ExeGPT: Constraint-Aware Resource Scheduling for LLM Inference

0
Sign in to get full access
Overview
- Introduces ExeGPT, a system for constraint-aware resource scheduling of large language model (LLM) inference
- Aims to optimize LLM inference performance by considering various resource constraints and user requirements
- Includes techniques for task prioritization, resource allocation, and execution monitoring
Plain English Explanation
ExeGPT is a new system designed to help manage the use of large language models (LLMs) more effectively. LLMs are powerful AI models that can perform a wide variety of language-related tasks, but running them requires a lot of computing resources like GPUs and memory. ExeGPT tries to optimize how these resources are used to get the best performance out of the LLMs.
The key idea behind ExeGPT is that it takes into account different constraints and requirements when scheduling LLM inference tasks. For example, some tasks might be more urgent or important than others, so ExeGPT will prioritize those. It also tries to allocate computing resources in a way that meets the needs of each task, like making sure there is enough GPU memory available. ExeGPT also monitors the execution of the tasks and can adjust the scheduling on the fly if needed.
By considering all these factors, ExeGPT aims to get more out of the available computing resources and improve the overall performance and efficiency of LLM-based applications. This could be useful for things like chatbots, time series forecasting, or other domains that rely heavily on large language models.
Technical Explanation
ExeGPT is a constraint-aware resource scheduling system for performing inference with large language models (LLMs). It addresses the challenge of optimizing LLM inference performance in the face of various resource constraints and user requirements.
ExeGPT employs several key techniques:
-
Task prioritization: ExeGPT prioritizes inference tasks based on factors like deadline, importance, and resource requirements. This ensures that critical tasks are executed in a timely manner.
-
Resource allocation: ExeGPT dynamically allocates computing resources like GPUs and memory to inference tasks, considering their specific needs. This helps maximize resource utilization and meet the requirements of each task.
-
Execution monitoring: ExeGPT continuously monitors the execution of inference tasks and can reschedule or adjust resource allocation if issues arise, such as a task exceeding its estimated runtime.
The architecture of ExeGPT includes a centralized scheduler that manages the lifecycle of inference tasks, as well as specialized components for task prioritization, resource allocation, and execution monitoring. ExeGPT also incorporates techniques from the fields of resource-constrained scheduling and mathematical reasoning to inform its decision-making.
Through these innovative approaches, ExeGPT aims to improve the overall performance and efficiency of LLM-based applications, particularly in scenarios with strict resource constraints or diverse user requirements.
Critical Analysis
The ExeGPT paper presents a promising approach to optimizing LLM inference, but there are a few potential limitations and areas for further research:
-
Generalization to diverse LLM architectures: The paper focuses on a specific LLM model, GPT-3, and it's unclear how well the proposed techniques would generalize to other LLM architectures, which can have different resource requirements and performance characteristics.
-
Real-world deployment and scalability: The evaluation in the paper is based on simulations and synthetic workloads. Validating the effectiveness of ExeGPT in real-world, large-scale deployment scenarios with diverse user demands would be an important next step.
-
Overhead and latency considerations: The paper does not explicitly address the potential overhead or latency introduced by the ExeGPT scheduling system, which could be a concern for time-sensitive applications like password guessing.
-
Fairness and ethical implications: While the paper focuses on technical optimization, the implications of prioritizing certain inference tasks over others could raise fairness and ethical concerns that merit further investigation.
Overall, the ExeGPT system presents an interesting and promising approach to managing the resource challenges of LLM inference. Addressing the above limitations and further validating the system's performance and scalability would be valuable areas for future research.
Conclusion
The ExeGPT system introduces a novel approach to constraint-aware resource scheduling for large language model (LLM) inference. By prioritizing tasks, allocating resources dynamically, and monitoring execution, ExeGPT aims to optimize the performance and efficiency of LLM-based applications. This could have significant implications for a wide range of domains that rely on the capabilities of large language models, from chatbots to time series forecasting.
