Enhancing Fault Detection for Large Language Models via Mutation-Based Confidence Smoothing
2404.14419
0
0
Abstract
Large language models (LLMs) achieved great success in multiple application domains and attracted huge attention from different research communities recently. Unfortunately, even for the best LLM, there still exist many faults that LLM cannot correctly predict. Such faults will harm the usability of LLMs. How to quickly reveal them in LLMs is important, but challenging. The reasons are twofold, 1) the heavy labeling effort for preparing the test data, and 2) accessing closed-source LLMs such as GPT4 is money-required. To handle this problem, in the traditional deep learning testing field, test selection methods have been proposed for efficiently testing deep learning models by prioritizing faults. However, the usefulness of these methods on LLMs is unclear and under exploration. In this paper, we first study the effectiveness of existing fault detection methods for LLMs. Experimental results on four different tasks~(including both code tasks and natural language processing tasks) and four LLMs (e.g., LLaMA and GPT4) demonstrated that existing fault detection methods cannot perform well on LLMs (e.g., seven out of eight methods perform worse than random selection on LLaMA). To enhance existing fault detection methods, we propose MuCS, a prompt Mutation-based prediction Confidence Smoothing method for LLMs. Concretely, we mutate the prompts and compute the average prediction confidence of all mutants as the input of fault detection methods. The results show that our proposed solution significantly enhances existing methods with the improvement of test relative coverage by up to 97.64%.
Create account to get full access
Overview
- Explores a method called "mutation-based confidence smoothing" to improve fault detection in large language models (LLMs)
- Aims to identify and address issues where LLMs may produce unreliable or incorrect outputs
- Proposes a technique that generates multiple slightly modified versions of an input, allowing the model to assess its own confidence in the response
Plain English Explanation
Large language models (LLMs) like GPT-3 have become incredibly powerful at generating human-like text, but they can sometimes produce outputs that are unreliable or incorrect. This paper explores a technique called "mutation-based confidence smoothing" to help LLMs better detect when they might be making mistakes.
The key idea is to generate several slightly modified versions of the original input, and then have the model assess its confidence in the responses to each of those variants. By looking at how the model's confidence changes across the different inputs, the researchers can get a better sense of when the model is uncertain or likely to be incorrect.
This approach builds on prior work on error detection in deep neural networks and using uncertainty to guide large language models. The goal is to give LLMs a better understanding of the reliability of their own outputs, which could be especially helpful in safety-critical applications.
Technical Explanation
The paper proposes a "mutation-based confidence smoothing" approach to enhance fault detection for large language models. The core idea is to generate multiple slightly modified versions of an input, and then have the model assess its confidence in the responses to each of those variants.
Specifically, the researchers take an input text and apply a series of small "mutations" to it, such as replacing or reordering words. They then feed each of these mutated inputs into the LLM and record the model's confidence score for the generated output.
By analyzing how the model's confidence changes across the different mutated inputs, the researchers can identify cases where the model is highly uncertain or likely to be producing an unreliable response. This builds on prior work on detecting errors in LLM outputs and using model uncertainty to guide language model behavior.
The paper evaluates this approach on several benchmark datasets, showing that it can significantly improve the model's ability to detect its own mistakes compared to standard confidence thresholding approaches. This technique could be particularly valuable for safety-critical applications of large language models, where reliable fault detection is crucial.
Critical Analysis
The paper presents a novel and promising approach to enhancing fault detection in large language models. The mutation-based confidence smoothing technique seems well-grounded in prior research on uncertainty estimation and error detection in deep neural networks.
However, the paper does not extensively discuss the potential limitations or drawbacks of this approach. For example, it's unclear how the technique would scale to very large language models or how robust it would be to more sophisticated adversarial attacks that go beyond simple word replacements or reorderings.
Additionally, the paper does not explore how this confidence smoothing approach might interact with other techniques for improving LLM reliability, such as post-editing or confidence expression enhancement. Combining multiple complementary approaches could lead to even stronger fault detection capabilities.
Overall, this paper makes a valuable contribution to the growing body of research on ensuring the reliability and safety of large language models. But further work is needed to fully understand the limitations and potential of this mutation-based confidence smoothing technique.
Conclusion
This paper introduces a novel "mutation-based confidence smoothing" approach to enhance fault detection in large language models. By generating slightly modified versions of an input and analyzing the model's confidence in the responses, the technique can identify cases where the model is likely to produce unreliable or incorrect outputs.
