Is Your Model Really A Good Math Reasoner? Evaluating Mathematical Reasoning with Checklist

0

Sign in to get full access
Overview
- Evaluates the mathematical reasoning capabilities of AI models beyond just accuracy
- Introduces a new evaluation framework called MathCheck that assesses different aspects of mathematical reasoning
- Finds that large language models (LLMs) struggle with certain types of mathematical reasoning tasks, despite their strong performance on standard benchmarks
Plain English Explanation
This paper looks at whether AI models that are good at math tests are truly capable of mathematical reasoning, or if they are just good at memorizing and regurgitating information. The researchers developed a new evaluation framework called MathCheck that tests different types of mathematical reasoning, such as logical inference, symbolic manipulation, and word problem solving.
The paper shows that even large language models (LLMs) that perform well on standard math benchmarks struggle with certain types of mathematical reasoning tasks. This suggests that these models may be relying more on memorization and pattern matching than true understanding of mathematical concepts.
The researchers argue that evaluating models' mathematical reasoning abilities, rather than just their test scores, is critical to ensure AI systems can reliably perform complex mathematical tasks. This work builds on other recent efforts to systematically evaluate the logical and reasoning capabilities of AI models.
Technical Explanation
The paper introduces a new evaluation framework called MathCheck that assesses different aspects of mathematical reasoning, including logical inference, symbolic manipulation, and word problem solving. MathCheck includes a diverse set of test problems designed to probe these reasoning capabilities.
The researchers evaluated several state-of-the-art large language models (LLMs) using MathCheck and found that the models struggled with certain types of mathematical reasoning, despite their strong performance on standard math benchmarks. For example, the LLMs had difficulty with tasks that required step-by-step logical deduction or applying symbolic mathematical rules.
These findings suggest that the LLMs may be relying more on pattern matching and memorization than true mathematical understanding. The authors argue that evaluating models' reasoning abilities, rather than just their accuracy, is critical to ensure AI systems can reliably perform complex mathematical tasks.
Critical Analysis
The paper makes a compelling case that evaluating the mathematical reasoning capabilities of AI models is important, and that current approaches focused solely on accuracy may be missing key aspects of intelligent mathematical behavior.
However, the paper does not provide a comprehensive analysis of the underlying reasons for the LLMs' struggles with certain types of mathematical reasoning. It would be helpful to have a deeper exploration of the specific model architectures, training data, and learning algorithms that may contribute to these limitations.
Additionally, the paper does not discuss potential ways to improve the mathematical reasoning abilities of LLMs, such as through more targeted training, the incorporation of symbolic reasoning, or the use of hybrid architectures that combine language models with other mathematical reasoning components.
Overall, this work raises important questions about the true mathematical understanding of state-of-the-art AI models and highlights the need for more rigorous evaluation frameworks that go beyond standard benchmark tests. By encouraging critical thinking and further research in this area, the paper makes a valuable contribution to the ongoing quest to develop AI systems that can reliably and intelligently perform complex mathematical tasks.
Conclusion
This paper presents a new evaluation framework called MathCheck that assesses the mathematical reasoning capabilities of AI models beyond just their accuracy on standard benchmarks. The results show that even large language models (LLMs) that perform well on math tests struggle with certain types of mathematical reasoning, suggesting they may be relying more on memorization than true understanding.
The authors argue that evaluating models' reasoning abilities, rather than just their test scores, is critical to ensure AI systems can reliably perform complex mathematical tasks. This work builds on other recent efforts to systematically evaluate the logical and reasoning capabilities of AI models, and highlights the importance of moving beyond narrow benchmarks to more holistic assessments of mathematical intelligence.
