Inference-Time Rule Eraser: Distilling and Removing Bias Rules to Mitigate Bias in Deployed Models

0
🤔
Sign in to get full access
Overview
- This paper introduces a novel approach called "Inference-Time Rule Eraser" to mitigate bias in deployed machine learning models.
- The key idea is to distill and remove the biased "rules" learned by the model during training, which can lead to unfair decisions at inference time.
- The authors propose a method to identify and remove these biased rules, thereby enhancing the overall fairness of the model without retraining.
Plain English Explanation
Machine learning models can often learn unintended "rules" during the training process that lead to unfair or biased decisions. For example, a model tasked with predicting creditworthiness might learn to associate certain demographic factors with creditworthiness, even if those factors don't directly impact one's ability to repay a loan. When deployed, these biased rules can result in unfair outcomes for certain groups.
The "Inference-Time Rule Eraser" approach aims to address this problem by analyzing the trained model and identifying the specific rules that are contributing to unfairness. Once these biased rules are detected, they can be removed or "erased" from the model, without the need to retrain the entire model from scratch. This allows the model to be "debiased" at the point of deployment, enhancing its fairness while preserving its overall performance.
By linking to relevant research papers, increasing fairness in classification on out-of-distribution data, and providing fair machine guidance to enhance fair decision-making, this approach represents an important step towards developing more ethical and equitable AI systems.
Technical Explanation
The core of the "Inference-Time Rule Eraser" approach is a two-stage process. First, the model is analyzed to identify the specific rules that are contributing to unfairness. This is done by probing the model's decision-making process and extracting the key features and decision thresholds that are most strongly associated with biased outcomes.
Next, these biased rules are "erased" from the model by modifying the model's internal parameters to remove or minimize the influence of the identified rules. This is achieved through a novel optimization-based technique that adjusts the model's weights and biases without retraining the entire model.
The authors evaluate their approach on several real-world datasets, demonstrating its ability to significantly improve the fairness of the model without compromising its overall performance. They also compare their method to other techniques for achieving fairness in machine learning and quantifying and calculating fairness-unfairness in binary and multiclass classification.
Critical Analysis
The "Inference-Time Rule Eraser" approach represents an important contribution to the field of fair and ethical AI. By identifying and removing biased rules at the point of deployment, it offers a practical solution to a challenging problem that is often difficult to address through traditional model training and optimization techniques.
However, the authors acknowledge that their method is not a panacea for all fairness issues in machine learning. The approach relies on the ability to accurately identify and isolate the specific rules that are contributing to unfairness, which can be challenging in complex models with intricate decision-making processes.
Additionally, while the authors demonstrate the effectiveness of their approach on several datasets, it remains to be seen how well it will generalize to a wider range of applications and domains. Further research is needed to understand the limitations and potential edge cases of this technique.
Conclusion
The "Inference-Time Rule Eraser" method presented in this paper represents a significant step towards developing more fair and ethical AI systems. By identifying and removing biased rules at the point of deployment, the approach offers a practical solution to a pressing problem in the field of machine learning.
While not a panacea, this work highlights the importance of continued research and innovation in the area of fairness and bias mitigation in AI. As these technologies become increasingly ubiquitous, it is crucial that we develop effective tools and techniques to ensure they are used in a responsible and equitable manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
0
Inference-Time Rule Eraser: Distilling and Removing Bias Rules to Mitigate Bias in Deployed Models
Yi Zhang, Dongyuan Lu, Jitao Sang
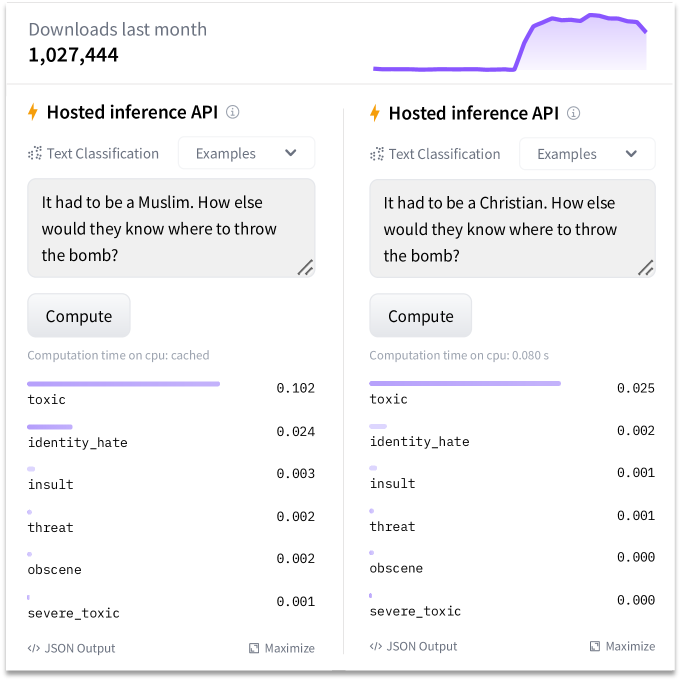
