Found in the Middle: Permutation Self-Consistency Improves Listwise Ranking in Large Language Models

0
💬
Sign in to get full access
Overview
- Large language models (LLMs) can exhibit positional bias, meaning they use context differently depending on the order of elements, which complicates listwise ranking tasks.
- The researchers propose a method called "permutation self-consistency" to address this issue by marginalizing out order biases in the prompt.
- The approach involves shuffling the list in the prompt, passing it through the LLM, and then aggregating the resulting rankings to produce an order-independent ranking.
- Experiments on list-ranking datasets show significant improvements over conventional inference, surpassing previous state-of-the-art methods.
Plain English Explanation
Large language models (LLMs) like GPT-3.5 and LLaMA v2 are powerful AI systems that can generate human-like text. However, these models can sometimes be biased by the order of the information they're given. This is a particular problem when they're asked to rank a list of items, as their rankings may be influenced by the order in which the items are presented.
To address this issue, the researchers developed a technique called "permutation self-consistency." The key idea is to repeatedly shuffle the order of the items in the prompt, pass each version through the LLM, and then combine the resulting rankings into a single, order-independent ranking. This helps to neutralize the positional biases that the LLM might otherwise exhibit.
Consolidating Ranking Relevance Predictions in Large Language Models and PICO: Peer-Review LLMs via Consistency Optimization are two related techniques that also aim to improve the consistency and reliability of LLM outputs.
The researchers tested their permutation self-consistency approach on several list-ranking datasets, including tasks like sorting and passage reranking. They found that it could improve the rankings produced by GPT-3.5 and LLaMA v2 by up to 7-18% and 8-16%, respectively, outperforming previous state-of-the-art methods.
Technical Explanation
The researchers start by observing that large language models (LLMs) can exhibit positional bias, meaning they use context differently depending on the order of elements in the input. This is particularly problematic for listwise ranking tasks, where the model's rankings may be influenced by the order in which items are presented.
To address this issue, the researchers propose a method called "permutation self-consistency." The key idea is to marginalize out the order biases in the prompt by repeatedly shuffling the list and passing it through the LLM while holding the instructions constant. This produces a sample of rankings, which are then aggregated to compute a central ranking that is less affected by positional biases.
Mathematically, the approach can be summarized as follows:
- Given an input prompt containing a list, repeatedly shuffle the order of the list.
- Pass each shuffled prompt through the black-box LLM to obtain a set of rankings.
- Compute the central ranking that is closest in distance to all the individual rankings, effectively marginalizing out the order biases.
The researchers provide theoretical guarantees, showing that their method converges to the true ranking in the presence of random perturbations.
Empirically, the researchers evaluate their approach on five list-ranking datasets, including sorting and passage reranking tasks. They find that their permutation self-consistency method can improve ranking scores by up to 7-18% for GPT-3.5 and 8-16% for LLaMA v2 (70B), outperforming previous state-of-the-art methods.
Generating Diverse Criteria to Fly to Improve Point-Level Consistency and Beyond Self-Consistency: Ensemble Reasoning Boosts Consistency are two other techniques that aim to improve the consistency and reliability of LLM outputs.
Critical Analysis
The researchers acknowledge several caveats and limitations of their work. First, the permutation self-consistency approach relies on the LLM's ability to produce consistent rankings across multiple shuffled prompts, which may not always be the case. Additionally, the method may be computationally expensive, as it requires running the LLM multiple times for each input.
Furthermore, the researchers only evaluate their approach on a limited set of list-ranking tasks. It would be valuable to see how the method performs on a wider range of applications, particularly in domains where positional bias is known to be a significant issue.
Another potential concern is the reliance on the LLM's own outputs as the ground truth for ranking. If the LLM has inherent biases or inconsistencies, the permutation self-consistency method may not be able to fully correct for them.
Towards Logically Consistent Language Models via Probabilistic is a related paper that explores approaches for improving the logical consistency of LLM outputs, which could be a valuable complement to the work presented here.
Overall, the researchers have presented a novel and promising technique for addressing positional bias in LLMs, but further research and validation will be needed to fully assess its strengths, limitations, and broader applicability.
Conclusion
The researchers have proposed a method called "permutation self-consistency" to address the positional bias exhibited by large language models when performing listwise ranking tasks. By repeatedly shuffling the order of items in the prompt and aggregating the resulting rankings, the approach helps to neutralize the order-dependent biases of the LLM.