By encouraging critical thinking and further research in this area, the paper makes an important contribution to the ongoing quest to develop AI systems that can truly reason about and engage with the mathematical world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Is Your Model Really A Good Math Reasoner? Evaluating Mathematical Reasoning with Checklist
Zihao Zhou, Shudong Liu, Maizhen Ning, Wei Liu, Jindong Wang, Derek F. Wong, Xiaowei Huang, Qiufeng Wang, Kaizhu Huang
Exceptional mathematical reasoning ability is one of the key features that demonstrate the power of large language models (LLMs). How to comprehensively define and evaluate the mathematical abilities of LLMs, and even reflect the user experience in real-world scenarios, has emerged as a critical issue. Current benchmarks predominantly concentrate on problem-solving capabilities, which presents a substantial risk of model overfitting and fails to accurately represent genuine mathematical reasoning abilities. In this paper, we argue that if a model really understands a problem, it should be robustly and readily applied across a diverse array of tasks. Motivated by this, we introduce MATHCHECK, a well-designed checklist for testing task generalization and reasoning robustness, as well as an automatic tool to generate checklists efficiently. MATHCHECK includes multiple mathematical reasoning tasks and robustness test types to facilitate a comprehensive evaluation of both mathematical reasoning ability and behavior testing. Utilizing MATHCHECK, we develop MATHCHECK-GSM and MATHCHECK-GEO to assess mathematical textual reasoning and multi-modal reasoning capabilities, respectively, serving as upgraded versions of benchmarks including GSM8k, GeoQA, UniGeo, and Geometry3K. We adopt MATHCHECK-GSM and MATHCHECK-GEO to evaluate over 20 LLMs and 11 MLLMs, assessing their comprehensive mathematical reasoning abilities. Our results demonstrate that while frontier LLMs like GPT-4o continue to excel in various abilities on the checklist, many other model families exhibit a significant decline. Further experiments indicate that, compared to traditional math benchmarks, MATHCHECK better reflects true mathematical abilities and represents mathematical intelligence more linearly, thereby supporting our design. On our MATHCHECK, we can easily conduct detailed behavior analysis to deeply investigate models.
Read more7/12/2024

0
Evaluating Mathematical Reasoning Beyond Accuracy
Shijie Xia, Xuefeng Li, Yixin Liu, Tongshuang Wu, Pengfei Liu
The leaderboard of Large Language Models (LLMs) in mathematical tasks has been continuously updated. However, the majority of evaluations focus solely on the final results, neglecting the quality of the intermediate steps. This oversight can mask underlying problems, such as logical errors or unnecessary steps in the reasoning process. To measure reasoning beyond final-answer accuracy, we introduce ReasonEval, a new methodology for evaluating the quality of reasoning steps. ReasonEval employs $textit{validity}$ and $textit{redundancy}$ to characterize the reasoning quality, as well as accompanying LLMs to assess them automatically. Instantiated by base models that possess strong mathematical knowledge and trained with high-quality labeled data, ReasonEval achieves state-of-the-art performance on human-labeled datasets and can accurately detect different types of errors generated by perturbation. When applied to evaluate LLMs specialized in math, we find that an increase in final-answer accuracy does not necessarily guarantee an improvement in the overall quality of the reasoning steps for challenging mathematical problems. Additionally, we observe that ReasonEval can play a significant role in data selection. We release the best-performing model, meta-evaluation script, and all evaluation results at https://github.com/GAIR-NLP/ReasonEval.
Read more4/9/2024

0
Benchmarking Large Language Models for Math Reasoning Tasks
Kathrin Se{ss}ler, Yao Rong, Emek Gozluklu, Enkelejda Kasneci
The use of Large Language Models (LLMs) in mathematical reasoning has become a cornerstone of related research, demonstrating the intelligence of these models and enabling potential practical applications through their advanced performance, such as in educational settings. Despite the variety of datasets and in-context learning algorithms designed to improve the ability of LLMs to automate mathematical problem solving, the lack of comprehensive benchmarking across different datasets makes it complicated to select an appropriate model for specific tasks. In this project, we present a benchmark that fairly compares seven state-of-the-art in-context learning algorithms for mathematical problem solving across five widely used mathematical datasets on four powerful foundation models. Furthermore, we explore the trade-off between efficiency and performance, highlighting the practical applications of LLMs for mathematical reasoning. Our results indicate that larger foundation models like GPT-4o and LLaMA 3-70B can solve mathematical reasoning independently from the concrete prompting strategy, while for smaller models the in-context learning approach significantly influences the performance. Moreover, the optimal prompt depends on the chosen foundation model. We open-source our benchmark code to support the integration of additional models in future research.
