Extending Multilingual Speech Synthesis to 100+ Languages without Transcribed Data

0

Sign in to get full access
Overview
- This paper presents a novel framework for extending multilingual speech synthesis to over 100 languages without requiring transcribed data.
- The proposed approach leverages multilingual speech data and leverages self-supervised learning to enable speech synthesis in a wide range of languages.
- The framework can produce high-quality synthetic speech in low-resource languages, addressing a key challenge in the field of speech synthesis.
Plain English Explanation
The paper describes a new way to generate high-quality synthetic speech in a large number of languages, even if there isn't much data available for those languages.
The key idea is to use meta-learning techniques to train a model that can adapt to new languages quickly, without needing a lot of transcribed speech data.
The model first learns general speech patterns by being exposed to data from many different languages. Then, it can use that knowledge to generate synthetic speech in a new language, even if there's only a small amount of data available for that language.
This approach addresses a major limitation in speech synthesis - the need for large, high-quality datasets in each target language. By reducing this data requirement, the framework opens up the possibility of building speech synthesis systems for a much wider range of languages, including low-resource ones.
Technical Explanation
The proposed framework consists of two main components: a multilingual speech encoder and a language-specific speech decoder.
The multilingual speech encoder is trained on speech data from many different languages using self-supervised learning techniques like data augmentation and unsupervised speech recognition. This allows the encoder to learn general speech representations that are useful across a wide range of languages.
The language-specific speech decoder is then trained on a small amount of data for each target language. By leveraging the shared representations from the multilingual encoder, the decoder can quickly adapt to generate high-quality synthetic speech, even in low-resource settings.
The authors demonstrate the effectiveness of this approach by evaluating the framework on over 100 languages, showing that it can achieve state-of-the-art performance in terms of speech quality and intelligibility, while requiring much less data than traditional methods.
Critical Analysis
The paper presents a compelling and well-designed framework that addresses a significant challenge in the field of speech synthesis. By reducing the data requirements for building speech systems in new languages, the approach has the potential to greatly expand the accessibility of speech technology.
However, the authors do acknowledge some limitations of the current work. For example, the framework may struggle with languages that have very different phonological characteristics from the languages in the training data. Additionally, the authors note that further research is needed to improve the accuracy of speech recognition and translation in low-resource settings.
Overall, this research represents an important step forward in the quest to build truly multilingual speech synthesis systems that can be deployed across a wide range of languages and contexts.
Conclusion
This paper introduces a novel framework for extending multilingual speech synthesis to over 100 languages without the need for large, transcribed datasets in each target language. By leveraging self-supervised learning and meta-learning techniques, the approach can generate high-quality synthetic speech even in low-resource settings.
The authors demonstrate the effectiveness of their framework through extensive evaluations, showing that it outperforms traditional methods while requiring much less data. This work has significant implications for the development of speech technology that is more accessible and inclusive, particularly for underserved languages and communities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Extending Multilingual Speech Synthesis to 100+ Languages without Transcribed Data
Takaaki Saeki, Gary Wang, Nobuyuki Morioka, Isaac Elias, Kyle Kastner, Fadi Biadsy, Andrew Rosenberg, Bhuvana Ramabhadran, Heiga Zen, Franc{c}oise Beaufays, Hadar Shemtov
Collecting high-quality studio recordings of audio is challenging, which limits the language coverage of text-to-speech (TTS) systems. This paper proposes a framework for scaling a multilingual TTS model to 100+ languages using found data without supervision. The proposed framework combines speech-text encoder pretraining with unsupervised training using untranscribed speech and unspoken text data sources, thereby leveraging massively multilingual joint speech and text representation learning. Without any transcribed speech in a new language, this TTS model can generate intelligible speech in >30 unseen languages (CER difference of <10% to ground truth). With just 15 minutes of transcribed, found data, we can reduce the intelligibility difference to 1% or less from the ground-truth, and achieve naturalness scores that match the ground-truth in several languages.
Read more7/17/2024

0
Meta Learning Text-to-Speech Synthesis in over 7000 Languages
Florian Lux, Sarina Meyer, Lyonel Behringer, Frank Zalkow, Phat Do, Matt Coler, Emanuel A. P. Habets, Ngoc Thang Vu
In this work, we take on the challenging task of building a single text-to-speech synthesis system that is capable of generating speech in over 7000 languages, many of which lack sufficient data for traditional TTS development. By leveraging a novel integration of massively multilingual pretraining and meta learning to approximate language representations, our approach enables zero-shot speech synthesis in languages without any available data. We validate our system's performance through objective measures and human evaluation across a diverse linguistic landscape. By releasing our code and models publicly, we aim to empower communities with limited linguistic resources and foster further innovation in the field of speech technology.
Read more6/11/2024

