FineSurE: Fine-grained Summarization Evaluation using LLMs

0

Sign in to get full access
Overview
- FineSurE: A framework for fine-grained evaluation of text summarization models using large language models (LLMs)
- Aims to provide a more comprehensive assessment of summarization quality beyond traditional metrics like ROUGE
- Leverages the language understanding capabilities of LLMs to evaluate semantic, factual, and linguistic aspects of summaries
Plain English Explanation
FineSurE is a new approach to evaluating the quality of text summarization models. Traditionally, summarization quality has been measured using metrics like ROUGE, which compare the overlap between a generated summary and a reference summary. However, these metrics don't provide a complete picture of the summary's quality.
FineSurE aims to give a more detailed and nuanced evaluation by tapping into the language understanding capabilities of large language models (LLMs). These powerful AI models can assess various aspects of the summary, including:
- Semantic Similarity: How well does the summary capture the key meaning and content of the original text?
- Factual Consistency: Does the summary accurately represent the facts and information from the original text?
- Linguistic Quality: Is the summary well-written, fluent, and grammatically correct?
By evaluating summaries across these different dimensions, FineSurE provides a more comprehensive assessment of summarization quality. This can help researchers and developers better understand the strengths and weaknesses of their summarization models and make more informed improvements.
Technical Explanation
FineSurE works by fine-tuning LLMs, such as BERT or GPT, on specific evaluation tasks related to summarization quality. For example, the model might be trained to assess the semantic similarity between a summary and the original text, or to identify factual inconsistencies in the summary.
Once the LLM is fine-tuned, it can be used to score summaries on these different quality dimensions. The researchers evaluated FineSurE on a range of summarization datasets and compared its performance to traditional metrics like ROUGE. They found that FineSurE was able to provide a more nuanced and informative evaluation of summarization quality.
The Fractal and SuRE approaches discussed in the paper provide additional ways to leverage LLMs for fine-grained summarization evaluation. These techniques aim to further improve the granularity and reliability of the assessment.
Critical Analysis
The FineSurE framework represents an important step forward in summarization evaluation, but it also has some limitations. The researchers acknowledge that the performance of FineSurE is still dependent on the quality and robustness of the underlying LLM. If the LLM has biases or blind spots, these could be reflected in the FineSurE scores.
Additionally, the FactCheck Bench paper raises some concerns about the ability of LLMs to reliably detect factual inconsistencies in summaries, which is a key aspect of the FineSurE evaluation.
Further research is needed to fully understand the strengths and weaknesses of FineSurE and similar LLM-based evaluation approaches. Exploring ways to make these techniques more robust and reliable will be an important area of focus going forward.
Conclusion
FineSurE represents a promising new approach to evaluating text summarization models. By leveraging the language understanding capabilities of LLMs, it can provide a more comprehensive and nuanced assessment of summarization quality. This can help researchers and developers better understand the performance of their models and make more informed improvements.
While FineSurE has some limitations, it demonstrates the potential of using advanced AI techniques to enhance the evaluation of complex natural language processing tasks. As the field of summarization continues to evolve, tools like FineSurE will likely play an increasingly important role in driving progress and innovation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FineSurE: Fine-grained Summarization Evaluation using LLMs
Hwanjun Song, Hang Su, Igor Shalyminov, Jason Cai, Saab Mansour
Automated evaluation is crucial for streamlining text summarization benchmarking and model development, given the costly and time-consuming nature of human evaluation. Traditional methods like ROUGE do not correlate well with human judgment, while recently proposed LLM-based metrics provide only summary-level assessment using Likert-scale scores. This limits deeper model analysis, e.g., we can only assign one hallucination score at the summary level, while at the sentence level, we can count sentences containing hallucinations. To remedy those limitations, we propose FineSurE, a fine-grained evaluator specifically tailored for the summarization task using large language models (LLMs). It also employs completeness and conciseness criteria, in addition to faithfulness, enabling multi-dimensional assessment. We compare various open-source and proprietary LLMs as backbones for FineSurE. In addition, we conduct extensive benchmarking of FineSurE against SOTA methods including NLI-, QA-, and LLM-based methods, showing improved performance especially on the completeness and conciseness dimensions. The code is available at https://github.com/DISL-Lab/FineSurE-ACL24.
Read more7/23/2024

