GitHub Copilot: the perfect Code compLeeter?

0
Sign in to get full access
Overview
- Evaluates the performance of GitHub Copilot, an AI-powered code generation tool, on programming exercises
- Compares Copilot's solutions to those written by humans on LeetCode, a popular coding challenge platform
- Explores the capabilities and limitations of Copilot in completing coding tasks
Plain English Explanation
GitHub Copilot is an AI-powered tool that can generate code to help programmers with their work. The researchers in this paper wanted to see how well Copilot performs on programming exercises, compared to solutions written by human programmers.
They tested Copilot on a set of coding challenges from LeetCode, a website that hosts programming problems for people to practice. The researchers had Copilot attempt to solve these challenges and then compared Copilot's solutions to the ones written by humans.
The key findings were that Copilot was able to generate partially correct solutions for many of the challenges, but it struggled to produce fully correct and complete code. Copilot also had trouble with more complex programming tasks that required a deeper understanding of algorithms and problem-solving strategies.
These results suggest that while Copilot can be a useful tool for programmers, it is not a perfect "code completer" and still has limitations in its ability to understand and solve complex programming problems. The researchers recommend further development and testing to improve Copilot's capabilities.
Technical Explanation
The researchers conducted a series of experiments to evaluate the performance of GitHub Copilot on programming exercises from the LeetCode platform. They selected a diverse set of 100 LeetCode problems covering various difficulty levels and problem types.
For each problem, the researchers provided the problem statement and any starter code to Copilot and asked it to generate a complete solution. They then compared Copilot's solutions to the reference solutions written by human programmers, using metrics such as code correctness, completeness, and efficiency.
The results showed that Copilot was able to generate partially correct solutions for a majority of the problems, but it struggled to produce fully correct and complete code, especially for more complex challenges. Copilot also had difficulty with problems that required a deeper understanding of algorithms and problem-solving strategies, as well as tasks that involved complex data structures or edge cases.
The researchers also conducted a qualitative analysis, interviewing developers to understand their perspectives on the use of Copilot in their programming workflows. The developers generally found Copilot to be a useful tool for tasks like boilerplate code generation and syntax completion, but they were cautious about relying on Copilot for more complex programming tasks without careful review and validation.
Critical Analysis
The researchers acknowledge several limitations of their study, including the relatively small sample size of LeetCode problems and the potential for bias in the human-written reference solutions. They also note that Copilot's performance may vary depending on the specific problem domain and the quality of the prompts provided to the model.
Additionally, the researchers did not explore the potential impact of Copilot on developer productivity, code quality, or other real-world factors, which could be important considerations for the adoption of such AI-powered tools in software development workflows. Further research is needed to better understand the role of AI-generated code in the software development process and its implications for developers, teams, and organizations.
Conclusion
The findings of this study suggest that while GitHub Copilot can be a valuable tool for programmers, it is not a perfect "code completer" and has limitations in its ability to solve complex programming problems. Copilot can generate partially correct solutions, but it struggles with more advanced algorithmic and problem-solving tasks.
These results highlight the need for continued development and testing of AI-powered code generation tools to improve their capabilities and reliability. As such tools become more prevalent, it will be important for developers and organizations to carefully evaluate their use and integrate them into their workflows in a way that ensures the quality and correctness of the generated code.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GitHub Copilot: the perfect Code compLeeter?
Ilja Sirov{s}, Dave Singel'ee, Bart Preneel
This paper aims to evaluate GitHub Copilot's generated code quality based on the LeetCode problem set using a custom automated framework. We evaluate the results of Copilot for 4 programming languages: Java, C++, Python3 and Rust. We aim to evaluate Copilot's reliability in the code generation stage, the correctness of the generated code and its dependency on the programming language, problem's difficulty level and problem's topic. In addition to that, we evaluate code's time and memory efficiency and compare it to the average human results. In total, we generate solutions for 1760 problems for each programming language and evaluate all the Copilot's suggestions for each problem, resulting in over 50000 submissions to LeetCode spread over a 2-month period. We found that Copilot successfully solved most of the problems. However, Copilot was rather more successful in generating code in Java and C++ than in Python3 and Rust. Moreover, in case of Python3 Copilot proved to be rather unreliable in the code generation phase. We also discovered that Copilot's top-ranked suggestions are not always the best. In addition, we analysed how the topic of the problem impacts the correctness rate. Finally, based on statistics information from LeetCode, we can conclude that Copilot generates more efficient code than an average human.