0
A multilingual training strategy for low resource Text to Speech
Asma Amalas, Mounir Ghogho, Mohamed Chetouani, Rachid Oulad Haj Thami
Recent speech technologies have led to produce high quality synthesised speech due to recent advances in neural Text to Speech (TTS). However, such TTS models depend on extensive amounts of data that can be costly to produce and is hardly scalable to all existing languages, especially that seldom attention is given to low resource languages. With techniques such as knowledge transfer, the burden of creating datasets can be alleviated. In this paper, we therefore investigate two aspects; firstly, whether data from social media can be used for a small TTS dataset construction, and secondly whether cross lingual transfer learning (TL) for a low resource language can work with this type of data. In this aspect, we specifically assess to what extent multilingual modeling can be leveraged as an alternative to training on monolingual corporas. To do so, we explore how data from foreign languages may be selected and pooled to train a TTS model for a target low resource language. Our findings show that multilingual pre-training is better than monolingual pre-training at increasing the intelligibility and naturalness of the generated speech.
Read more9/4/2024
0
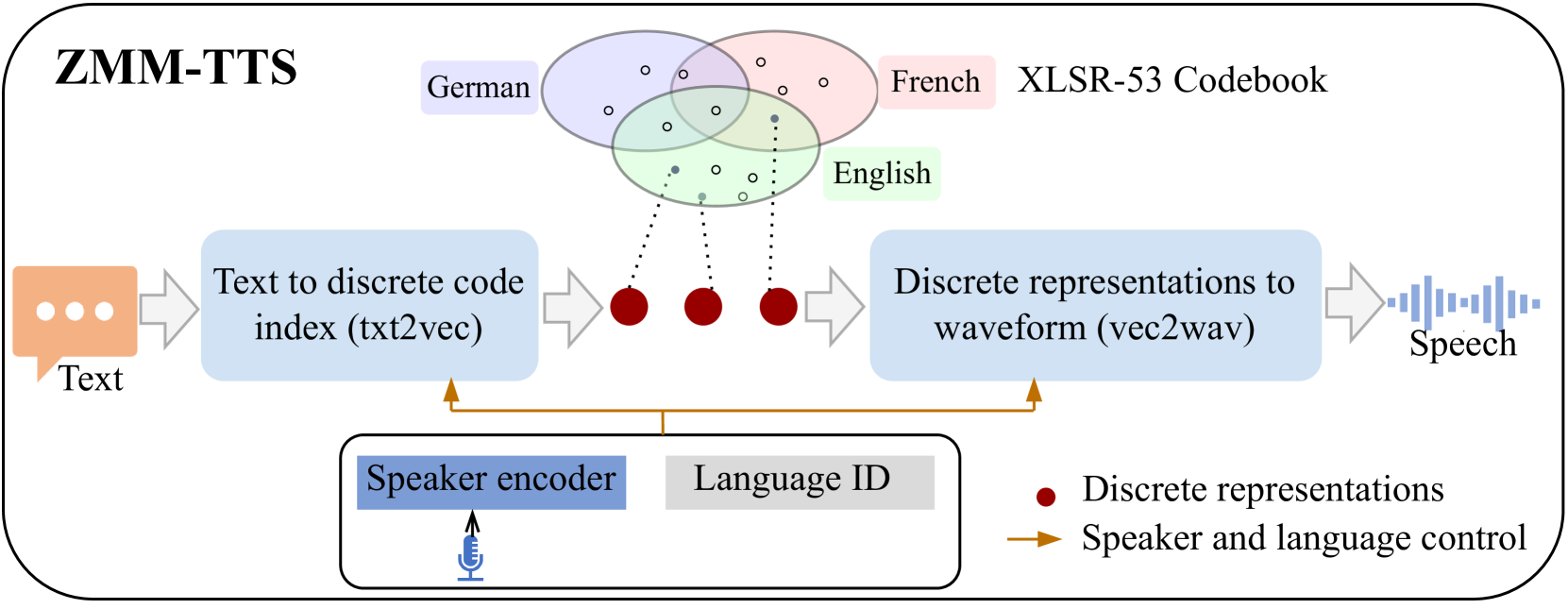
ZMM-TTS: Zero-shot Multilingual and Multispeaker Speech Synthesis Conditioned on Self-supervised Discrete Speech Representations
Cheng Gong, Xin Wang, Erica Cooper, Dan Wells, Longbiao Wang, Jianwu Dang, Korin Richmond, Junichi Yamagishi
Neural text-to-speech (TTS) has achieved human-like synthetic speech for single-speaker, single-language synthesis. Multilingual TTS systems are limited to resource-rich languages due to the lack of large paired text and studio-quality audio data. TTS systems are typically built using a single speaker's voices, but there is growing interest in developing systems that can synthesize voices for new speakers using only a few seconds of their speech. This paper presents ZMM-TTS, a multilingual and multispeaker framework utilizing quantized latent speech representations from a large-scale, pre-trained, self-supervised model. Our paper combines text-based and speech-based self-supervised learning models for multilingual speech synthesis. Our proposed model has zero-shot generalization ability not only for unseen speakers but also for unseen languages. We have conducted comprehensive subjective and objective evaluations through a series of experiments. Our model has proven effective in terms of speech naturalness and similarity for both seen and unseen speakers in six high-resource languages. We also tested the efficiency of our method on two hypothetically low-resource languages. The results are promising, indicating that our proposed approach can synthesize audio that is intelligible and has a high degree of similarity to the target speaker's voice, even without any training data for the new, unseen language.
Read more8/28/2024