0
A Comparative Study of Quality Evaluation Methods for Text Summarization
Huyen Nguyen, Haihua Chen, Lavanya Pobbathi, Junhua Ding
Evaluating text summarization has been a challenging task in natural language processing (NLP). Automatic metrics which heavily rely on reference summaries are not suitable in many situations, while human evaluation is time-consuming and labor-intensive. To bridge this gap, this paper proposes a novel method based on large language models (LLMs) for evaluating text summarization. We also conducts a comparative study on eight automatic metrics, human evaluation, and our proposed LLM-based method. Seven different types of state-of-the-art (SOTA) summarization models were evaluated. We perform extensive experiments and analysis on datasets with patent documents. Our results show that LLMs evaluation aligns closely with human evaluation, while widely-used automatic metrics such as ROUGE-2, BERTScore, and SummaC do not and also lack consistency. Based on the empirical comparison, we propose a LLM-powered framework for automatically evaluating and improving text summarization, which is beneficial and could attract wide attention among the community.
Read more7/2/2024
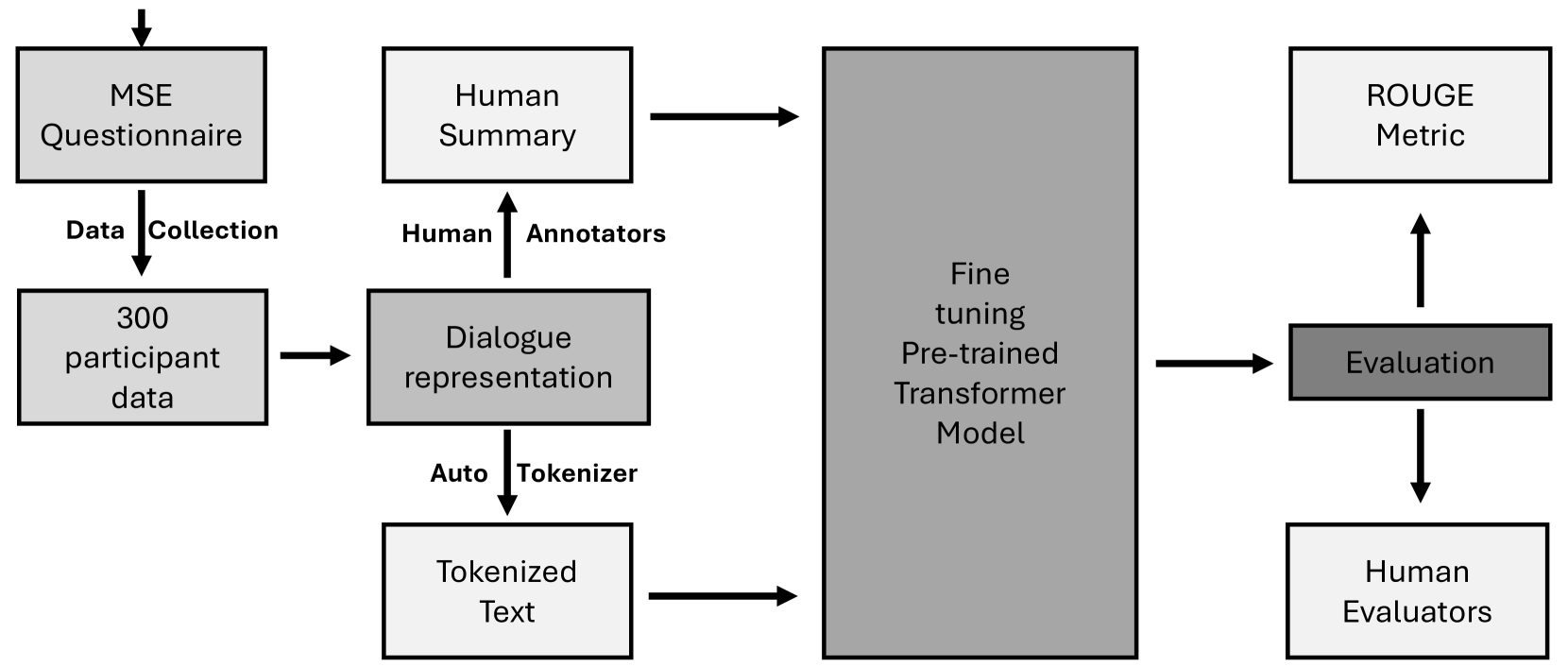
0
Fine-tuning Large Language Models for Automated Diagnostic Screening Summaries
Manjeet Yadav, Nilesh Kumar Sahu, Mudita Chaturvedi, Snehil Gupta, Haroon R Lone
Improving mental health support in developing countries is a pressing need. One potential solution is the development of scalable, automated systems to conduct diagnostic screenings, which could help alleviate the burden on mental health professionals. In this work, we evaluate several state-of-the-art Large Language Models (LLMs), with and without fine-tuning, on our custom dataset for generating concise summaries from mental state examinations. We rigorously evaluate four different models for summary generation using established ROUGE metrics and input from human evaluators. The results highlight that our top-performing fine-tuned model outperforms existing models, achieving ROUGE-1 and ROUGE-L values of 0.810 and 0.764, respectively. Furthermore, we assessed the fine-tuned model's generalizability on a publicly available D4 dataset, and the outcomes were promising, indicating its potential applicability beyond our custom dataset.
Read more4/5/2024

0
Closing the gap between open-source and commercial large language models for medical evidence summarization
Gongbo Zhang, Qiao Jin, Yiliang Zhou, Song Wang, Betina R. Idnay, Yiming Luo, Elizabeth Park, Jordan G. Nestor, Matthew E. Spotnitz, Ali Soroush, Thomas Campion, Zhiyong Lu, Chunhua Weng, Yifan Peng
Large language models (LLMs) hold great promise in summarizing medical evidence. Most recent studies focus on the application of proprietary LLMs. Using proprietary LLMs introduces multiple risk factors, including a lack of transparency and vendor dependency. While open-source LLMs allow better transparency and customization, their performance falls short compared to proprietary ones. In this study, we investigated to what extent fine-tuning open-source LLMs can further improve their performance in summarizing medical evidence. Utilizing a benchmark dataset, MedReview, consisting of 8,161 pairs of systematic reviews and summaries, we fine-tuned three broadly-used, open-sourced LLMs, namely PRIMERA, LongT5, and Llama-2. Overall, the fine-tuned LLMs obtained an increase of 9.89 in ROUGE-L (95% confidence interval: 8.94-10.81), 13.21 in METEOR score (95% confidence interval: 12.05-14.37), and 15.82 in CHRF score (95% confidence interval: 13.89-16.44). The performance of fine-tuned LongT5 is close to GPT-3.5 with zero-shot settings. Furthermore, smaller fine-tuned models sometimes even demonstrated superior performance compared to larger zero-shot models. The above trends of improvement were also manifested in both human and GPT4-simulated evaluations. Our results can be applied to guide model selection for tasks demanding particular domain knowledge, such as medical evidence summarization.
Read more8/2/2024