Empirical results on several list-ranking datasets show significant improvements over conventional inference, with gains of up to 7-18% for GPT-3.5 and 8-16% for LLaMA v2 (70B), surpassing previous state-of-the-art methods. This work represents an important step towards developing more robust and reliable language models, with potential applications in a wide range of domains that rely on ranking and ordering tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Found in the Middle: Permutation Self-Consistency Improves Listwise Ranking in Large Language Models
Raphael Tang, Xinyu Zhang, Xueguang Ma, Jimmy Lin, Ferhan Ture
Large language models (LLMs) exhibit positional bias in how they use context, which especially complicates listwise ranking. To address this, we propose permutation self-consistency, a form of self-consistency over ranking list outputs of black-box LLMs. Our key idea is to marginalize out different list orders in the prompt to produce an order-independent ranking with less positional bias. First, given some input prompt, we repeatedly shuffle the list in the prompt and pass it through the LLM while holding the instructions the same. Next, we aggregate the resulting sample of rankings by computing the central ranking closest in distance to all of them, marginalizing out prompt order biases in the process. Theoretically, we prove the robustness of our method, showing convergence to the true ranking in the presence of random perturbations. Empirically, on five list-ranking datasets in sorting and passage reranking, our approach improves scores from conventional inference by up to 7-18% for GPT-3.5 and 8-16% for LLaMA v2 (70B), surpassing the previous state of the art in passage reranking. Our code is at https://github.com/castorini/perm-sc.
Read more4/23/2024
0
LLM-RankFusion: Mitigating Intrinsic Inconsistency in LLM-based Ranking
Yifan Zeng, Ojas Tendolkar, Raymond Baartmans, Qingyun Wu, Huazheng Wang, Lizhong Chen
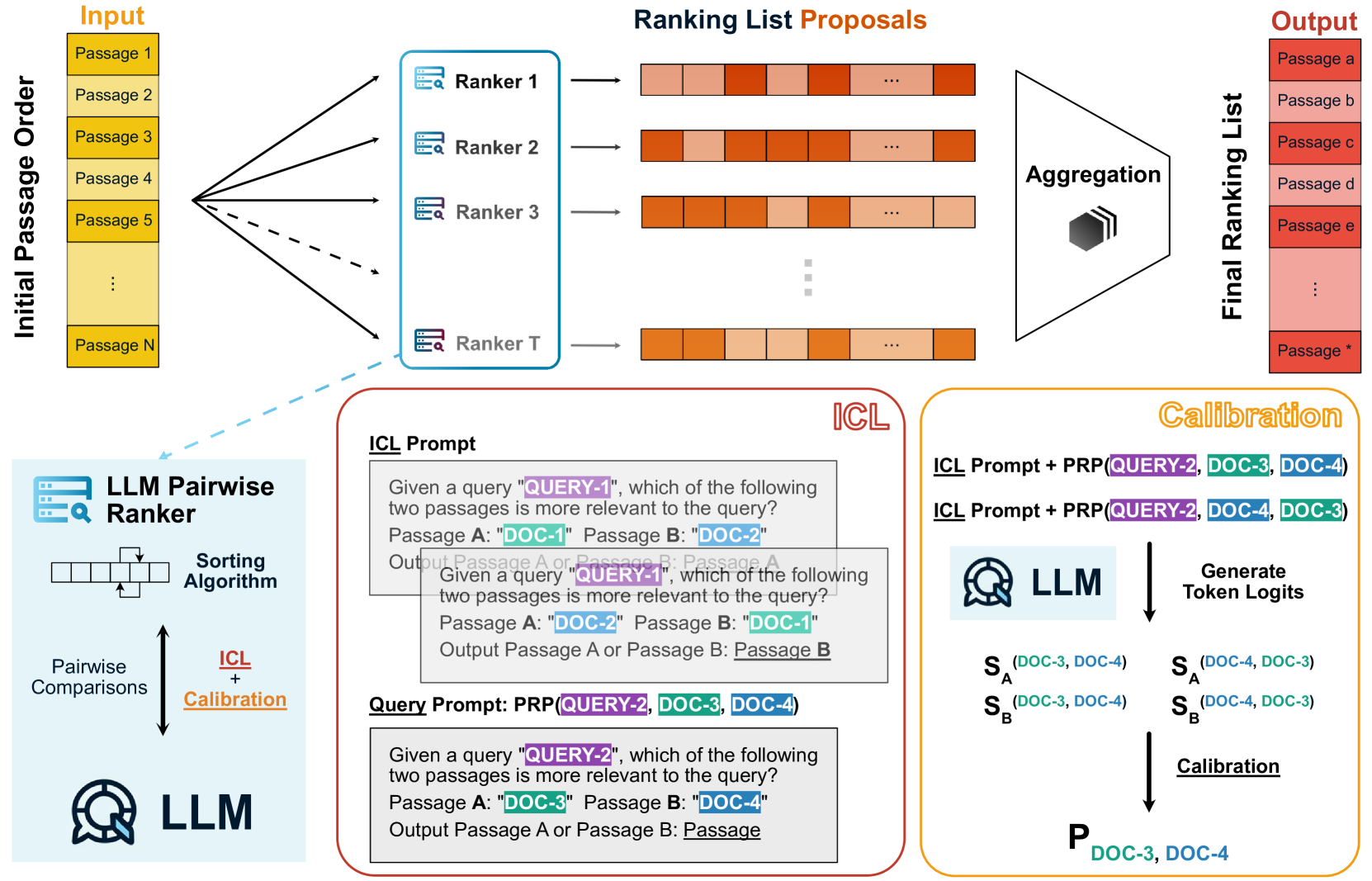
Ranking passages by prompting a large language model (LLM) can achieve promising performance in modern information retrieval (IR) systems. A common approach is to sort the ranking list by prompting LLMs for pairwise comparison. However, sorting-based methods require consistent comparisons to correctly sort the passages, which we show that LLMs often violate. We identify two kinds of intrinsic inconsistency in LLM-based pairwise comparisons: order inconsistency which leads to conflicting results when switching the passage order, and transitive inconsistency which leads to non-transitive triads among all preference pairs. In this paper, we propose LLM-RankFusion, an LLM-based ranking framework that mitigates these inconsistencies and produces a robust ranking list. LLM-RankFusion mitigates order inconsistency using in-context learning (ICL) to demonstrate order-agnostic comparisons and calibration to estimate the underlying preference probability between two passages. We then address transitive inconsistency by aggregating the ranking results from multiple rankers. In our experiments, we empirically show that LLM-RankFusion can significantly reduce inconsistent pairwise comparison results, and improve the ranking quality by making the final ranking list more robust.
Read more6/4/2024

0
Set-Based Prompting: Provably Solving the Language Model Order Dependency Problem