While the technical details presented in the paper are promising, further research is needed to address the potential limitations, such as generalization to diverse LLM architectures, real-world deployment challenges, and ethical considerations. Nonetheless, the ExeGPT system represents an important step forward in the efficient and effective use of large language models, which are becoming increasingly crucial in our modern, AI-powered world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ExeGPT: Constraint-Aware Resource Scheduling for LLM Inference
Hyungjun Oh, Kihong Kim, Jaemin Kim, Sungkyun Kim, Junyeol Lee, Du-seong Chang, Jiwon Seo
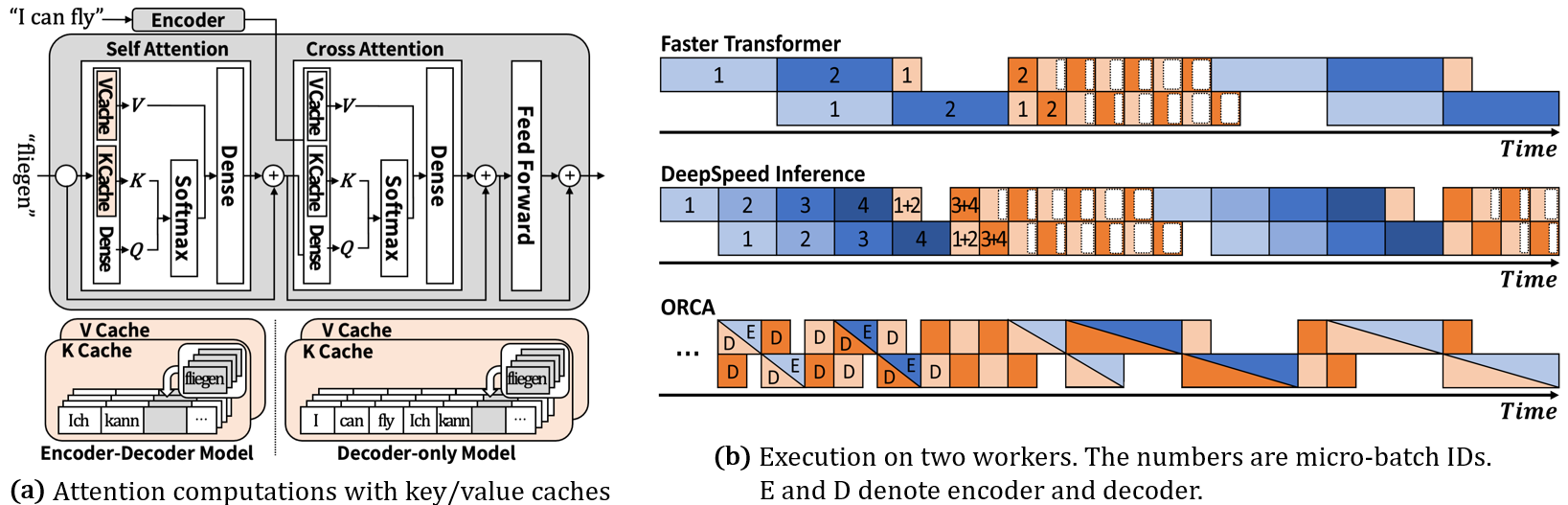
This paper presents ExeGPT, a distributed system designed for constraint-aware LLM inference. ExeGPT finds and runs with an optimal execution schedule to maximize inference throughput while satisfying a given latency constraint. By leveraging the distribution of input and output sequences, it effectively allocates resources and determines optimal execution configurations, including batch sizes and partial tensor parallelism. We also introduce two scheduling strategies based on Round-Robin Allocation and Workload-Aware Allocation policies, suitable for different NLP workloads. We evaluate ExeGPT on six LLM instances of T5, OPT, and GPT-3 and five NLP tasks, each with four distinct latency constraints. Compared to FasterTransformer, ExeGPT achieves up to 15.2x improvements in throughput and 6x improvements in latency. Overall, ExeGPT achieves an average throughput gain of 2.9x across twenty evaluation scenarios. Moreover, when adapting to changing sequence distributions, the cost of adjusting the schedule in ExeGPT is reasonably modest. ExeGPT proves to be an effective solution for optimizing and executing LLM inference for diverse NLP workload and serving conditions.
