What Happens When Small Is Made Smaller? Exploring the Impact of Compression on Small Data Pretrained Language Models
2404.04759
0
0
Abstract
Compression techniques have been crucial in advancing machine learning by enabling efficient training and deployment of large-scale language models. However, these techniques have received limited attention in the context of low-resource language models, which are trained on even smaller amounts of data and under computational constraints, a scenario known as the low-resource double-bind. This paper investigates the effectiveness of pruning, knowledge distillation, and quantization on an exclusively low-resourced, small-data language model, AfriBERTa. Through a battery of experiments, we assess the effects of compression on performance across several metrics beyond accuracy. Our study provides evidence that compression techniques significantly improve the efficiency and effectiveness of small-data language models, confirming that the prevailing beliefs regarding the effects of compression on large, heavily parameterized models hold true for less-parameterized, small-data models.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the impact of compression on small data pretrained language models (PLMs).
- The researchers investigate how reducing the size of small PLMs affects their performance and capabilities.
- They compare the performance of compressed and uncompressed versions of small PLMs on a range of tasks.
- The findings provide insights into the trade-offs between model size and performance for small-scale language models.
Plain English Explanation
Language models are AI systems trained on large amounts of text data to understand and generate human-like language. These models can be very powerful, but they often require a lot of data and computing power to train.
The paper linked here explores what happens when you take a small language model and make it even smaller through a process called compression. Compression can reduce the size of a model, making it more efficient to run, but it may also impact the model's performance on different tasks.
The researchers in this study took several small language models and compressed them in different ways. They then tested the compressed and uncompressed versions of the models on a variety of language tasks, like answering questions or summarizing text. By comparing the performance of the compressed and uncompressed models, they were able to understand the trade-offs between model size and capability.
This related work on compressing large language models provides helpful context for understanding the challenges and approaches explored in this paper.
The findings from this research can help guide the development of efficient, small-scale language models that can be deployed on devices with limited resources, such as smartphones or embedded systems. Lessons from model compression in practice can also inform how these techniques are applied in real-world scenarios.
Technical Explanation
The paper investigates the impact of model compression on the performance of small data pretrained language models (PLMs). The researchers compared the performance of compressed and uncompressed versions of several small PLMs across a range of downstream tasks.
The researchers used two compression techniques: weight pruning and quantization. Weight pruning involves removing less important parameters from the model, while quantization reduces the precision of the model's parameters, effectively making the model smaller.
The team evaluated the compressed and uncompressed models on a variety of natural language processing tasks, including text classification, question answering, and text generation. They measured metrics like accuracy, F1 score, and perplexity to assess the models' performance.
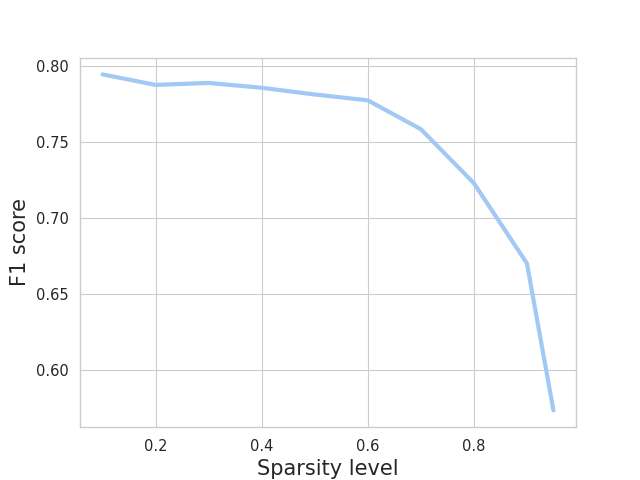
The results showed that compression can significantly reduce the size of small PLMs without drastically impacting their performance on many tasks. However, the researchers also found that compression can negatively affect the models' capabilities in certain specialized areas, such as few-shot learning and open-ended text generation.
This work on training large language models over neurally compressed text provides relevant insights into the challenges and trade-offs involved in compressing language models.
The paper's findings suggest that carefully applied compression techniques can be a useful tool for deploying small, efficient language models in resource-constrained environments, while emerging abilities of reduced-scale generative language models may offer promising avenues for further research and development.
Critical Analysis
The paper provides a thorough investigation of the impact of model compression on the performance of small data pretrained language models. The researchers' use of two distinct compression techniques, weight pruning and quantization, allows for a more nuanced understanding of how different compression approaches affect model capabilities.
One potential limitation of the study is the relatively narrow set of downstream tasks used to evaluate the models. While the researchers covered a range of common NLP tasks, there may be other specialized or domain-specific applications where the impact of compression could be more pronounced.
Additionally, the paper does not delve into the potential implications of compressed models for real-world deployment, such as power consumption, inference latency, or memory footprint. Lessons from model compression in practice could provide valuable insights in this area.
The researchers acknowledge that their findings may not extend to larger language models, as the dynamics of compression and performance trade-offs may differ at greater scales. Further research is needed to understand how these techniques scale and adapt to more complex, high-capacity models.
Overall, the paper provides a valuable contribution to the understanding of model compression for small-scale language models. The insights gained can inform the development of efficient, resource-constrained AI systems, while also highlighting areas for further exploration in the field of language model compression and optimization.
Conclusion
This paper presents a comprehensive study on the impact of model compression on the performance of small data pretrained language models. The researchers' use of two distinct compression techniques, weight pruning and quantization, allowed them to explore the trade-offs between model size and capabilities in depth.