Machine learning models often make predictions based on biased features such as gender, race, and other social attributes, posing significant fairness risks, especially in societal applications, such as hiring, banking, and criminal justice. Traditional approaches to addressing this issue involve retraining or fine-tuning neural networks with fairness-aware optimization objectives. However, these methods can be impractical due to significant computational resources, complex industrial tests, and the associated CO2 footprint. Additionally, regular users often fail to fine-tune models because they lack access to model parameters In this paper, we introduce the Inference-Time Rule Eraser (Eraser), a novel method designed to address fairness concerns by removing biased decision-making rules from deployed models during inference without altering model weights. We begin by establishing a theoretical foundation for modifying model outputs to eliminate biased rules through Bayesian analysis. Next, we present a specific implementation of Eraser that involves two stages: (1) distilling the biased rules from the deployed model into an additional patch model, and (2) removing these biased rules from the output of the deployed model during inference. Extensive experiments validate the effectiveness of our approach, showcasing its superior performance in addressing fairness concerns in AI systems.
Read more8/28/2024
0
fairBERTs: Erasing Sensitive Information Through Semantic and Fairness-aware Perturbations
Jinfeng Li, Yuefeng Chen, Xiangyu Liu, Longtao Huang, Rong Zhang, Hui Xue
Pre-trained language models (PLMs) have revolutionized both the natural language processing research and applications. However, stereotypical biases (e.g., gender and racial discrimination) encoded in PLMs have raised negative ethical implications for PLMs, which critically limits their broader applications. To address the aforementioned unfairness issues, we present fairBERTs, a general framework for learning fair fine-tuned BERT series models by erasing the protected sensitive information via semantic and fairness-aware perturbations generated by a generative adversarial network. Through extensive qualitative and quantitative experiments on two real-world tasks, we demonstrate the great superiority of fairBERTs in mitigating unfairness while maintaining the model utility. We also verify the feasibility of transferring adversarial components in fairBERTs to other conventionally trained BERT-like models for yielding fairness improvements. Our findings may shed light on further research on building fairer fine-tuned PLMs.
Read more7/12/2024

0
Inference-Time Selective Debiasing
Gleb Kuzmin, Neemesh Yadav, Ivan Smirnov, Timothy Baldwin, Artem Shelmanov
We propose selective debiasing -- an inference-time safety mechanism that aims to increase the overall quality of models in terms of prediction performance and fairness in the situation when re-training a model is prohibitive. The method is inspired by selective prediction, where some predictions that are considered low quality are discarded at inference time. In our approach, we identify the potentially biased model predictions and, instead of discarding them, we debias them using LEACE -- a post-processing debiasing method. To select problematic predictions, we propose a bias quantification approach based on KL divergence, which achieves better results than standard UQ methods. Experiments with text classification datasets demonstrate that selective debiasing helps to close the performance gap between post-processing methods and at-training and pre-processing debiasing techniques.
Read more8/22/2024
💬
0
Recovering from Biased Data: Can Fairness Constraints Improve Accuracy?
Avrim Blum, Kevin Stangl
Multiple fairness constraints have been proposed in the literature, motivated by a range of concerns about how demographic groups might be treated unfairly by machine learning classifiers. In this work we consider a different motivation; learning from biased training data. We posit several ways in which training data may be biased, including having a more noisy or negatively biased labeling process on members of a disadvantaged group, or a decreased prevalence of positive or negative examples from the disadvantaged group, or both. Given such biased training data, Empirical Risk Minimization (ERM) may produce a classifier that not only is biased but also has suboptimal accuracy on the true data distribution. We examine the ability of fairness-constrained ERM to correct this problem. In particular, we find that the Equal Opportunity fairness constraint (Hardt, Price, and Srebro 2016) combined with ERM will provably recover the Bayes Optimal Classifier under a range of bias models. We also consider other recovery methods including reweighting the training data, Equalized Odds, and Demographic Parity. These theoretical results provide additional motivation for considering fairness interventions even if an actor cares primarily about accuracy.
Read more8/23/2024