Exploring the Distinctiveness and Fidelity of the Descriptions Generated by Large Vision-Language Models

0
🌀
Sign in to get full access
Overview
- This paper explores the capacity of Large Vision-Language Models (LVLMs) to generate precise, fine-grained textual descriptions of visual data.
- The researchers propose the Textual Retrieval-Augmented Classification (TRAC) framework to analyze the models' performance in terms of distinctiveness and fidelity when describing visual features.
- The study focuses on Open-Flamingo, IDEFICS, and MiniGPT-4, providing insights into the generation quality of these multimodal language models.
Plain English Explanation
Large Vision-Language Models (LVLMs) are a type of artificial intelligence that can process and combine visual and textual data. These models have become increasingly popular, but their ability to generate detailed, precise descriptions of visual features has not been fully explored.
In this study, the researchers looked at how well different LVLMs, such as Open-Flamingo, IDEFICS, and MiniGPT-4, can distinguish between similar objects and accurately describe the visual details. They developed a framework called Textual Retrieval-Augmented Classification (TRAC) to analyze the models' performance in terms of how unique and faithful their textual descriptions were.
The results showed that MiniGPT-4 stood out from the other models, demonstrating a better ability to generate fine-grained descriptions of visual features. This research provides valuable insights into the generation quality of these multimodal language models, helping to improve our understanding of how they can process and describe visual information.
Technical Explanation
The researchers in this study focused on evaluating the capacity of Large Vision-Language Models (LVLMs) to generate precise, fine-grained textual descriptions of visual data. They proposed the Textual Retrieval-Augmented Classification (TRAC) framework to assess the models' performance in terms of distinctiveness and fidelity when describing visual features.
The study examined three LVLMs: Open-Flamingo, IDEFICS, and MiniGPT-4. The TRAC framework leveraged the models' generative capabilities to generate textual descriptions, which were then analyzed for their ability to distinguish between similar objects and accurately capture visual details.
The results showed that MiniGPT-4 outperformed the other two models in its ability to generate fine-grained descriptions, demonstrating a stronger capacity to process and integrate visual and textual data. This research provides valuable insights into the generation quality of these multimodal language models, enhancing our understanding of their potential and limitations in the field of vision-language processing.
Critical Analysis
The paper provides a comprehensive evaluation of the fine-grained textual description generation capabilities of Large Vision-Language Models (LVLMs). However, the authors acknowledge that the study is limited in scope, focusing primarily on three specific models: Open-Flamingo, IDEFICS, and MiniGPT-4.
While the Textual Retrieval-Augmented Classification (TRAC) framework offers a structured approach to assessing distinctiveness and fidelity, it is unclear how the results from this framework translate to real-world applications. Future research should explore the practical implications of these findings and investigate the performance of LVLMs in more diverse and complex visual scenarios.
Additionally, the paper does not delve into the potential biases or limitations of the TRAC framework itself. It would be valuable to understand how the framework's design choices and evaluation metrics might influence the findings, and whether alternative approaches could provide a more comprehensive assessment of LVLM capabilities.
Overall, this study provides a strong foundation for understanding the fine-grained textual description generation abilities of LVLMs. However, further research is needed to fully explore the generalizability and robustness of these models, as well as their potential applications in real-world scenarios.
Conclusion
This paper explores the capacity of Large Vision-Language Models (LVLMs) to generate precise, fine-grained textual descriptions of visual data. By proposing the Textual Retrieval-Augmented Classification (TRAC) framework, the researchers were able to assess the distinctiveness and fidelity of textual descriptions generated by three LVLM models: Open-Flamingo, IDEFICS, and MiniGPT-4.
The results of this study indicate that MiniGPT-4 stands out for its superior ability to generate fine-grained descriptions, outperforming the other two models in this aspect. This research provides valuable insights into the generation quality of these multimodal language models, enhancing our understanding of their potential and limitations in the field of vision-language processing.
As the field of large vision-language models continues to evolve, this study serves as an important contribution, highlighting the need for further exploration of these models' fine-grained textual description capabilities and their broader applications in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
0
Exploring the Distinctiveness and Fidelity of the Descriptions Generated by Large Vision-Language Models
Yuhang Huang, Zihan Wu, Chongyang Gao, Jiawei Peng, Xu Yang
Large Vision-Language Models (LVLMs) are gaining traction for their remarkable ability to process and integrate visual and textual data. Despite their popularity, the capacity of LVLMs to generate precise, fine-grained textual descriptions has not been fully explored. This study addresses this gap by focusing on textit{distinctiveness} and textit{fidelity}, assessing how models like Open-Flamingo, IDEFICS, and MiniGPT-4 can distinguish between similar objects and accurately describe visual features. We proposed the Textual Retrieval-Augmented Classification (TRAC) framework, which, by leveraging its generative capabilities, allows us to delve deeper into analyzing fine-grained visual description generation. This research provides valuable insights into the generation quality of LVLMs, enhancing the understanding of multimodal language models. Notably, MiniGPT-4 stands out for its better ability to generate fine-grained descriptions, outperforming the other two models in this aspect. The code is provided at url{https://anonymous.4open.science/r/Explore_FGVDs-E277}.
