A Framework for Fine-Tuning LLMs using Heterogeneous Feedback

0

Sign in to get full access
Overview
- This paper presents a framework for fine-tuning large language models (LLMs) using heterogeneous feedback.
- The proposed framework leverages various feedback sources, including reward signals, preferences, and demonstrations, to better align LLMs with desired behaviors.
- The authors demonstrate the effectiveness of their approach through experiments on several tasks, showing improvements over traditional fine-tuning methods.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text, but they can sometimes produce undesirable or biased outputs. To address this, the researchers developed a framework for fine-tuning LLMs using heterogeneous feedback.
The key idea is to provide the LLM with multiple types of feedback, such as:
- Reward signals: Positive or negative feedback indicating whether the model's output is desirable.
- Preferences: Indications of which outputs the user prefers.
- Demonstrations: Examples of the desired behavior the model should learn.
By combining these diverse feedback sources, the researchers found they could better align the LLM's behavior with the user's intentions, leading to more reliable and useful language model outputs.
The framework they propose is designed to be general and flexible, allowing it to be applied to a wide range of tasks and use cases. Through experiments, they show that their approach outperforms traditional fine-tuning methods, suggesting it could be a valuable tool for improving the safety and reliability of large language models.
Technical Explanation
The core of the researchers' framework is a novel fine-tuning algorithm that can incorporate diverse feedback sources. This includes:
- Reward signals: The model is trained to maximize a reward function that encodes the desired behavior.
- Preferences: The model learns to generate outputs that match user preferences, expressed as rankings or comparisons between model outputs.
- Demonstrations: The model is trained to imitate desired behaviors, expressed through examples of correct outputs.
The authors combine these feedback sources into a unified optimization objective, allowing the model to learn from the complementary information provided by each type of feedback.
To evaluate their approach, the researchers conducted experiments on several tasks, including text generation, question answering, and dialogue. They compared their framework to traditional fine-tuning methods and found that it led to significant improvements in the models' alignment with the desired behaviors.
Critical Analysis
The researchers acknowledge several limitations and caveats in their work:
- The effectiveness of the framework may depend on the quality and availability of the various feedback sources, which can be challenging to obtain in practice.
- The proposed approach increases the complexity of the fine-tuning process, which could make it more computationally expensive or difficult to implement.
- The paper does not provide a deep analysis of the tradeoffs between the different feedback modalities or how to best combine them for specific tasks or use cases.
Additionally, one could question whether the proposed framework is truly generalizable or if it may be better suited for certain types of tasks or feedback sources. Further research and experimentation would be needed to fully understand the strengths, weaknesses, and broader applicability of this approach.
Conclusion
This paper presents a promising framework for fine-tuning LLMs using heterogeneous feedback, which could help improve the safety, reliability, and alignment of these powerful language models. The authors demonstrate the effectiveness of their approach through empirical evaluations, but also acknowledge several limitations that warrant further investigation. Overall, this research represents an important step towards developing more robust and trustworthy large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Framework for Fine-Tuning LLMs using Heterogeneous Feedback
Ryan Aponte (Carnegie Mellon University), Ryan A. Rossi (Adobe Research), Shunan Guo (Adobe Research), Franck Dernoncourt (Adobe Research), Tong Yu (Adobe Research), Xiang Chen (Adobe Research), Subrata Mitra (Adobe Research), Nedim Lipka (Adobe Research)
Large language models (LLMs) have been applied to a wide range of tasks, including text summarization, web navigation, and chatbots. They have benefitted from supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) following an unsupervised pretraining. These datasets can be difficult to collect, limited in scope, and vary in sample quality. Additionally, datasets can vary extensively in supervision format, from numerical to binary as well as multi-dimensional with many different values. We present a framework for fine-tuning LLMs using heterogeneous feedback, which has two main components. First, we combine the heterogeneous feedback data into a single supervision format, compatible with methods like SFT and RLHF. Next, given this unified feedback dataset, we extract a high-quality and diverse subset to obtain performance increases potentially exceeding the full dataset. We conduct extensive experiments to understand the effectiveness of these techniques for incorporating heterogeneous feedback, and demonstrate improvements from using a high-quality and diverse subset of the data. We find that our framework is able to improve models in multiple areas simultaneously, such as in instruction following and bias reduction.
