for future research and development in this area, ultimately contributing to the creation of AI systems that can better support decision-making and problem-solving in the economic domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
EconNLI: Evaluating Large Language Models on Economics Reasoning
Yue Guo, Yi Yang
Large Language Models (LLMs) are widely used for writing economic analysis reports or providing financial advice, but their ability to understand economic knowledge and reason about potential results of specific economic events lacks systematic evaluation. To address this gap, we propose a new dataset, natural language inference on economic events (EconNLI), to evaluate LLMs' knowledge and reasoning abilities in the economic domain. We evaluate LLMs on (1) their ability to correctly classify whether a premise event will cause a hypothesis event and (2) their ability to generate reasonable events resulting from a given premise. Our experiments reveal that LLMs are not sophisticated in economic reasoning and may generate wrong or hallucinated answers. Our study raises awareness of the limitations of using LLMs for critical decision-making involving economic reasoning and analysis. The dataset and codes are available at https://github.com/Irenehere/EconNLI.
Read more7/2/2024
0
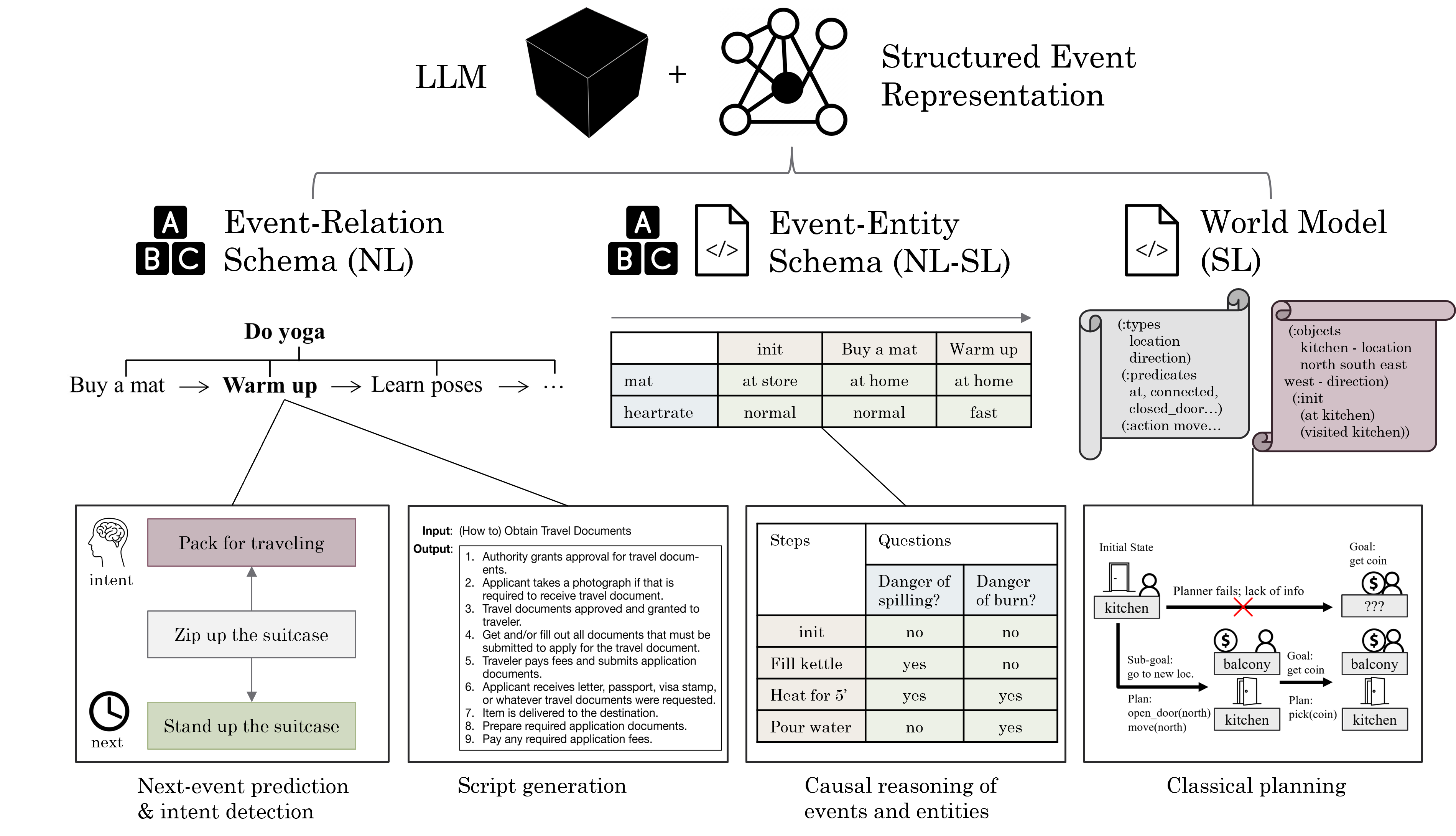
Structured Event Reasoning with Large Language Models
Li Zhang
Reasoning about real-life events is a unifying challenge in AI and NLP that has profound utility in a variety of domains, while fallacy in high-stake applications could be catastrophic. Able to work with diverse text in these domains, large language models (LLMs) have proven capable of answering questions and solving problems. However, I show that end-to-end LLMs still systematically fail to reason about complex events, and they lack interpretability due to their black-box nature. To address these issues, I propose three general approaches to use LLMs in conjunction with a structured representation of events. The first is a language-based representation involving relations of sub-events that can be learned by LLMs via fine-tuning. The second is a semi-symbolic representation involving states of entities that can be predicted and leveraged by LLMs via few-shot prompting. The third is a fully symbolic representation that can be predicted by LLMs trained with structured data and be executed by symbolic solvers. On a suite of event reasoning tasks spanning common-sense inference and planning, I show that each approach greatly outperforms end-to-end LLMs with more interpretability. These results suggest manners of synergy between LLMs and structured representations for event reasoning and beyond.
