Thompson Sampling for Infinite-Horizon Discounted Decision Processes
2405.08253
0
0
🛠️
Abstract
We model a Markov decision process, parametrized by an unknown parameter, and study the asymptotic behavior of a sampling-based algorithm, called Thompson sampling. The standard definition of regret is not always suitable to evaluate a policy, especially when the underlying chain structure is general. We show that the standard (expected) regret can grow (super-)linearly and fails to capture the notion of learning in realistic settings with non-trivial state evolution. By decomposing the standard (expected) regret, we develop a new metric, called the expected residual regret, which forgets the immutable consequences of past actions. Instead, it measures regret against the optimal reward moving forward from the current period. We show that the expected residual regret of the Thompson sampling algorithm is upper bounded by a term which converges exponentially fast to 0. We present conditions under which the posterior sampling error of Thompson sampling converges to 0 almost surely. We then introduce the probabilistic version of the expected residual regret and present conditions under which it converges to 0 almost surely. Thus, we provide a viable concept of learning for sampling algorithms which will serve useful in broader settings than had been considered previously.
Create account to get full access
Overview
- The paper models a Markov decision process with an unknown parameter and studies the behavior of a sampling-based algorithm called Thompson sampling.
- The standard definition of regret (the difference between the optimal reward and the obtained reward) is not always suitable, especially when the underlying chain structure is general.
- The authors introduce a new metric called the "expected residual regret" that focuses on the optimal reward moving forward from the current period, rather than the immutable consequences of past actions.
- They show that the expected residual regret of Thompson sampling is upper bounded by a term that converges exponentially fast to 0.
- They also present conditions under which the posterior sampling error and the probabilistic version of the expected residual regret converge to 0 almost surely.
Plain English Explanation
In this paper, the researchers are studying a type of decision-making algorithm called Thompson sampling. Thompson sampling is a way for an algorithm to learn and make decisions under uncertainty, by repeatedly sampling from a probability distribution that represents the algorithm's current beliefs about the best course of action.
The researchers are looking at how well Thompson sampling performs in a specific type of decision-making problem called a Markov decision process, where the outcomes of actions depend on the current state of the system. They find that the standard way of measuring the performance of Thompson sampling, called "regret," doesn't always work well, especially when the underlying system is complex.
To address this, the researchers introduce a new way of measuring performance called the "expected residual regret." This metric focuses on how well the algorithm is doing in the present and future, rather than dwelling on past mistakes that can't be undone. They show that Thompson sampling has a strong performance guarantee using this new metric - its expected residual regret converges to 0 exponentially fast.
The researchers also provide conditions under which the algorithm's internal beliefs (its "posterior sampling error") and the probabilistic version of the expected residual regret both converge to 0 almost surely, meaning the algorithm is learning and performing well with high probability.
Overall, this research provides a more nuanced and useful way to evaluate the performance of Thompson sampling and similar decision-making algorithms, which could be valuable in a wide range of real-world applications.
Technical Explanation
The paper models a Markov decision process with an unknown parameter and studies the asymptotic behavior of the Thompson sampling algorithm. The standard definition of regret (the difference between the optimal reward and the obtained reward) is not always suitable to evaluate a policy, especially when the underlying chain structure is general.
The authors show that the standard (expected) regret can grow (super-)linearly and fails to capture the notion of learning in realistic settings with non-trivial state evolution. To address this, they develop a new metric called the "expected residual regret," which measures regret against the optimal reward moving forward from the current period, rather than the immutable consequences of past actions.
The authors prove that the expected residual regret of the Thompson sampling algorithm is upper bounded by a term that converges exponentially fast to 0. They also present conditions under which the posterior sampling error of Thompson sampling converges to 0 almost surely, as well as conditions under which the probabilistic version of the expected residual regret converges to 0 almost surely.
These results provide a more viable concept of learning for sampling algorithms, which can be useful in a broader range of settings than had been considered previously.
Critical Analysis
The paper introduces a novel concept, the "expected residual regret," that addresses limitations of the standard regret metric when evaluating the performance of Thompson sampling in complex Markov decision processes. This new metric is a valuable contribution, as it allows for a more nuanced understanding of an algorithm's learning and decision-making capabilities.
One potential limitation of the research is that the theoretical guarantees are derived under specific conditions, such as the assumptions made about the Markov decision process and the algorithm's ability to accurately estimate the posterior distribution. It would be interesting to see how these results hold up in more realistic, noisy, or adversarial settings.
Additionally, the paper does not provide any empirical validation of the proposed expected residual regret metric. While the theoretical analysis is compelling, it would be helpful to see how this new metric performs in practice, particularly in comparison to the standard regret measure.