Read more4/29/2024

0
DTLLM-VLT: Diverse Text Generation for Visual Language Tracking Based on LLM
Xuchen Li, Xiaokun Feng, Shiyu Hu, Meiqi Wu, Dailing Zhang, Jing Zhang, Kaiqi Huang
Visual Language Tracking (VLT) enhances single object tracking (SOT) by integrating natural language descriptions from a video, for the precise tracking of a specified object. By leveraging high-level semantic information, VLT guides object tracking, alleviating the constraints associated with relying on a visual modality. Nevertheless, most VLT benchmarks are annotated in a single granularity and lack a coherent semantic framework to provide scientific guidance. Moreover, coordinating human annotators for high-quality annotations is laborious and time-consuming. To address these challenges, we introduce DTLLM-VLT, which automatically generates extensive and multi-granularity text to enhance environmental diversity. (1) DTLLM-VLT generates scientific and multi-granularity text descriptions using a cohesive prompt framework. Its succinct and highly adaptable design allows seamless integration into various visual tracking benchmarks. (2) We select three prominent benchmarks to deploy our approach: short-term tracking, long-term tracking, and global instance tracking. We offer four granularity combinations for these benchmarks, considering the extent and density of semantic information, thereby showcasing the practicality and versatility of DTLLM-VLT. (3) We conduct comparative experiments on VLT benchmarks with different text granularities, evaluating and analyzing the impact of diverse text on tracking performance. Conclusionally, this work leverages LLM to provide multi-granularity semantic information for VLT task from efficient and diverse perspectives, enabling fine-grained evaluation of multi-modal trackers. In the future, we believe this work can be extended to more datasets to support vision datasets understanding.
Read more5/21/2024
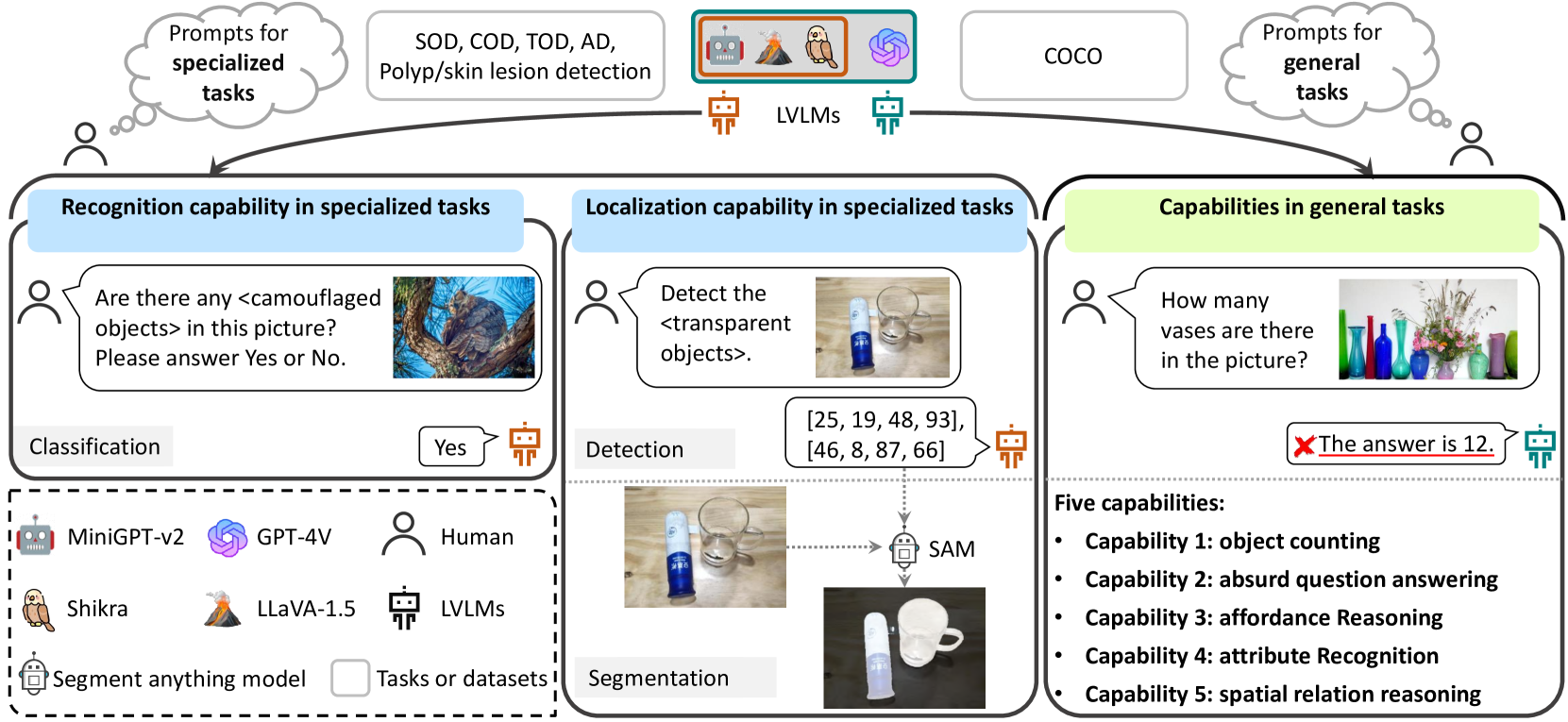
0
Effectiveness Assessment of Recent Large Vision-Language Models
Yao Jiang, Xinyu Yan, Ge-Peng Ji, Keren Fu, Meijun Sun, Huan Xiong, Deng-Ping Fan, Fahad Shahbaz Khan
The advent of large vision-language models (LVLMs) represents a remarkable advance in the quest for artificial general intelligence. However, the model's effectiveness in both specialized and general tasks warrants further investigation. This paper endeavors to evaluate the competency of popular LVLMs in specialized and general tasks, respectively, aiming to offer a comprehensive understanding of these novel models. To gauge their effectiveness in specialized tasks, we employ six challenging tasks in three different application scenarios: natural, healthcare, and industrial. These six tasks include