Read more8/30/2024

0
A Comprehensive Evaluation on Event Reasoning of Large Language Models
Zhengwei Tao, Zhi Jin, Yifan Zhang, Xiancai Chen, Haiyan Zhao, Jia Li, Bing Liang, Chongyang Tao, Qun Liu, Kam-Fai Wong
Event reasoning is a fundamental ability that underlies many applications. It requires event schema knowledge to perform global reasoning and needs to deal with the diversity of the inter-event relations and the reasoning paradigms. How well LLMs accomplish event reasoning on various relations and reasoning paradigms remains unknown. To mitigate this disparity, we comprehensively evaluate the abilities of event reasoning of LLMs. We introduce a novel benchmark EV2 for EValuation of EVent reasoning. EV2 consists of two levels of evaluation of schema and instance and is comprehensive in relations and reasoning paradigms. We conduct extensive experiments on EV2. We find that LLMs have abilities to accomplish event reasoning but their performances are far from satisfactory. We also notice the imbalance of event reasoning abilities in LLMs. Besides, LLMs have event schema knowledge, however, they're not aligned with humans on how to utilize the knowledge. Based on these findings, we guide the LLMs in utilizing the event schema knowledge as memory leading to improvements on event reasoning.
Read more8/6/2024
💬
0
EconLogicQA: A Question-Answering Benchmark for Evaluating Large Language Models in Economic Sequential Reasoning
Yinzhu Quan, Zefang Liu
In this paper, we introduce EconLogicQA, a rigorous benchmark designed to assess the sequential reasoning capabilities of large language models (LLMs) within the intricate realms of economics, business, and supply chain management. Diverging from traditional benchmarks that predict subsequent events individually, EconLogicQA poses a more challenging task: it requires models to discern and sequence multiple interconnected events, capturing the complexity of economic logics. EconLogicQA comprises an array of multi-event scenarios derived from economic articles, which necessitate an insightful understanding of both temporal and logical event relationships. Through comprehensive evaluations, we exhibit that EconLogicQA effectively gauges a LLM's proficiency in navigating the sequential complexities inherent in economic contexts. We provide a detailed description of EconLogicQA dataset and shows the outcomes from evaluating the benchmark across various leading-edge LLMs, thereby offering a thorough perspective on their sequential reasoning potential in economic contexts. Our benchmark dataset is available at https://huggingface.co/datasets/yinzhu-quan/econ_logic_qa.
Read more5/14/2024