Furthermore, the paper does not discuss the computational complexity of the Thompson sampling algorithm or the proposed analysis. Understanding the scalability of these methods would be important for their real-world applicability, especially in large-scale or high-stakes decision-making scenarios.
Overall, this research presents a promising new approach to evaluating the performance of Thompson sampling and similar sampling-based algorithms. Further empirical validation and analysis of the practical implications would help strengthen the impact of this work.
Conclusion
This paper introduces a new metric, the "expected residual regret," to evaluate the performance of the Thompson sampling algorithm in the context of Markov decision processes with unknown parameters. The authors show that the expected residual regret of Thompson sampling is upper bounded by a term that converges exponentially fast to 0, and they present conditions under which the posterior sampling error and the probabilistic version of the expected residual regret also converge to 0 almost surely.
This research provides a more nuanced and useful way to assess the learning and decision-making capabilities of Thompson sampling and similar sampling-based algorithms, which could be valuable in a wide range of real-world applications where the underlying system dynamics are complex and the standard regret metric may not be sufficient.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Efficient and Adaptive Posterior Sampling Algorithms for Bandits
Bingshan Hu, Zhiming Huang, Tianyue H. Zhang, Mathias L'ecuyer, Nidhi Hegde
0
0
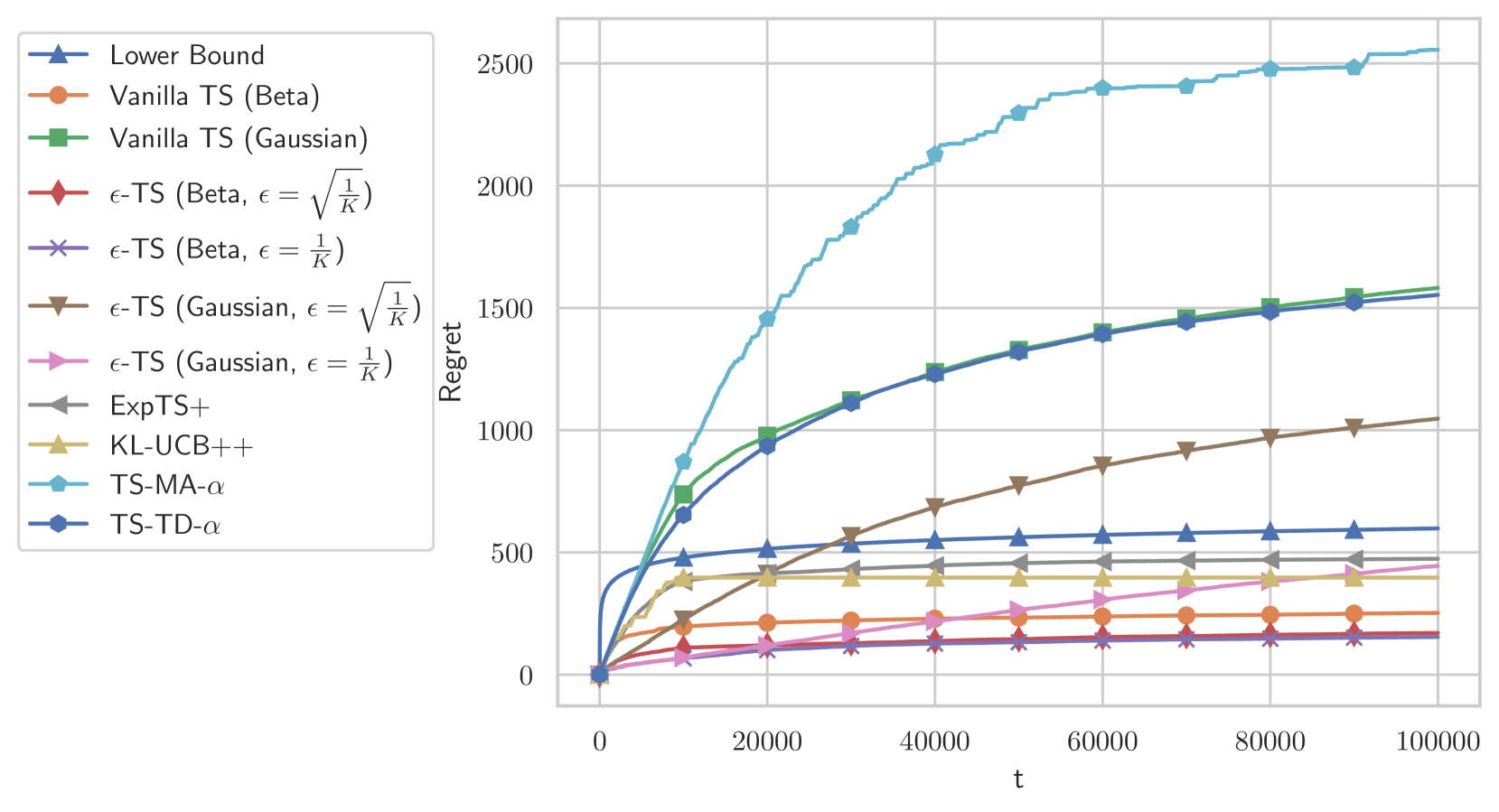
We study Thompson Sampling-based algorithms for stochastic bandits with bounded rewards. As the existing problem-dependent regret bound for Thompson Sampling with Gaussian priors [Agrawal and Goyal, 2017] is vacuous when $T le 288 e^{64}$, we derive a more practical bound that tightens the coefficient of the leading term %from $288 e^{64}$ to $1270$. Additionally, motivated by large-scale real-world applications that require scalability, adaptive computational resource allocation, and a balance in utility and computation, we propose two parameterized Thompson Sampling-based algorithms: Thompson Sampling with Model Aggregation (TS-MA-$alpha$) and Thompson Sampling with Timestamp Duelling (TS-TD-$alpha$), where $alpha in [0,1]$ controls the trade-off between utility and computation. Both algorithms achieve $O left(Kln^{alpha+1}(T)/Delta right)$ regret bound, where $K$ is the number of arms, $T$ is the finite learning horizon, and $Delta$ denotes the single round performance loss when pulling a sub-optimal arm.
5/3/2024
🌀
Approximate Thompson Sampling for Learning Linear Quadratic Regulators with $O(sqrt{T})$ Regret
Yeoneung Kim, Gihun Kim, Insoon Yang
0
0
