Eureka: Human-Level Reward Design via Coding Large Language Models

1
💬
Sign in to get full access
Overview
- Large Language Models (LLMs) have shown impressive capabilities in high-level decision-making, but applying them to complex low-level tasks like dexterous pen spinning remains a challenge.
- The paper introduces Eureka, a human-level reward design algorithm powered by LLMs that can generate effective reward functions for reinforcement learning (RL) without task-specific prompting.
- Eureka outperforms human experts on 83% of tasks across 29 RL environments, leading to an average 52% improvement.
- Eureka enables a new gradient-free in-context learning approach for Reinforcement Learning from Human Feedback (RLHF) and allows for curriculum learning of complex skills like simulated pen spinning.
Plain English Explanation
The paper discusses how large language models have become very good at high-level decision-making, but still struggle with learning low-level physical skills like spinning a pen. To address this, the researchers developed a system called Eureka that uses the impressive text generation, code-writing, and learning capabilities of LLMs to automatically design reward functions for reinforcement learning.
Without any specific instructions or pre-defined reward templates, Eureka is able to generate reward functions that outperform reward functions carefully crafted by human experts. Eureka was tested on a diverse set of 29 robotics simulation environments, and it outperformed the human-designed rewards in over 80% of the tasks, leading to an average 52% improvement in performance.
This general approach of using LLMs to design rewards also enables a new way of learning from human feedback, where the human can provide input to improve the quality and safety of the generated rewards without having to update the underlying model. Finally, by using the Eureka-generated rewards in a step-by-step curriculum, the researchers were able to train a simulated robotic hand to perform complex pen spinning tricks, demonstrating the power of this technique for learning dexterous physical skills.
Technical Explanation
The key insight behind Eureka is to leverage the remarkable zero-shot generation, code-writing, and in-context improvement capabilities of state-of-the-art LLMs like GPT-4 to perform evolutionary optimization over reward code. Rather than manually designing reward functions, Eureka automatically generates and iteratively refines reward functions through an evolutionary process.
The researchers tested Eureka across 29 diverse RL environments, including 10 distinct robot morphologies. Without any task-specific prompting or pre-defined reward templates, Eureka was able to outperform human-engineered rewards on 83% of the tasks, leading to an average 52% normalized improvement in performance.
Eureka's generality also enables a new gradient-free in-context learning approach to Reinforcement Learning from Human Feedback (RLHF). This allows human inputs to be readily incorporated to improve the quality and safety of the generated rewards without updating the underlying model.
Finally, the researchers demonstrate Eureka's ability to learn complex physical skills by training a simulated Shadow Hand to perform pen spinning tricks. By using a curriculum learning approach with Eureka-generated rewards, they were able to achieve human-level dexterity in manipulating a pen, a feat that had not been demonstrated before in simulation.
Critical Analysis
The paper presents a compelling approach to addressing the challenge of applying LLMs to complex low-level control tasks. By automating the reward design process, Eureka sidesteps the manual effort and domain-specific expertise required for traditional reward engineering.
However, the paper does not thoroughly explore the limitations of the Eureka approach. For example, it is unclear how Eureka would perform on tasks that require long-term planning or complex reasoning beyond what the LLM can capture in its current in-context learning capabilities. Additionally, the paper does not discuss the computational cost and resource requirements of the evolutionary optimization process, which could be a practical constraint for real-world deployment.
Furthermore, the paper mentions the potential for Eureka to incorporate human feedback to improve the safety and quality of the generated rewards, but does not provide a detailed analysis of the robustness and reliability of this process. It would be valuable to understand the potential failure modes and how they could be mitigated.
Overall, the Eureka approach represents a significant advancement in the field of reward modeling and embodied learning with LLMs. However, further research is needed to fully understand its limitations and develop strategies to address them.
Conclusion
The Eureka system presented in this paper demonstrates the remarkable potential of leveraging large language models to tackle the challenge of learning complex physical skills. By automating the reward design process, Eureka is able to outperform human experts on a diverse range of reinforcement learning tasks, paving the way for more efficient and effective skill acquisition.
