Exact Conversion of In-Context Learning to Model Weights

0

Sign in to get full access
Overview
- This paper presents a method for converting in-context learning, a technique used in large language models, into explicit model weights.
- In-context learning allows models to rapidly adapt to new tasks by encoding task-specific information within their hidden representations, without actually modifying the model weights.
- The authors show how this in-context learning can be exactly converted into changes to the model's attention and feedforward weights, enabling the model to perform the same task with the modified weights.
- This conversion process allows researchers to better understand how in-context learning works and how it is implemented in the model's architecture.
Plain English Explanation
The paper describes a way to take a language model that has been trained to learn new tasks "on-the-fly" through in-context learning, and convert that learned knowledge into actual changes to the model's internal weights and parameters.
Large language models like GPT-3 have an amazing ability to quickly adapt to new tasks or datasets by encoding relevant information within their internal "hidden" representations, without changing the underlying model itself. This implicit context learning allows the model to perform well on new tasks, but it can be difficult to understand exactly how this adaptation process works.
The key insight from this paper is that the in-context learning process can be "unrolled" and translated into explicit changes to the model's attention and feedforward weights. By doing this conversion, the authors can show precisely how the model is adjusting its internal structure to accommodate new tasks or information. This sheds light on the mechanisms behind context learning in large language models, and how this ability to rapidly adapt may or may not generalize robustly.
Overall, this work provides a valuable tool for analyzing and understanding the inner workings of large language models, particularly when it comes to their impressive ability to learn new tasks and adapt to different contexts.
Technical Explanation
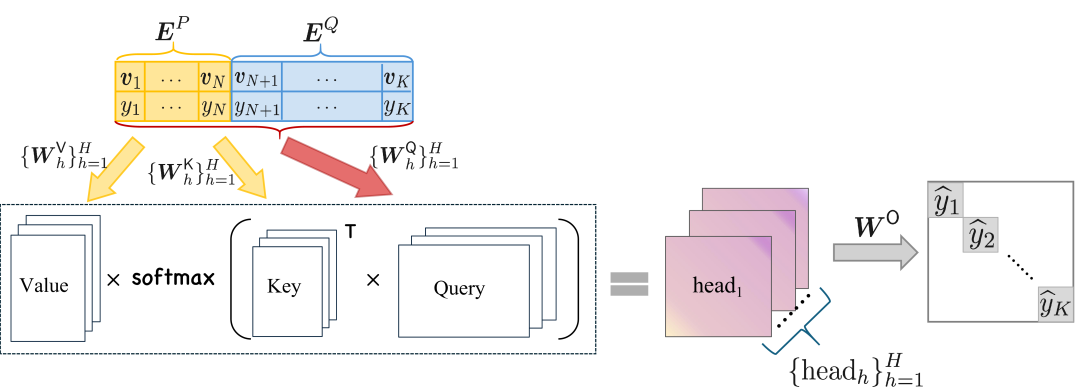
The authors focus on a class of Transformer language models that use linearized attention, where the attention mechanism is computed as a simple matrix-vector multiplication. They show that for these models, the in-context learning process can be exactly converted into updates to the model's attention and feedforward weights.
Specifically, the authors derive mathematically how the in-context learning updates to the hidden representations can be mapped back to changes in the model's parameters. This conversion process involves decomposing the in-context learning updates into an additive decomposition, and then showing how each component corresponds to a specific weight update.
The key steps are:
- Representing the in-context learning updates as an additive decomposition in terms of the model's attention and feedforward weights.
- Showing that each component of this decomposition can be converted into a rank-1 update to the corresponding model weights.
- Combining these rank-1 updates to obtain the full set of weight updates that exactly reproduce the in-context learning behavior.
By performing this conversion, the authors are able to gain insights into how in-context learning is implemented in the model's architecture. They demonstrate the technique on a linearized Transformer model and show that the converted weights can be used to perform the same tasks as the original model.
Critical Analysis
The authors provide a rigorous mathematical analysis that demonstrates the exact conversion from in-context learning to explicit model weight updates. This is a valuable contribution, as it allows researchers to better understand the internal mechanisms behind in-context learning in large language models.
One potential limitation of this work is that it is focused specifically on linearized-attention Transformer models. While these models are an important class, it is not clear if the exact conversion process would extend to other model architectures that do not use linearized attention. The authors acknowledge this, and suggest that exploring extensions to other model types is an important area for future work.
Additionally, the paper does not delve deeply into the practical implications or potential use cases of this conversion process. While it provides key insights into the inner workings of in-context learning, more discussion around how these insights could be leveraged to improve model design, training, or interpretation would strengthen the paper's impact.
Nevertheless, this work represents an important step forward in understanding the Bayesian perspective on context learning in large language models. By bridging the gap between implicit and explicit representations of task-specific knowledge, the authors have opened up new avenues for research and development in this rapidly evolving field.
Conclusion
This paper presents a novel method for converting the in-context learning capabilities of large language models into explicit changes to the model's attention and feedforward weights. By deriving a mathematical framework for this conversion process, the authors provide valuable insights into the inner workings of in-context learning and how it is implemented in the model architecture.
The ability to translate implicit, context-dependent knowledge into explicit model updates is an important step forward in understanding and interpreting the behavior of large language models. This work lays the groundwork for further research into the mechanisms behind rapid task adaptation, and how these capabilities can be better leveraged and controlled for a wide range of applications.