The proposed method builds on prior research in areas like error detection in deep neural networks and using uncertainty to guide large language models. If further developed and combined with other reliability-enhancing techniques, this confidence smoothing approach could play an important role in making large language models more robust and trustworthy, especially for safety-critical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Efficient Detection of LLM-generated Texts with a Bayesian Surrogate Model
Yibo Miao, Hongcheng Gao, Hao Zhang, Zhijie Deng
0
0
The detection of machine-generated text, especially from large language models (LLMs), is crucial in preventing serious social problems resulting from their misuse. Some methods train dedicated detectors on specific datasets but fall short in generalizing to unseen test data, while other zero-shot ones often yield suboptimal performance. Although the recent DetectGPT has shown promising detection performance, it suffers from significant inefficiency issues, as detecting a single candidate requires querying the source LLM with hundreds of its perturbations. This paper aims to bridge this gap. Concretely, we propose to incorporate a Bayesian surrogate model, which allows us to select typical samples based on Bayesian uncertainty and interpolate scores from typical samples to other samples, to improve query efficiency. Empirical results demonstrate that our method significantly outperforms existing approaches under a low query budget. Notably, when detecting the text generated by LLaMA family models, our method with just 2 or 3 queries can outperform DetectGPT with 200 queries.
6/5/2024
AutoDetect: Towards a Unified Framework for Automated Weakness Detection in Large Language Models
Jiale Cheng, Yida Lu, Xiaotao Gu, Pei Ke, Xiao Liu, Yuxiao Dong, Hongning Wang, Jie Tang, Minlie Huang
0
0
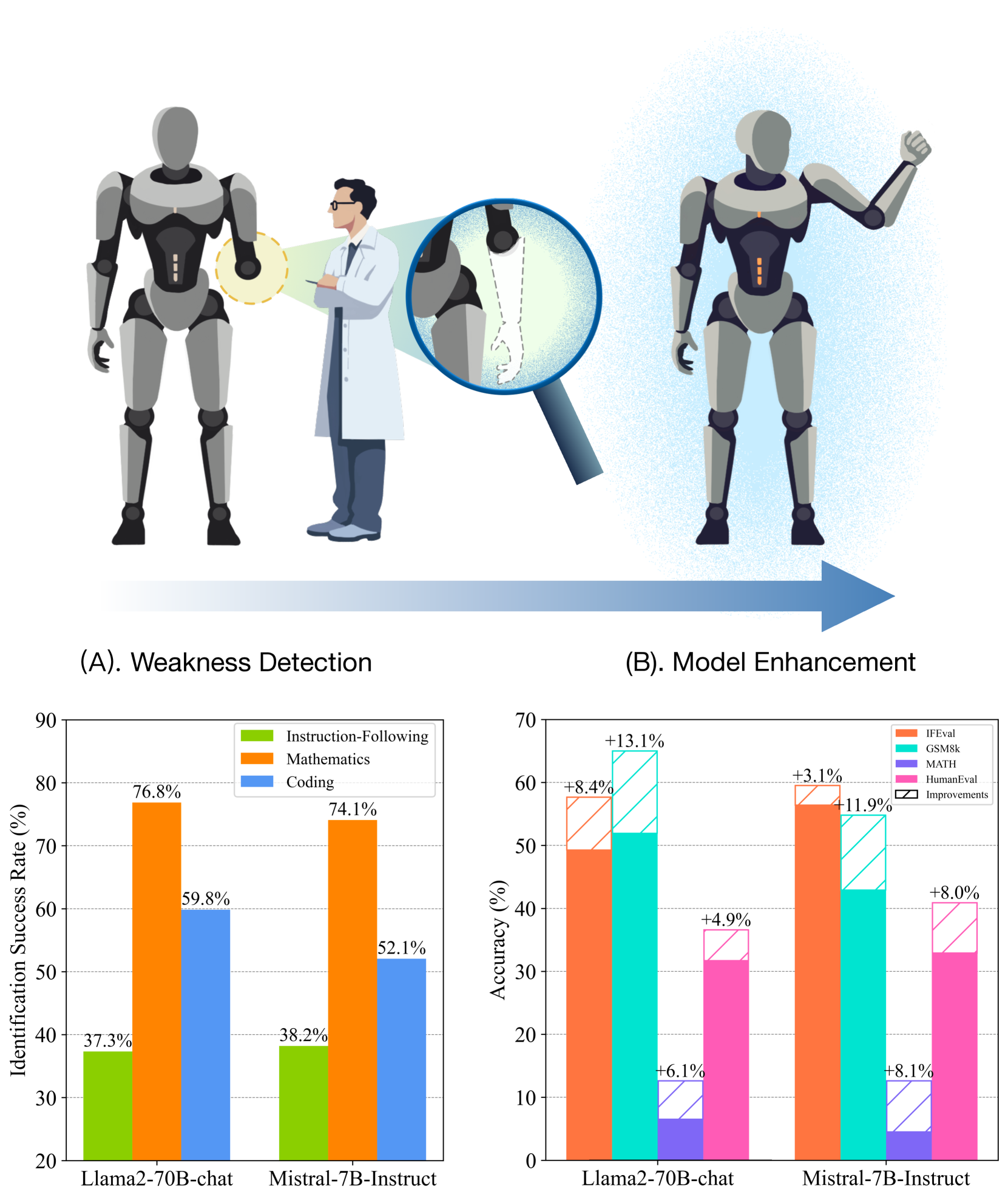
Although Large Language Models (LLMs) are becoming increasingly powerful, they still exhibit significant but subtle weaknesses, such as mistakes in instruction-following or coding tasks. As these unexpected errors could lead to severe consequences in practical deployments, it is crucial to investigate the limitations within LLMs systematically. Traditional benchmarking approaches cannot thoroughly pinpoint specific model deficiencies, while manual inspections are costly and not scalable. In this paper, we introduce a unified framework, AutoDetect, to automatically expose weaknesses in LLMs across various tasks. Inspired by the educational assessment process that measures students' learning outcomes, AutoDetect consists