The findings suggest that carefully applied compression can significantly reduce the size of small PLMs without drastically impacting their performance on a range of common NLP tasks. However, the researchers also identified areas, such as few-shot learning and open-ended text generation, where compression can negatively affect the models' specialized capabilities.
These insights can inform the development of efficient, resource-constrained language models that can be deployed in a variety of real-world applications, from mobile devices to edge computing systems. The work also highlights the need for further research to understand how compression techniques scale and adapt to more complex, high-capacity language models.
By providing a nuanced perspective on the trade-offs between model size and performance, this paper contributes to the ongoing efforts to push the boundaries of what is possible with small-scale, energy-efficient AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
On the Compressibility of Quantized Large Language Models
Yu Mao, Weilan Wang, Hongchao Du, Nan Guan, Chun Jason Xue
0
0
Deploying Large Language Models (LLMs) on edge or mobile devices offers significant benefits, such as enhanced data privacy and real-time processing capabilities. However, it also faces critical challenges due to the substantial memory requirement of LLMs. Quantization is an effective way of reducing the model size while maintaining good performance. However, even after quantization, LLMs may still be too big to fit entirely into the limited memory of edge or mobile devices and have to be partially loaded from the storage to complete the inference. In this case, the I/O latency of model loading becomes the bottleneck of the LLM inference latency. In this work, we take a preliminary step of studying applying data compression techniques to reduce data movement and thus speed up the inference of quantized LLM on memory-constrained devices. In particular, we discussed the compressibility of quantized LLMs, the trade-off between the compressibility and performance of quantized LLMs, and opportunities to optimize both of them jointly.
5/7/2024
💬
CompactifAI: Extreme Compression of Large Language Models using Quantum-Inspired Tensor Networks
Andrei Tomut, Saeed S. Jahromi, Abhijoy Sarkar, Uygar Kurt, Sukhbinder Singh, Faysal Ishtiaq, Cesar Mu~noz, Prabdeep Singh Bajaj, Ali Elborady, Gianni del Bimbo, Mehrazin Alizadeh, David Montero, Pablo Martin-Ramiro, Muhammad Ibrahim, Oussama Tahiri Alaoui, John Malcolm, Samuel Mugel, Roman Orus
0
0
Large Language Models (LLMs) such as ChatGPT and LlaMA are advancing rapidly in generative Artificial Intelligence (AI), but their immense size poses significant challenges, such as huge training and inference costs, substantial energy demands, and limitations for on-site deployment. Traditional compression methods such as pruning, distillation, and low-rank approximation focus on reducing the effective number of neurons in the network, while quantization focuses on reducing the numerical precision of individual weights to reduce the model size while keeping the number of neurons fixed. While these compression methods have been relatively successful in practice, there is no compelling reason to believe that truncating the number of neurons is an optimal strategy. In this context, this paper introduces CompactifAI, an innovative LLM compression approach using quantum-inspired Tensor Networks that focuses on the model's correlation space instead, allowing for a more controlled, refined and interpretable model compression. Our method is versatile and can be implemented with - or on top of - other compression techniques. As a benchmark, we demonstrate that a combination of CompactifAI with quantization allows to reduce a 93% the memory size of LlaMA 7B, reducing also 70% the number of parameters, accelerating 50% the training and 25% the inference times of the model, and just with a small accuracy drop of 2% - 3%, going much beyond of what is achievable today by other compression techniques. Our methods also allow to perform a refined layer sensitivity profiling, showing that deeper layers tend to be more suitable for tensor network compression, which is compatible with recent observations on the ineffectiveness of those layers for LLM performance. Our results imply that standard LLMs are, in fact, heavily overparametrized, and do not need to be large at all.
5/14/2024
🤯
Enhancing Inference Efficiency of Large Language Models: Investigating Optimization Strategies and Architectural Innovations
Georgy Tyukin
0
0
Large Language Models are growing in size, and we expect them to continue to do so, as larger models train quicker. However, this increase in size will severely impact inference costs. Therefore model compression is important, to retain the performance of larger models, but with a reduced cost of running them. In this thesis we explore the methods of model compression, and we empirically demonstrate that the simple method of skipping latter attention sublayers in Transformer LLMs is an effective method of model compression, as these layers prove to be redundant, whilst also being incredibly computationally expensive. We observed a 21% speed increase in one-token generation for Llama 2 7B, whilst surprisingly and unexpectedly improving performance over several common benchmarks.
4/10/2024
When Quantization Affects Confidence of Large Language Models?
Irina Proskurina, Luc Brun, Guillaume Metzler, Julien Velcin
0
0
Recent studies introduced effective compression techniques for Large Language Models (LLMs) via post-training quantization or low-bit weight representation. Although quantized weights offer storage efficiency and allow for faster inference, existing works have indicated that quantization might compromise performance and exacerbate biases in LLMs. This study investigates the confidence and calibration of quantized models, considering factors such as language model type and scale as contributors to quantization loss. Firstly, we reveal that quantization with GPTQ to 4-bit results in a decrease in confidence regarding true labels, with varying impacts observed among different language models. Secondly, we observe fluctuations in the impact on confidence across different scales. Finally, we propose an explanation for quantization loss based on confidence levels, indicating that quantization disproportionately affects samples where the full model exhibited low confidence levels in the first place.
5/2/2024