An Exploratory Study on Automatic Identification of Assumptions in the Development of Deep Learning Frameworks

0

Sign in to get full access
Overview
- This paper presents an exploratory study on automatically identifying assumptions in the development of deep learning frameworks.
- It investigates methods for detecting hidden assumptions that can impact the performance and reliability of deep learning models.
- The research aims to develop techniques to improve the transparency and interpretability of deep learning systems.
Plain English Explanation
Deep learning has become a powerful tool for a wide range of applications, from image recognition to natural language processing. However, the inner workings of deep neural networks can be complex and opaque, making it difficult to understand the assumptions and biases that are built into these models.
This paper explores ways to automatically identify the hidden assumptions that are made during the development of deep learning frameworks. By shedding light on these assumptions, the researchers hope to improve the transparency and interpretability of deep learning systems, which is crucial for building reliable and trustworthy AI applications.
The paper investigates different techniques that could be used to detect and surface these underlying assumptions, such as analyzing the data used to train the models, examining the model architectures, and studying the training and optimization processes. By better understanding the assumptions and biases inherent in deep learning frameworks, the researchers aim to improve the overall performance and reliability of these powerful AI systems.
Technical Explanation
The paper begins by outlining the motivation for this research, which is to address the lack of transparency and interpretability in deep learning frameworks. The authors note that the complex nature of deep neural networks can lead to hidden assumptions and biases that are difficult to identify, which can impact the performance and reliability of these models.
To address this challenge, the paper explores various techniques for automatically detecting assumptions in deep learning development. The researchers examine methods for analyzing the data used to train the models, including checking for biases or imbalances in the data. They also investigate techniques for studying the model architectures and training processes, to identify any implicit assumptions or design choices that could be influencing the model's behavior.
Through a series of experiments and case studies, the paper presents insights into the types of assumptions that can be found in deep learning frameworks, as well as the effectiveness of different detection methods. The results suggest that a combination of data analysis, architectural examination, and process monitoring can be effective in uncovering hidden assumptions and improving the transparency of deep learning systems.
Critical Analysis
The paper provides a valuable contribution to the field of deep learning by highlighting the importance of identifying and addressing hidden assumptions in the development of these models. The researchers have taken an important step towards improving the transparency and interpretability of deep learning, which is a critical challenge for the widespread adoption and trust in AI systems.
However, the paper also acknowledges some limitations of the proposed techniques. For example, the detection methods may not be able to identify all types of assumptions, and there may be challenges in applying these techniques to large-scale, complex deep learning systems. Additionally, the paper does not address the ethical implications of uncovering and addressing these assumptions, such as the potential to uncover biases or fairness issues in the models.
Further research is needed to build on the insights presented in this paper and develop more comprehensive and robust methods for assumption identification in deep learning. It will also be important to consider the practical challenges of implementing these techniques in real-world AI development workflows, and to explore the ethical considerations associated with this work.
Conclusion
This exploratory study on automatically identifying assumptions in deep learning frameworks represents an important step towards improving the transparency and reliability of these powerful AI systems. By shedding light on the hidden assumptions and biases that can be built into deep learning models, the researchers hope to enable more trustworthy and interpretable AI applications that can have a positive impact on society.
The insights and techniques presented in this paper provide a foundation for further research and development in this critical area of AI safety and ethics. As deep learning continues to advance and become more widely adopted, the ability to detect and address these underlying assumptions will be crucial for ensuring that these AI systems are reliable, fair, and aligned with human values.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An Exploratory Study on Automatic Identification of Assumptions in the Development of Deep Learning Frameworks
Chen Yang, Peng Liang, Zinan Ma
Stakeholders constantly make assumptions in the development of deep learning (DL) frameworks. These assumptions are related to various types of software artifacts (e.g., requirements, design decisions, and technical debt) and can turn out to be invalid, leading to system failures. Existing approaches and tools for assumption management usually depend on manual identification of assumptions. However, assumptions are scattered in various sources (e.g., code comments, commits, and issues) of DL framework development, and manually identifying assumptions has high costs (e.g., time and resources). The objective of the study is to evaluate different classification models for the purpose of identification with respect to assumptions from the point of view of developers and users in the context of DL framework projects (i.e., issues, pull requests, and commits) on GitHub. We constructed a new and largest dataset (i.e., AssuEval) of assumptions collected from the TensorFlow and Keras repositories on GitHub; explored the performance of seven non-transformers based models (e.g., Support Vector Machine, Classification and Regression Trees), the ALBERT model, and three large language models (i.e., ChatGPT, Claude, and Gemini) for identifying assumptions on the AssuEval dataset. The study results show that ALBERT achieves the best performance (f1-score: 0.9584) for identifying assumptions on the AssuEval dataset, which is much better than the other models (the 2nd best f1-score is 0.8858, achieved by the Claude 3.5 Sonnet model). Though ChatGPT, Claude, and Gemini are popular large language models, we do not recommend using them to identify assumptions in DL framework development because of their low performance. This study provides researchers with the largest dataset of assumptions for further research and helps practitioners better understand assumptions and how to manage them in their projects.