Read more4/12/2024
🌿
0
ESG: Pipeline-Conscious Efficient Scheduling of DNN Workflows on Serverless Platforms with Shareable GPUs
Xinning Hui, Yuanchao Xu, Zhishan Guo, Xipeng Shen
Recent years have witnessed increasing interest in machine learning inferences on serverless computing for its auto-scaling and cost effective properties. Existing serverless computing, however, lacks effective job scheduling methods to handle the schedule space dramatically expanded by GPU sharing, task batching, and inter-task relations. Prior solutions have dodged the issue by neglecting some important factors, leaving some large performance potential locked. This paper presents ESG, a new scheduling algorithm that directly addresses the difficulties. ESG treats sharable GPU as a first-order factor in scheduling. It employs an optimality-guided adaptive method by combining A*-search and a novel dual-blade pruning to dramatically prune the scheduling space without compromising the quality. It further introduces a novel method, dominator-based SLO distribution, to ensure the scalability of the scheduler. The results show that ESG can significantly improve the SLO hit rates 61%-80% while saving 47%-187% costs over prior work.
Read more4/26/2024
🤯
0
Fast Distributed Inference Serving for Large Language Models
Bingyang Wu, Yinmin Zhong, Zili Zhang, Shengyu Liu, Fangyue Liu, Yuanhang Sun, Gang Huang, Xuanzhe Liu, Xin Jin
Large language models (LLMs) power a new generation of interactive AI applications exemplified by ChatGPT. The interactive nature of these applications demands low latency for LLM inference. Existing LLM serving systems use run-to-completion processing for inference jobs, which suffers from head-of-line blocking and long latency. We present FastServe, a distributed inference serving system for LLMs. FastServe exploits the autoregressive pattern of LLM inference to enable preemption at the granularity of each output token. FastServe uses preemptive scheduling to minimize latency with a novel skip-join Multi-Level Feedback Queue scheduler. Based on the new semi-information-agnostic setting of LLM inference, the scheduler leverages the input length information to assign an appropriate initial queue for each arrival job to join. The higher priority queues than the joined queue are skipped to reduce demotions. We design an efficient GPU memory management mechanism that proactively offloads and uploads intermediate state between GPU memory and host memory for LLM inference. We build a system prototype of FastServe and experimental results show that compared to the state-of-the-art solution vLLM, FastServe improves the throughput by up to 31.4x and 17.9x under the same average and tail latency requirements, respectively.
Read more9/26/2024
0
Differentiable Combinatorial Scheduling at Scale
Mingju Liu, Yingjie Li, Jiaqi Yin, Zhiru Zhang, Cunxi Yu
This paper addresses the complex issue of resource-constrained scheduling, an NP-hard problem that spans critical areas including chip design and high-performance computing. Traditional scheduling methods often stumble over scalability and applicability challenges. We propose a novel approach using a differentiable combinatorial scheduling framework, utilizing Gumbel-Softmax differentiable sampling technique. This new technical allows for a fully differentiable formulation of linear programming (LP) based scheduling, extending its application to a broader range of LP formulations. To encode inequality constraints for scheduling tasks, we introduce textit{constrained Gumbel Trick}, which adeptly encodes arbitrary inequality constraints. Consequently, our method facilitates an efficient and scalable scheduling via gradient descent without the need for training data. Comparative evaluations on both synthetic and real-world benchmarks highlight our capability to significantly improve the optimization efficiency of scheduling, surpassing state-of-the-art solutions offered by commercial and open-source solvers such as CPLEX, Gurobi, and CP-SAT in the majority of the designs.
Read more6/12/2024