Reid McIlroy-Young, Katrina Brown, Conlan Olson, Linjun Zhang, Cynthia Dwork
The development of generative language models that can create long and coherent textual outputs via autoregression has lead to a proliferation of uses and a corresponding sweep of analyses as researches work to determine the limitations of this new paradigm. Unlike humans, these 'Large Language Models' (LLMs) are highly sensitive to small changes in their inputs, leading to unwanted inconsistency in their behavior. One problematic inconsistency when LLMs are used to answer multiple-choice questions or analyze multiple inputs is order dependency: the output of an LLM can (and often does) change significantly when sub-sequences are swapped, despite both orderings being semantically identical. In this paper we present Set-Based Prompting, a technique that guarantees the output of an LLM will not have order dependence on a specified set of sub-sequences. We show that this method provably eliminates order dependency, and that it can be applied to any transformer-based LLM to enable text generation that is unaffected by re-orderings. Delving into the implications of our method, we show that, despite our inputs being out of distribution, the impact on expected accuracy is small, where the expectation is over the order of uniformly chosen shuffling of the candidate responses, and usually significantly less in practice. Thus, Set-Based Prompting can be used as a 'dropped-in' method on fully trained models. Finally, we discuss how our method's success suggests that other strong guarantees can be obtained on LLM performance via modifying the input representations.
Read more6/13/2024
💬
0
Prediction-Powered Ranking of Large Language Models
Ivi Chatzi, Eleni Straitouri, Suhas Thejaswi, Manuel Gomez Rodriguez
Large language models are often ranked according to their level of alignment with human preferences -- a model is better than other models if its outputs are more frequently preferred by humans. One of the popular ways to elicit human preferences utilizes pairwise comparisons between the outputs provided by different models to the same inputs. However, since gathering pairwise comparisons by humans is costly and time-consuming, it has become a common practice to gather pairwise comparisons by a strong large language model -- a model strongly aligned with human preferences. Surprisingly, practitioners cannot currently measure the uncertainty that any mismatch between human and model preferences may introduce in the constructed rankings. In this work, we develop a statistical framework to bridge this gap. Given a (small) set of pairwise comparisons by humans and a large set of pairwise comparisons by a model, our framework provides a rank-set -- a set of possible ranking positions -- for each of the models under comparison. Moreover, it guarantees that, with a probability greater than or equal to a user-specified value, the rank-sets cover the true ranking consistent with the distribution of human pairwise preferences asymptotically. Using pairwise comparisons made by humans in the LMSYS Chatbot Arena platform and pairwise comparisons made by three strong large language models, we empirically demonstrate the effectivity of our framework and show that the rank-sets constructed using only pairwise comparisons by the strong large language models are often inconsistent with (the distribution of) human pairwise preferences.
Read more5/24/2024