Read more7/24/2024
💬
1
Large Language Models for Automated Open-domain Scientific Hypotheses Discovery
Zonglin Yang, Xinya Du, Junxian Li, Jie Zheng, Soujanya Poria, Erik Cambria
Hypothetical induction is recognized as the main reasoning type when scientists make observations about the world and try to propose hypotheses to explain those observations. Past research on hypothetical induction is under a constrained setting: (1) the observation annotations in the dataset are carefully manually handpicked sentences (resulting in a close-domain setting); and (2) the ground truth hypotheses are mostly commonsense knowledge, making the task less challenging. In this work, we tackle these problems by proposing the first dataset for social science academic hypotheses discovery, with the final goal to create systems that automatically generate valid, novel, and helpful scientific hypotheses, given only a pile of raw web corpus. Unlike previous settings, the new dataset requires (1) using open-domain data (raw web corpus) as observations; and (2) proposing hypotheses even new to humanity. A multi-module framework is developed for the task, including three different feedback mechanisms to boost performance, which exhibits superior performance in terms of both GPT-4 based and expert-based evaluation. To the best of our knowledge, this is the first work showing that LLMs are able to generate novel (''not existing in literature'') and valid (''reflecting reality'') scientific hypotheses.
Read more6/13/2024
0
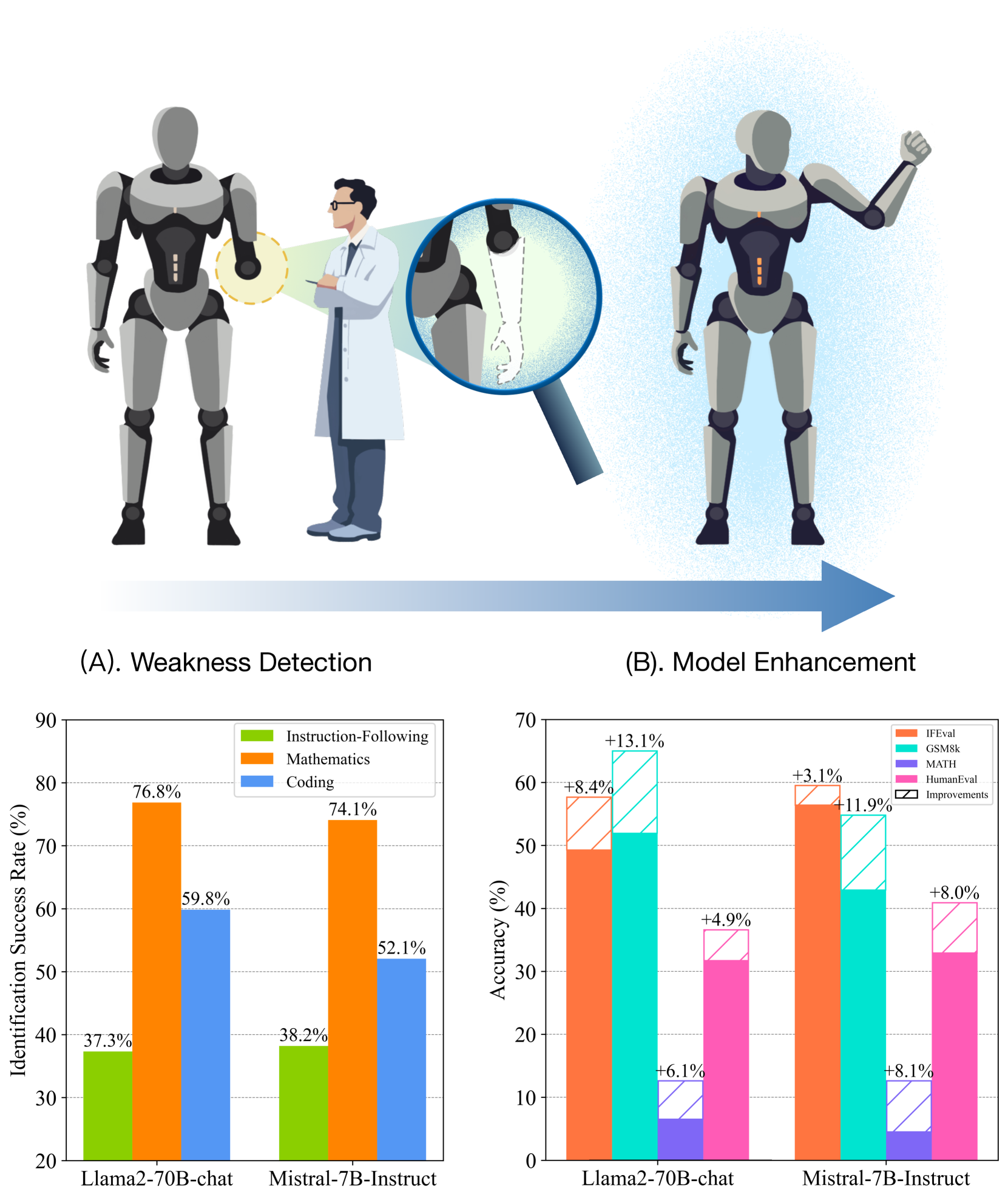
AutoDetect: Towards a Unified Framework for Automated Weakness Detection in Large Language Models