Overall, this paper makes a significant contribution to the growing body of research on in-context learning and context-dependent representations in deep learning. By bridging the gap between implicit and explicit forms of task-specific knowledge, the authors have opened up new possibilities for modeling, interpreting, and improving the capabilities of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exact Conversion of In-Context Learning to Model Weights
Brian K Chen, Tianyang Hu, Hui Jin, Hwee Kuan Lee, Kenji Kawaguchi
In-Context Learning (ICL) has been a powerful emergent property of large language models that has attracted increasing attention in recent years. In contrast to regular gradient-based learning, ICL is highly interpretable and does not require parameter updates. In this paper, we show that, for linearized transformer networks, ICL can be made explicit and permanent through the inclusion of bias terms. We mathematically demonstrate the equivalence between a model with ICL demonstration prompts and the same model with the additional bias terms. Our algorithm (ICLCA) allows for exact conversion in an inexpensive manner. Existing methods are not exact and require expensive parameter updates. We demonstrate the efficacy of our approach through experiments that show the exact incorporation of ICL tokens into a linear transformer. We further suggest how our method can be adapted to achieve cheap approximate conversion of ICL tokens, even in regular transformer networks that are not linearized. Our experiments on GPT-2 show that, even though the conversion is only approximate, the model still gains valuable context from the included bias terms.
Read more6/7/2024
🚀
0
Do pretrained Transformers Learn In-Context by Gradient Descent?
Lingfeng Shen, Aayush Mishra, Daniel Khashabi
The emergence of In-Context Learning (ICL) in LLMs remains a remarkable phenomenon that is partially understood. To explain ICL, recent studies have created theoretical connections to Gradient Descent (GD). We ask, do such connections hold up in actual pre-trained language models? We highlight the limiting assumptions in prior works that make their setup considerably different from the practical setup in which language models are trained. For example, their experimental verification uses emph{ICL objective} (training models explicitly for ICL), which differs from the emergent ICL in the wild. Furthermore, the theoretical hand-constructed weights used in these studies have properties that don't match those of real LLMs. We also look for evidence in real models. We observe that ICL and GD have different sensitivity to the order in which they observe demonstrations. Finally, we probe and compare the ICL vs. GD hypothesis in a natural setting. We conduct comprehensive empirical analyses on language models pre-trained on natural data (LLaMa-7B). Our comparisons of three performance metrics highlight the inconsistent behavior of ICL and GD as a function of various factors such as datasets, models, and the number of demonstrations. We observe that ICL and GD modify the output distribution of language models differently. These results indicate that emph{the equivalence between ICL and GD remains an open hypothesis} and calls for further studies.
Read more6/4/2024
0
In-Context Learning with Representations: Contextual Generalization of Trained Transformers
Tong Yang, Yu Huang, Yingbin Liang, Yuejie Chi
In-context learning (ICL) refers to a remarkable capability of pretrained large language models, which can learn a new task given a few examples during inference. However, theoretical understanding of ICL is largely under-explored, particularly whether transformers can be trained to generalize to unseen examples in a prompt, which will require the model to acquire contextual knowledge of the prompt for generalization. This paper investigates the training dynamics of transformers by gradient descent through the lens of non-linear regression tasks. The contextual generalization here can be attained via learning the template function for each task in-context, where all template functions lie in a linear space with $m$ basis functions. We analyze the training dynamics of one-layer multi-head transformers to in-contextly predict unlabeled inputs given partially labeled prompts, where the labels contain Gaussian noise and the number of examples in each prompt are not sufficient to determine the template. Under mild assumptions, we show that the training loss for a one-layer multi-head transformer converges linearly to a global minimum. Moreover, the transformer effectively learns to perform ridge regression over the basis functions. To our knowledge, this study is the first provable demonstration that transformers can learn contextual (i.e., template) information to generalize to both unseen examples and tasks when prompts contain only a small number of query-answer pairs.
Read more8/21/2024
👨🏫
0
Implicit In-context Learning
Zhuowei Li, Zihao Xu, Ligong Han, Yunhe Gao, Song Wen, Di Liu, Hao Wang, Dimitris N. Metaxas
In-context Learning (ICL) empowers large language models (LLMs) to adapt to unseen tasks during inference by prefixing a few demonstration examples prior to test queries. Despite its versatility, ICL incurs substantial computational and memory overheads compared to zero-shot learning and is susceptible to the selection and order of demonstration examples. In this work, we introduce Implicit In-context Learning (I2CL), an innovative paradigm that addresses the challenges associated with traditional ICL by absorbing demonstration examples within the activation space. I2CL first generates a condensed vector representation, namely a context vector, from the demonstration examples. It then integrates the context vector during inference by injecting a linear combination of the context vector and query activations into the model's residual streams. Empirical evaluation on nine real-world tasks across three model architectures demonstrates that I2CL achieves few-shot performance with zero-shot cost and exhibits robustness against the variation of demonstration examples. Furthermore, I2CL facilitates a novel representation of task-ids, enhancing task similarity detection and enabling effective transfer learning. We provide a comprehensive analysis of I2CL, offering deeper insights into its mechanisms and broader implications for ICL. The source code is available at: https://github.com/LzVv123456/I2CL.
Read more5/24/2024