of three LLM-powered agents: Examiner, Questioner, and Assessor. The collaboration among these three agents is designed to realize comprehensive and in-depth weakness identification. Our framework demonstrates significant success in uncovering flaws, with an identification success rate exceeding 30% in prominent models such as ChatGPT and Claude. More importantly, these identified weaknesses can guide specific model improvements, proving more effective than untargeted data augmentation methods like Self-Instruct. Our approach has led to substantial enhancements in popular LLMs, including the Llama series and Mistral-7b, boosting their performance by over 10% across several benchmarks. Code and data are publicly available at https://github.com/thu-coai/AutoDetect.
6/26/2024

Evaluating LLMs at Detecting Errors in LLM Responses
Ryo Kamoi, Sarkar Snigdha Sarathi Das, Renze Lou, Jihyun Janice Ahn, Yilun Zhao, Xiaoxin Lu, Nan Zhang, Yusen Zhang, Ranran Haoran Zhang, Sujeeth Reddy Vummanthala, Salika Dave, Shaobo Qin, Arman Cohan, Wenpeng Yin, Rui Zhang
0
0
With Large Language Models (LLMs) being widely used across various tasks, detecting errors in their responses is increasingly crucial. However, little research has been conducted on error detection of LLM responses. Collecting error annotations on LLM responses is challenging due to the subjective nature of many NLP tasks, and thus previous research focuses on tasks of little practical value (e.g., word sorting) or limited error types (e.g., faithfulness in summarization). This work introduces ReaLMistake, the first error detection benchmark consisting of objective, realistic, and diverse errors made by LLMs. ReaLMistake contains three challenging and meaningful tasks that introduce objectively assessable errors in four categories (reasoning correctness, instruction-following, context-faithfulness, and parameterized knowledge), eliciting naturally observed and diverse errors in responses of GPT-4 and Llama 2 70B annotated by experts. We use ReaLMistake to evaluate error detectors based on 12 LLMs. Our findings show: 1) Top LLMs like GPT-4 and Claude 3 detect errors made by LLMs at very low recall, and all LLM-based error detectors perform much worse than humans. 2) Explanations by LLM-based error detectors lack reliability. 3) LLMs-based error detection is sensitive to small changes in prompts but remains challenging to improve. 4) Popular approaches to improving LLMs, including self-consistency and majority vote, do not improve the error detection performance. Our benchmark and code are provided at https://github.com/psunlpgroup/ReaLMistake.