Jiale Cheng, Yida Lu, Xiaotao Gu, Pei Ke, Xiao Liu, Yuxiao Dong, Hongning Wang, Jie Tang, Minlie Huang
Although Large Language Models (LLMs) are becoming increasingly powerful, they still exhibit significant but subtle weaknesses, such as mistakes in instruction-following or coding tasks. As these unexpected errors could lead to severe consequences in practical deployments, it is crucial to investigate the limitations within LLMs systematically. Traditional benchmarking approaches cannot thoroughly pinpoint specific model deficiencies, while manual inspections are costly and not scalable. In this paper, we introduce a unified framework, AutoDetect, to automatically expose weaknesses in LLMs across various tasks. Inspired by the educational assessment process that measures students' learning outcomes, AutoDetect consists of three LLM-powered agents: Examiner, Questioner, and Assessor. The collaboration among these three agents is designed to realize comprehensive and in-depth weakness identification. Our framework demonstrates significant success in uncovering flaws, with an identification success rate exceeding 30% in prominent models such as ChatGPT and Claude. More importantly, these identified weaknesses can guide specific model improvements, proving more effective than untargeted data augmentation methods like Self-Instruct. Our approach has led to substantial enhancements in popular LLMs, including the Llama series and Mistral-7b, boosting their performance by over 10% across several benchmarks. Code and data are publicly available at https://github.com/thu-coai/AutoDetect.