The general nature of the Eureka approach also enables new paradigms for learning from human feedback and acquiring dexterous manipulation capabilities, as showcased by the simulated pen spinning demonstrations. As LLMs continue to advance, systems like Eureka may play a crucial role in bridging the gap between high-level reasoning and low-level control, unlocking a wide range of practical applications in robotics and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
1
Eureka: Human-Level Reward Design via Coding Large Language Models
Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, Anima Anandkumar
Large Language Models (LLMs) have excelled as high-level semantic planners for sequential decision-making tasks. However, harnessing them to learn complex low-level manipulation tasks, such as dexterous pen spinning, remains an open problem. We bridge this fundamental gap and present Eureka, a human-level reward design algorithm powered by LLMs. Eureka exploits the remarkable zero-shot generation, code-writing, and in-context improvement capabilities of state-of-the-art LLMs, such as GPT-4, to perform evolutionary optimization over reward code. The resulting rewards can then be used to acquire complex skills via reinforcement learning. Without any task-specific prompting or pre-defined reward templates, Eureka generates reward functions that outperform expert human-engineered rewards. In a diverse suite of 29 open-source RL environments that include 10 distinct robot morphologies, Eureka outperforms human experts on 83% of the tasks, leading to an average normalized improvement of 52%. The generality of Eureka also enables a new gradient-free in-context learning approach to reinforcement learning from human feedback (RLHF), readily incorporating human inputs to improve the quality and the safety of the generated rewards without model updating. Finally, using Eureka rewards in a curriculum learning setting, we demonstrate for the first time, a simulated Shadow Hand capable of performing pen spinning tricks, adeptly manipulating a pen in circles at rapid speed.
Read more5/2/2024

0
DrEureka: Language Model Guided Sim-To-Real Transfer
Yecheng Jason Ma, William Liang, Hung-Ju Wang, Sam Wang, Yuke Zhu, Linxi Fan, Osbert Bastani, Dinesh Jayaraman
Transferring policies learned in simulation to the real world is a promising strategy for acquiring robot skills at scale. However, sim-to-real approaches typically rely on manual design and tuning of the task reward function as well as the simulation physics parameters, rendering the process slow and human-labor intensive. In this paper, we investigate using Large Language Models (LLMs) to automate and accelerate sim-to-real design. Our LLM-guided sim-to-real approach, DrEureka, requires only the physics simulation for the target task and automatically constructs suitable reward functions and domain randomization distributions to support real-world transfer. We first demonstrate that our approach can discover sim-to-real configurations that are competitive with existing human-designed ones on quadruped locomotion and dexterous manipulation tasks. Then, we showcase that our approach is capable of solving novel robot tasks, such as quadruped balancing and walking atop a yoga ball, without iterative manual design.