4/5/2024
A Comprehensive Study of Multilingual Confidence Estimation on Large Language Models
Boyang Xue, Hongru Wang, Rui Wang, Sheng Wang, Zezhong Wang, Yiming Du, Kam-Fai Wong
0
0
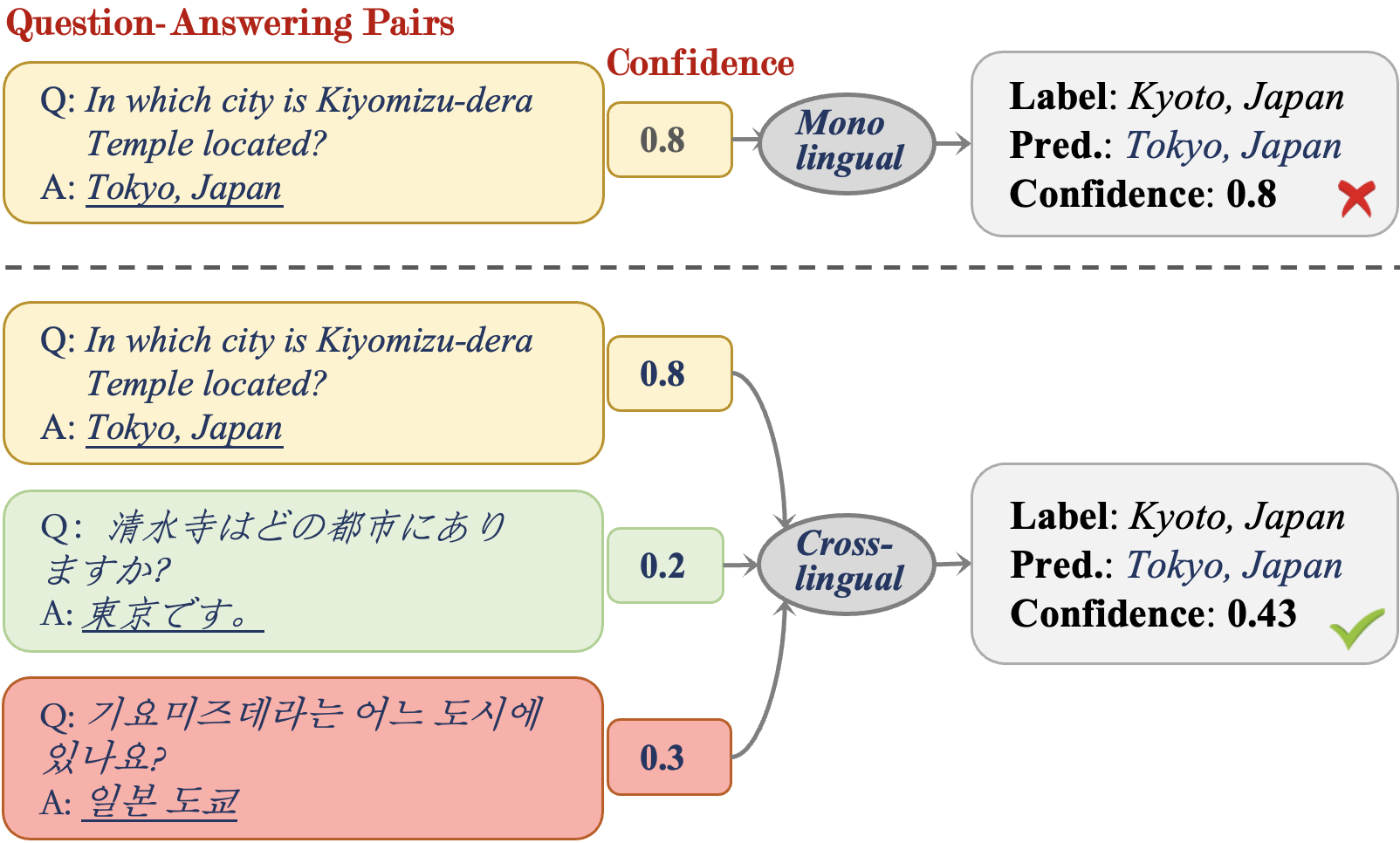
The tendency of Large Language Models (LLMs) to generate hallucinations and exhibit overconfidence in predictions raises concerns regarding their reliability. Confidence or uncertainty estimations indicating the extent of trustworthiness of a model's response are essential to developing reliable AI systems. Current research primarily focuses on LLM confidence estimations in English, remaining a void for other widely used languages and impeding the global development of reliable AI applications. This paper introduces a comprehensive investigation of textbf Multitextbf{ling}ual textbf{Conf}idence estimation (textsc{MlingConf}) on LLMs. First, we introduce an elaborated and expert-checked multilingual QA dataset. Subsequently, we delve into the performance of several confidence estimation methods across diverse languages and examine how these confidence scores can enhance LLM performance through self-refinement. Extensive experiments conducted on the multilingual QA dataset demonstrate that confidence estimation results vary in different languages, and the verbalized numerical confidence estimation method exhibits the best performance among most languages over other methods. Finally, the obtained confidence scores can consistently improve performance as self-refinement feedback across various languages.
6/18/2024