Efficient Fusion and Task Guided Embedding for End-to-end Autonomous Driving

0

Sign in to get full access
Overview
- Presents a novel end-to-end autonomous driving model called EfficientFuser that combines multi-modal inputs efficiently
- Introduces a task-guided embedding module to learn representations that are tailored for the driving task
- Demonstrates superior performance on standard autonomous driving benchmarks compared to previous state-of-the-art methods
Plain English Explanation
EfficientFuser is a new deep learning model for autonomous driving that takes in different types of sensor data, like camera images, radar, and lidar, and combines them in an efficient way to make driving decisions. Traditional methods often struggle to fuse these diverse data sources effectively. EfficientFuser solves this by including a specialized module that learns embeddings, or compact representations, of the input data that are tailored for the specific task of driving. This helps the model better understand the driving context and make more accurate predictions about things like the car's trajectory, obstacles, and traffic signals. The researchers show that EfficientFuser outperforms previous state-of-the-art autonomous driving models on standard benchmark tests, demonstrating its effectiveness.
Technical Explanation
The key innovation in EfficientFuser is the inclusion of a task-guided embedding module that learns representations of the multi-modal sensor inputs that are optimized for the end-to-end driving task. This contrasts with previous fusion approaches that relied on generic feature extractors.
EfficientFuser first passes the raw sensor data (e.g. camera, lidar, radar) through separate backbone networks to produce modality-specific feature maps. These features are then fused using a novel cross-attention mechanism that dynamically weights the relative importance of each modality based on the driving context.
The fused features are then passed through the task-guided embedding module, which learns a compressed representation optimized for predicting driving actions and other downstream driving-related outputs. This helps the model focus on the most relevant information for the task at hand.
Experiments on standard autonomous driving benchmarks like CARLA and nuScenes show that EfficientFuser significantly outperforms previous multi-modal fusion and end-to-end driving approaches in terms of metrics like trajectory prediction accuracy and semantic segmentation.
Critical Analysis
The authors acknowledge that EfficientFuser, like other end-to-end driving models, has limitations in its ability to generalize to new environments and handle rare edge cases. Further research is needed to improve the robustness and safety of such systems. Additionally, the computational efficiency of the model could be further optimized for real-world deployment.
While the task-guided embedding module is a novel contribution, the authors do not provide a detailed analysis of how these learned representations differ from generic feature extractors. An ablation study examining the importance of this module would strengthen the claims about its benefits.
Overall, EfficientFuser represents a promising step forward in developing more capable and efficient autonomous driving systems. However, significant challenges remain in transitioning such research prototypes to reliable, deployable technologies.
Conclusion
EfficientFuser introduces an end-to-end autonomous driving model that efficiently fuses multi-modal sensor data and learns task-specific representations to improve driving performance. By addressing key challenges in multi-modal fusion and representation learning, this work advances the state-of-the-art in autonomous driving systems. While there are still limitations to address, EfficientFuser demonstrates the potential of such integrated, learning-based approaches to enhance the safety and capabilities of self-driving vehicles.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient Fusion and Task Guided Embedding for End-to-end Autonomous Driving
Yipin Guo, Yilin Lang, Qinyuan Ren
To address the challenges of sensor fusion and safety risk prediction, contemporary closed-loop autonomous driving neural networks leveraging imitation learning typically require a substantial volume of parameters and computational resources to run neural networks. Given the constrained computational capacities of onboard vehicular computers, we introduce a compact yet potent solution named EfficientFuser. This approach employs EfficientViT for visual information extraction and integrates feature maps via cross attention. Subsequently, it utilizes a decoder-only transformer for the amalgamation of multiple features. For prediction purposes, learnable vectors are embedded as tokens to probe the association between the task and sensor features through attention. Evaluated on the CARLA simulation platform, EfficientFuser demonstrates remarkable efficiency, utilizing merely 37.6% of the parameters and 8.7% of the computations compared to the state-of-the-art lightweight method with only 0.4% lower driving score, and the safety score neared that of the leading safety-enhanced method, showcasing its efficacy and potential for practical deployment in autonomous driving systems.