Read more6/26/2024
0
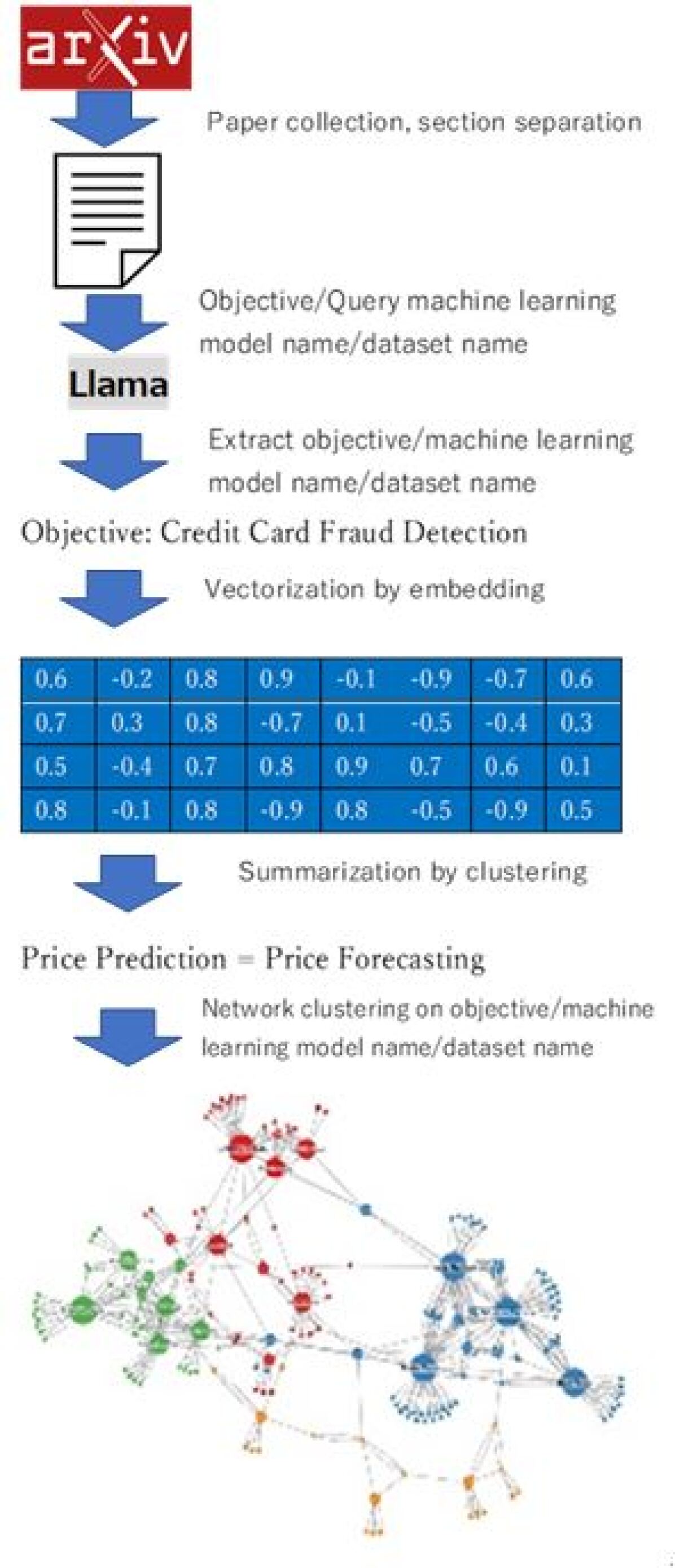
Extraction of Research Objectives, Machine Learning Model Names, and Dataset Names from Academic Papers and Analysis of Their Interrelationships Using LLM and Network Analysis
S. Nishio, H. Nonaka, N. Tsuchiya, A. Migita, Y. Banno, T. Hayashi, H. Sakaji, T. Sakumoto, K. Watabe
Machine learning is widely utilized across various industries. Identifying the appropriate machine learning models and datasets for specific tasks is crucial for the effective industrial application of machine learning. However, this requires expertise in both machine learning and the relevant domain, leading to a high learning cost. Therefore, research focused on extracting combinations of tasks, machine learning models, and datasets from academic papers is critically important, as it can facilitate the automatic recommendation of suitable methods. Conventional information extraction methods from academic papers have been limited to identifying machine learning models and other entities as named entities. To address this issue, this study proposes a methodology extracting tasks, machine learning methods, and dataset names from scientific papers and analyzing the relationships between these information by using LLM, embedding model, and network clustering. The proposed method's expression extraction performance, when using Llama3, achieves an F-score exceeding 0.8 across various categories, confirming its practical utility. Benchmarking results on financial domain papers have demonstrated the effectiveness of this method, providing insights into the use of the latest datasets, including those related to ESG (Environmental, Social, and Governance) data.
Read more8/23/2024