salient/camouflaged/transparent object detection, as well as polyp detection, skin lesion detection, and industrial anomaly detection. We examine the performance of three recent open-source LVLMs, including MiniGPT-v2, LLaVA-1.5, and Shikra, on both visual recognition and localization in these tasks. Moreover, we conduct empirical investigations utilizing the aforementioned LVLMs together with GPT-4V, assessing their multi-modal understanding capabilities in general tasks including object counting, absurd question answering, affordance reasoning, attribute recognition, and spatial relation reasoning. Our investigations reveal that these LVLMs demonstrate limited proficiency not only in specialized tasks but also in general tasks. We delve deep into this inadequacy and uncover several potential factors, including limited cognition in specialized tasks, object hallucination, text-to-image interference, and decreased robustness in complex problems. We hope that this study can provide useful insights for the future development of LVLMs, helping researchers improve LVLMs for both general and specialized applications.
Read more6/12/2024
👀
0
Constructing Multilingual Visual-Text Datasets Revealing Visual Multilingual Ability of Vision Language Models
Jesse Atuhurra, Iqra Ali, Tatsuya Hiraoka, Hidetaka Kamigaito, Tomoya Iwakura, Taro Watanabe
Large language models (LLMs) have increased interest in vision language models (VLMs), which process image-text pairs as input. Studies investigating the visual understanding ability of VLMs have been proposed, but such studies are still preliminary because existing datasets do not permit a comprehensive evaluation of the fine-grained visual linguistic abilities of VLMs across multiple languages. To further explore the strengths of VLMs, such as GPT-4V cite{openai2023GPT4}, we developed new datasets for the systematic and qualitative analysis of VLMs. Our contribution is four-fold: 1) we introduced nine vision-and-language (VL) tasks (including object recognition, image-text matching, and more) and constructed multilingual visual-text datasets in four languages: English, Japanese, Swahili, and Urdu through utilizing templates containing textit{questions} and prompting GPT4-V to generate the textit{answers} and the textit{rationales}, 2) introduced a new VL task named textit{unrelatedness}, 3) introduced rationales to enable human understanding of the VLM reasoning process, and 4) employed human evaluation to measure the suitability of proposed datasets for VL tasks. We show that VLMs can be fine-tuned on our datasets. Our work is the first to conduct such analyses in Swahili and Urdu. Also, it introduces textit{rationales} in VL analysis, which played a vital role in the evaluation.
Read more6/26/2024