We propose an approximate Thompson sampling algorithm that learns linear quadratic regulators (LQR) with an improved Bayesian regret bound of $O(sqrt{T})$. Our method leverages Langevin dynamics with a meticulously designed preconditioner as well as a simple excitation mechanism. We show that the excitation signal induces the minimum eigenvalue of the preconditioner to grow over time, thereby accelerating the approximate posterior sampling process. Moreover, we identify nontrivial concentration properties of the approximate posteriors generated by our algorithm. These properties enable us to bound the moments of the system state and attain an $O(sqrt{T})$ regret bound without the unrealistic restrictive assumptions on parameter sets that are often used in the literature.
5/31/2024
Efficient Exploration in Average-Reward Constrained Reinforcement Learning: Achieving Near-Optimal Regret With Posterior Sampling
Danil Provodin, Maurits Kaptein, Mykola Pechenizkiy
0
0
We present a new algorithm based on posterior sampling for learning in Constrained Markov Decision Processes (CMDP) in the infinite-horizon undiscounted setting. The algorithm achieves near-optimal regret bounds while being advantageous empirically compared to the existing algorithms. Our main theoretical result is a Bayesian regret bound for each cost component of $tilde{O} (DSsqrt{AT})$ for any communicating CMDP with $S$ states, $A$ actions, and diameter $D$. This regret bound matches the lower bound in order of time horizon $T$ and is the best-known regret bound for communicating CMDPs achieved by a computationally tractable algorithm. Empirical results show that our posterior sampling algorithm outperforms the existing algorithms for constrained reinforcement learning.
5/30/2024

More Efficient Randomized Exploration for Reinforcement Learning via Approximate Sampling
Haque Ishfaq, Yixin Tan, Yu Yang, Qingfeng Lan, Jianfeng Lu, A. Rupam Mahmood, Doina Precup, Pan Xu
0
0
Thompson sampling (TS) is one of the most popular exploration techniques in reinforcement learning (RL). However, most TS algorithms with theoretical guarantees are difficult to implement and not generalizable to Deep RL. While the emerging approximate sampling-based exploration schemes are promising, most existing algorithms are specific to linear Markov Decision Processes (MDP) with suboptimal regret bounds, or only use the most basic samplers such as Langevin Monte Carlo. In this work, we propose an algorithmic framework that incorporates different approximate sampling methods with the recently proposed Feel-Good Thompson Sampling (FGTS) approach (Zhang, 2022; Dann et al., 2021), which was previously known to be computationally intractable in general. When applied to linear MDPs, our regret analysis yields the best known dependency of regret on dimensionality, surpassing existing randomized algorithms. Additionally, we provide explicit sampling complexity for each employed sampler. Empirically, we show that in tasks where deep exploration is necessary, our proposed algorithms that combine FGTS and approximate sampling perform significantly better compared to other strong baselines. On several challenging games from the Atari 57 suite, our algorithms achieve performance that is either better than or on par with other strong baselines from the deep RL literature.
6/19/2024