Read more7/18/2024
0
MaskFuser: Masked Fusion of Joint Multi-Modal Tokenization for End-to-End Autonomous Driving
Yiqun Duan, Xianda Guo, Zheng Zhu, Zhen Wang, Yu-Kai Wang, Chin-Teng Lin
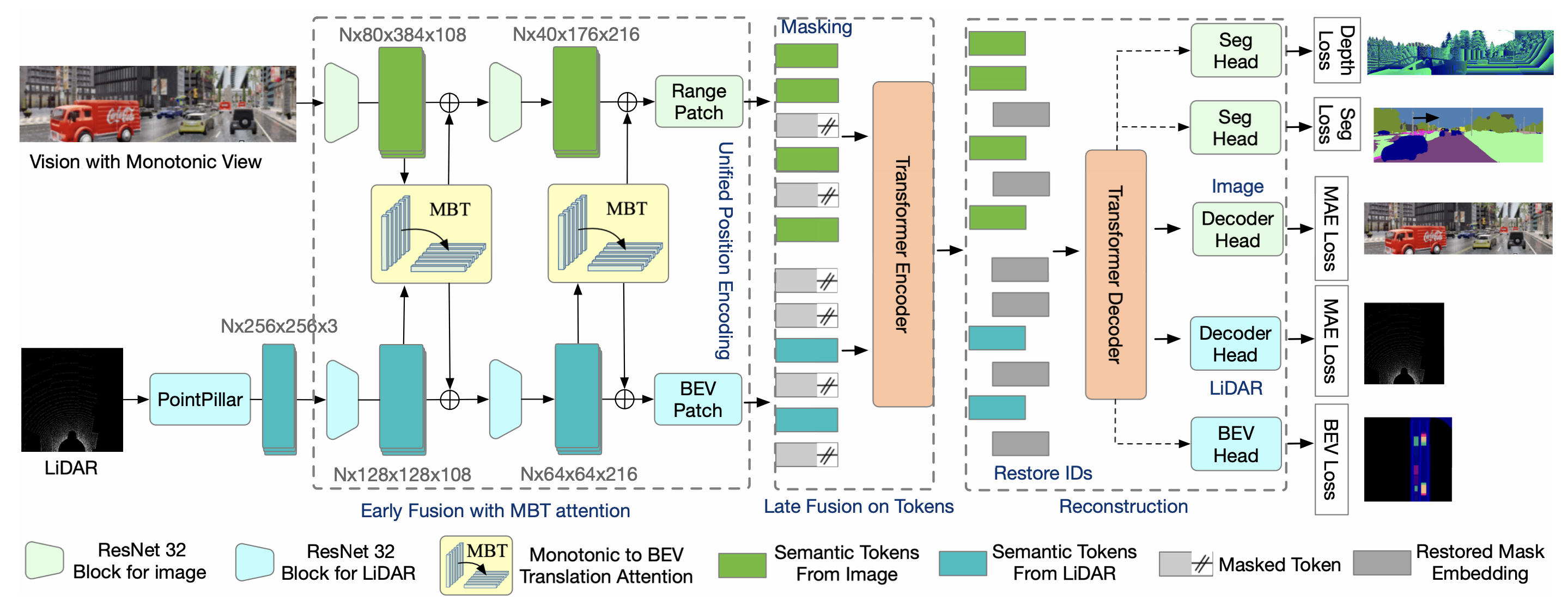
Current multi-modality driving frameworks normally fuse representation by utilizing attention between single-modality branches. However, the existing networks still suppress the driving performance as the Image and LiDAR branches are independent and lack a unified observation representation. Thus, this paper proposes MaskFuser, which tokenizes various modalities into a unified semantic feature space and provides a joint representation for further behavior cloning in driving contexts. Given the unified token representation, MaskFuser is the first work to introduce cross-modality masked auto-encoder training. The masked training enhances the fusion representation by reconstruction on masked tokens. Architecturally, a hybrid-fusion network is proposed to combine advantages from both early and late fusion: For the early fusion stage, modalities are fused by performing monotonic-to-BEV translation attention between branches; Late fusion is performed by tokenizing various modalities into a unified token space with shared encoding on it. MaskFuser respectively reaches a driving score of 49.05 and route completion of 92.85% on the CARLA LongSet6 benchmark evaluation, which improves the best of previous baselines by 1.74 and 3.21%. The introduced masked fusion increases driving stability under damaged sensory inputs. MaskFuser outperforms the best of previous baselines on driving score by 6.55 (27.8%), 1.53 (13.8%), 1.57 (30.9%), respectively given sensory masking ratios 25%, 50%, and 75%.
Read more5/14/2024
🤖
0
Enhance Planning with Physics-informed Safety Controllor for End-to-end Autonomous Driving
Hang Zhou, Haichao Liu, Hongliang Lu, Dan Xu, Jun Ma, Yiding Ji
Recent years have seen a growing research interest in applications of Deep Neural Networks (DNN) on autonomous vehicle technology. The trend started with perception and prediction a few years ago and it is gradually being applied to motion planning tasks. Despite the performance of networks improve over time, DNN planners inherit the natural drawbacks of Deep Learning. Learning-based planners have limitations in achieving perfect accuracy on the training dataset and network performance can be affected by out-of-distribution problem. In this paper, we propose FusionAssurance, a novel trajectory-based end-to-end driving fusion framework which combines physics-informed control for safety assurance. By incorporating Potential Field into Model Predictive Control, FusionAssurance is capable of navigating through scenarios that are not included in the training dataset and scenarios where neural network fail to generalize. The effectiveness of the approach is demonstrated by extensive experiments under various scenarios on the CARLA benchmark.
Read more5/7/2024

0
Guiding Attention in End-to-End Driving Models
Diego Porres, Yi Xiao, Gabriel Villalonga, Alexandre Levy, Antonio M. L'opez
Vision-based end-to-end driving models trained by imitation learning can lead to affordable solutions for autonomous driving. However, training these well-performing models usually requires a huge amount of data, while still lacking explicit and intuitive activation maps to reveal the inner workings of these models while driving. In this paper, we study how to guide the attention of these models to improve their driving quality and obtain more intuitive activation maps by adding a loss term during training using salient semantic maps. In contrast to previous work, our method does not require these salient semantic maps to be available during testing time, as well as removing the need to modify the model's architecture to which it is applied. We perform tests using perfect and noisy salient semantic maps with encouraging results in both, the latter of which is inspired by possible errors encountered with real data. Using CIL++ as a representative state-of-the-art model and the CARLA simulator with its standard benchmarks, we conduct experiments that show the effectiveness of our method in training better autonomous driving models, especially when data and computational resources are scarce.
Read more5/2/2024