Read more8/7/2024
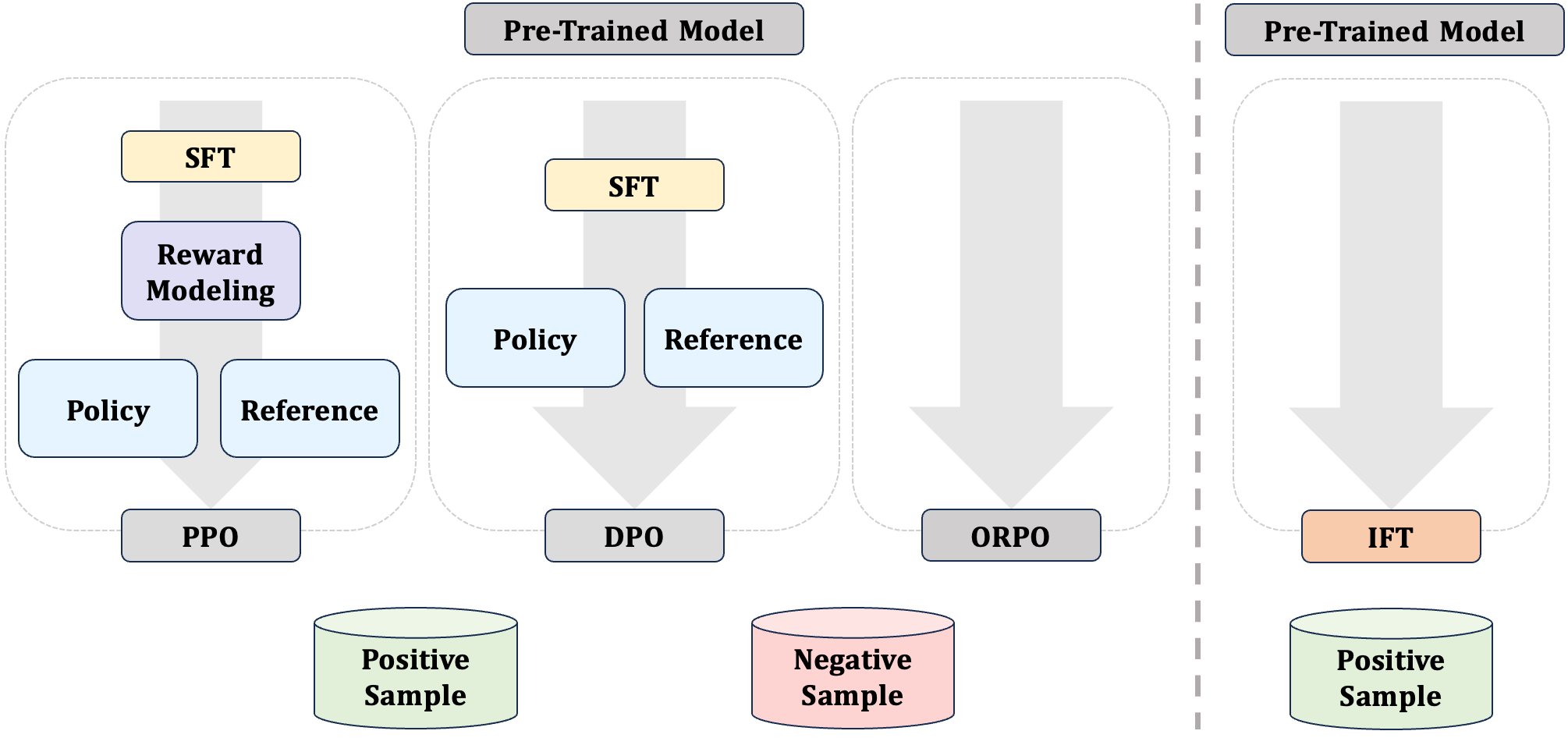
0
Intuitive Fine-Tuning: Towards Unifying SFT and RLHF into a Single Process
Ermo Hua, Biqing Qi, Kaiyan Zhang, Yue Yu, Ning Ding, Xingtai Lv, Kai Tian, Bowen Zhou
Supervised Fine-Tuning (SFT) and Preference Optimization (PO) are two fundamental processes for enhancing the capabilities of Language Models (LMs) post pre-training, aligning them better with human preferences. Although SFT advances in training efficiency, PO delivers better alignment, thus they are often combined. However, common practices simply apply them sequentially without integrating their optimization objectives, ignoring the opportunities to bridge their paradigm gap and take the strengths from both. To obtain a unified understanding, we interpret SFT and PO with two sub-processes -- Preference Estimation and Transition Optimization -- defined at token level within the Markov Decision Process (MDP) framework. This modeling shows that SFT is only a specialized case of PO with inferior estimation and optimization. PO evaluates the quality of model's entire generated answer, whereas SFT only scores predicted tokens based on preceding tokens from target answers. Therefore, SFT overestimates the ability of model, leading to inferior optimization. Building on this view, we introduce Intuitive Fine-Tuning (IFT) to integrate SFT and Preference Optimization into a single process. IFT captures LMs' intuitive sense of the entire answers through a temporal residual connection, but it solely relies on a single policy and the same volume of non-preference-labeled data as SFT. Our experiments show that IFT performs comparably or even superiorly to sequential recipes of SFT and some typical Preference Optimization methods across several tasks, particularly those requires generation, reasoning, and fact-following abilities. An explainable Frozen Lake game further validates the effectiveness of IFT for getting competitive policy.
Read more5/29/2024

0
Investigating Automatic Scoring and Feedback using Large Language Models
Gloria Ashiya Katuka, Alexander Gain, Yen-Yun Yu
Automatic grading and feedback have been long studied using traditional machine learning and deep learning techniques using language models. With the recent accessibility to high performing large language models (LLMs) like LLaMA-2, there is an opportunity to investigate the use of these LLMs for automatic grading and feedback generation. Despite the increase in performance, LLMs require significant computational resources for fine-tuning and additional specific adjustments to enhance their performance for such tasks. To address these issues, Parameter Efficient Fine-tuning (PEFT) methods, such as LoRA and QLoRA, have been adopted to decrease memory and computational requirements in model fine-tuning. This paper explores the efficacy of PEFT-based quantized models, employing classification or regression head, to fine-tune LLMs for automatically assigning continuous numerical grades to short answers and essays, as well as generating corresponding feedback. We conducted experiments on both proprietary and open-source datasets for our tasks. The results show that prediction of grade scores via finetuned LLMs are highly accurate, achieving less than 3% error in grade percentage on average. For providing graded feedback fine-tuned 4-bit quantized LLaMA-2 13B models outperform competitive base models and achieve high similarity with subject matter expert feedback in terms of high BLEU and ROUGE scores and qualitatively in terms of feedback. The findings from this study provide important insights into the impacts of the emerging capabilities of using quantization approaches to fine-tune LLMs for various downstream tasks, such as automatic short answer scoring and feedback generation at comparatively lower costs and latency.
Read more5/2/2024

0
Personalized Language Modeling from Personalized Human Feedback
Xinyu Li, Zachary C. Lipton, Liu Leqi
Reinforcement Learning from Human Feedback (RLHF) is commonly used to fine-tune large language models to better align with human preferences. However, the underlying premise of algorithms developed under this framework can be problematic when user preferences encoded in human feedback are diverse. In this work, we aim to address this problem by developing methods for building personalized language models. We first formally introduce the task of learning from personalized human feedback and explain why vanilla RLHF can be ineffective in this context. We then propose a general Personalized-RLHF (P-RLHF) framework, including a user model that maps user information to user representations and can flexibly encode our assumptions on user preferences. We develop new learning objectives to perform personalized Direct Preference Optimization that jointly learns a user model and a personalized language model. We demonstrate the efficacy of our proposed method through (1) a synthetic task where we fine-tune a GPT-J 6B model to align with users with conflicting preferences on generation length; and (2) an instruction following task where we fine-tune a Tulu-7B model to generate responses for users with diverse preferences on the style of responses. In both cases, our learned models can generate personalized responses that are better aligned with the preferences of individual users.
Read more7/9/2024