Read more8/21/2024
0
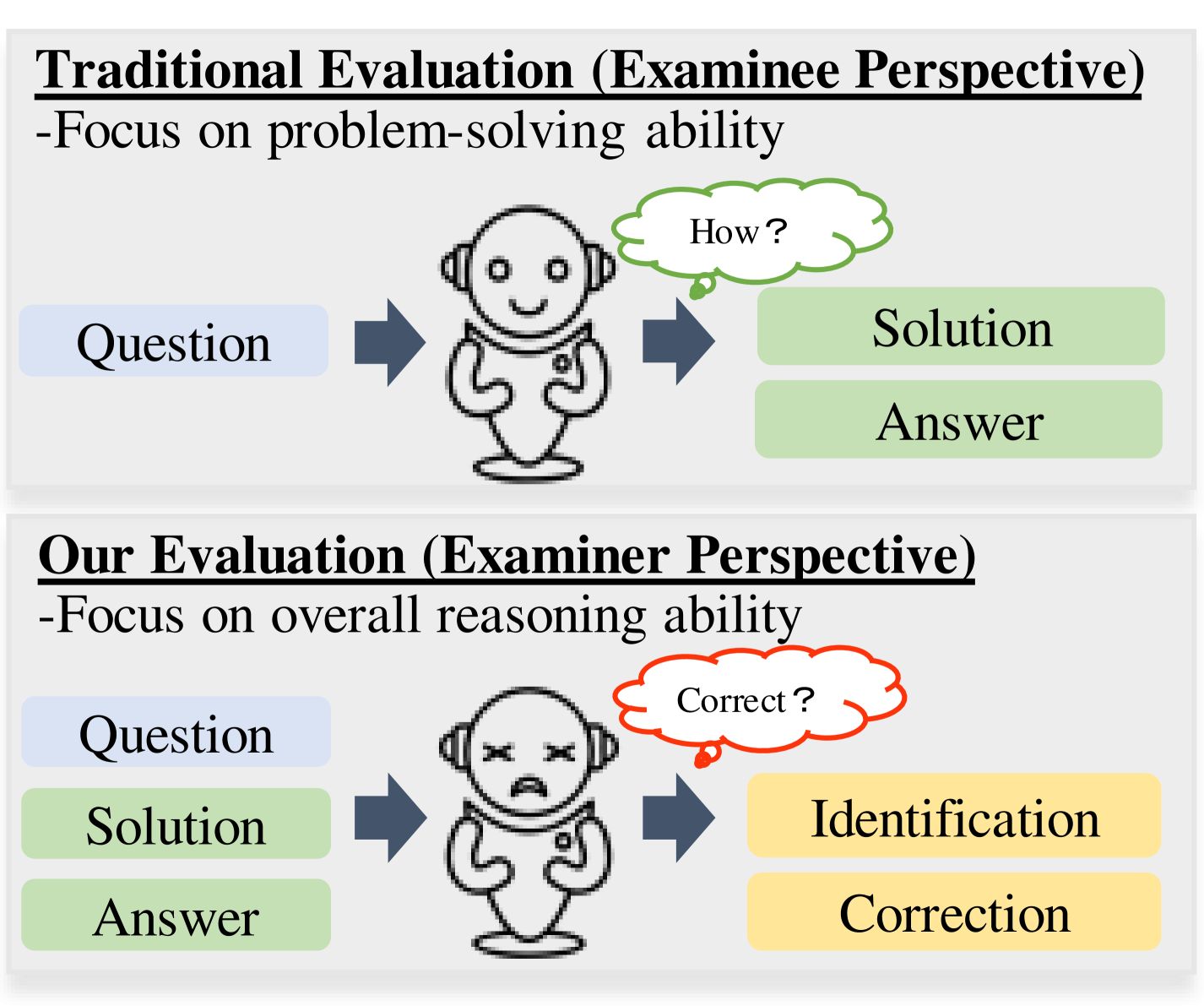
Evaluating Mathematical Reasoning of Large Language Models: A Focus on Error Identification and Correction
Xiaoyuan Li, Wenjie Wang, Moxin Li, Junrong Guo, Yang Zhang, Fuli Feng
The rapid advancement of Large Language Models (LLMs) in the realm of mathematical reasoning necessitates comprehensive evaluations to gauge progress and inspire future directions. Existing assessments predominantly focus on problem-solving from the examinee perspective, overlooking a dual perspective of examiner regarding error identification and correction. From the examiner perspective, we define four evaluation tasks for error identification and correction along with a new dataset with annotated error types and steps. We also design diverse prompts to thoroughly evaluate eleven representative LLMs. Our principal findings indicate that GPT-4 outperforms all models, while open-source model LLaMA-2-7B demonstrates comparable abilities to closed-source models GPT-3.5 and Gemini Pro. Notably, calculation error proves the most challenging error type. Moreover, prompting LLMs with the error types can improve the average correction accuracy by 47.9%. These results reveal potential directions for developing the mathematical reasoning abilities of LLMs. Our code and dataset is available on https://github.com/LittleCirc1e/EIC.
Read more6/4/2024