Read more6/5/2024
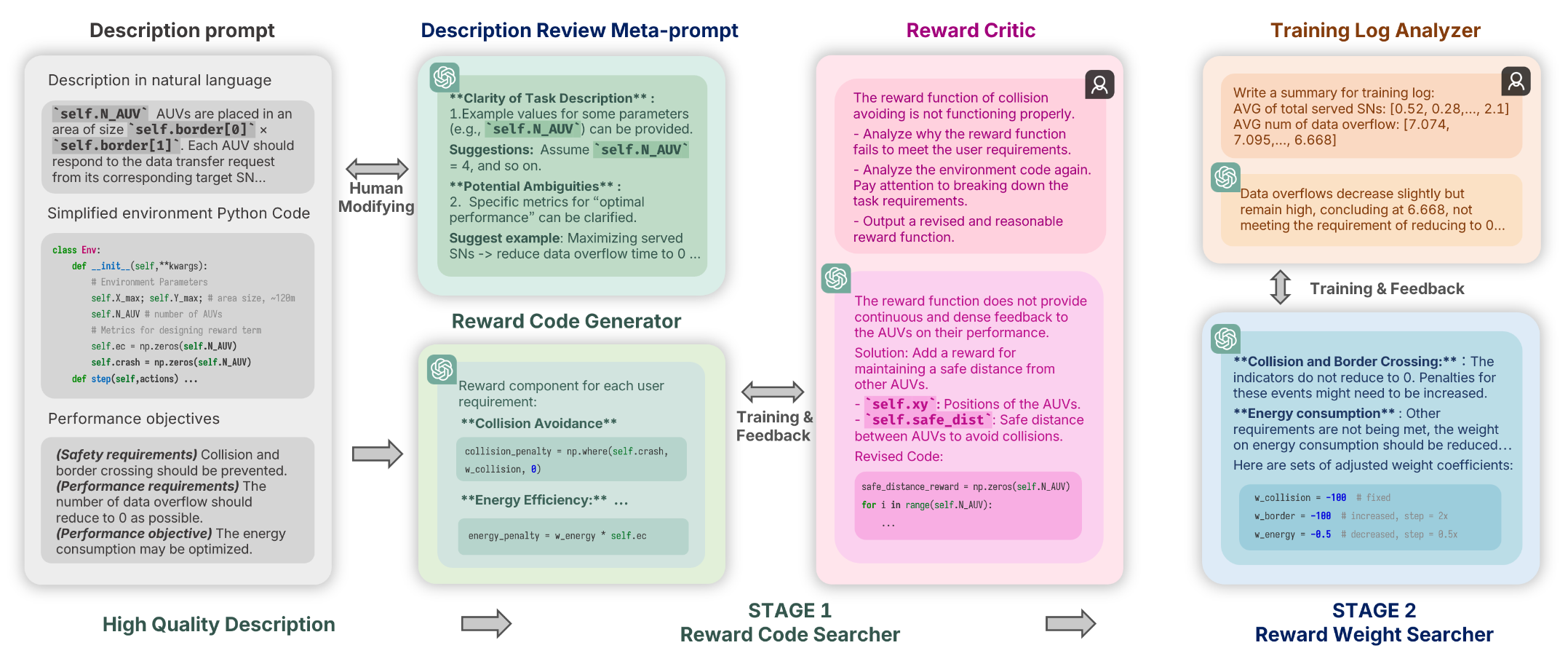
0
Large Language Models as Efficient Reward Function Searchers for Custom-Environment Multi-Objective Reinforcement Learning
Guanwen Xie, Jingzehua Xu, Yiyuan Yang, Shuai Zhang
Leveraging large language models (LLMs) for designing reward functions demonstrates significant potential. However, achieving effective design and improvement of reward functions in reinforcement learning (RL) tasks with complex custom environments and multiple requirements presents considerable challenges. In this paper, we enable LLMs to be effective white-box searchers, highlighting their advanced semantic understanding capabilities. Specifically, we generate reward components for each explicit user requirement and employ the reward critic to identify the correct code form. Then, LLMs assign weights to the reward components to balance their values and iteratively search and optimize these weights based on the context provided by the training log analyzer, while adaptively determining the search step size. We applied the framework to an underwater information collection RL task without direct human feedback or reward examples (zero-shot). The reward critic successfully correct the reward code with only one feedback for each requirement, effectively preventing irreparable errors that can occur when reward function feedback is provided in aggregate. The effective initialization of weights enables the acquisition of different reward functions within the Pareto solution set without weight search. Even in the case where a weight is 100 times off, fewer than four iterations are needed to obtain solutions that meet user requirements. The framework also works well with most prompts utilizing GPT-3.5 Turbo, since it does not require advanced numerical understanding or calculation.
Read more9/5/2024

0
REvolve: Reward Evolution with Large Language Models for Autonomous Driving
Rishi Hazra, Alkis Sygkounas, Andreas Persson, Amy Loutfi, Pedro Zuidberg Dos Martires
Designing effective reward functions is crucial to training reinforcement learning (RL) algorithms. However, this design is non-trivial, even for domain experts, due to the subjective nature of certain tasks that are hard to quantify explicitly. In recent works, large language models (LLMs) have been used for reward generation from natural language task descriptions, leveraging their extensive instruction tuning and commonsense understanding of human behavior. In this work, we hypothesize that LLMs, guided by human feedback, can be used to formulate human-aligned reward functions. Specifically, we study this in the challenging setting of autonomous driving (AD), wherein notions of good driving are tacit and hard to quantify. To this end, we introduce REvolve, an evolutionary framework that uses LLMs for reward design in AD. REvolve creates and refines reward functions by utilizing human feedback to guide the evolution process, effectively translating implicit human knowledge into explicit reward functions for training (deep) RL agents. We demonstrate that agents trained on REvolve-designed rewards align closely with human driving standards, thereby outperforming other state-of-the-art baselines.
Read more6/4/2024