Read more6/18/2024
🏅
0
Transforming Software Development: Evaluating the Efficiency and Challenges of GitHub Copilot in Real-World Projects
Ruchika Pandey, Prabhat Singh, Raymond Wei, Shaila Shankar
Generative AI technologies promise to transform the product development lifecycle. This study evaluates the efficiency gains, areas for improvement, and emerging challenges of using GitHub Copilot, an AI-powered coding assistant. We identified 15 software development tasks and assessed Copilot's benefits through real-world projects on large proprietary code bases. Our findings indicate significant reductions in developer toil, with up to 50% time saved in code documentation and autocompletion, and 30-40% in repetitive coding tasks, unit test generation, debugging, and pair programming. However, Copilot struggles with complex tasks, large functions, multiple files, and proprietary contexts, particularly with C/C++ code. We project a 33-36% time reduction for coding-related tasks in a cloud-first software development lifecycle. This study aims to quantify productivity improvements, identify underperforming scenarios, examine practical benefits and challenges, investigate performance variations across programming languages, and discuss emerging issues related to code quality, security, and developer experience.
Read more6/27/2024
2
Examination of Code generated by Large Language Models
Robin Beer, Alexander Feix, Tim Guttzeit, Tamara Muras, Vincent Muller, Maurice Rauscher, Florian Schaffler, Welf Lowe
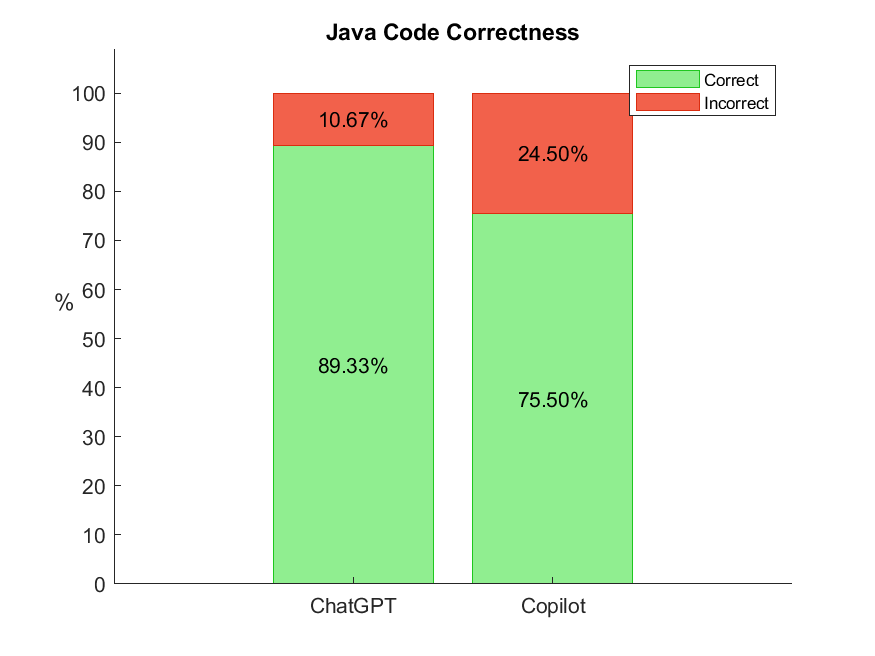
Large language models (LLMs), such as ChatGPT and Copilot, are transforming software development by automating code generation and, arguably, enable rapid prototyping, support education, and boost productivity. Therefore, correctness and quality of the generated code should be on par with manually written code. To assess the current state of LLMs in generating correct code of high quality, we conducted controlled experiments with ChatGPT and Copilot: we let the LLMs generate simple algorithms in Java and Python along with the corresponding unit tests and assessed the correctness and the quality (coverage) of the generated (test) codes. We observed significant differences between the LLMs, between the languages, between algorithm and test codes, and over time. The present paper reports these results together with the experimental methods allowing repeated and comparable assessments for more algorithms, languages, and LLMs over time.
Read more8/30/2024
📉
1
Reading Between the Lines: Modeling User Behavior and Costs in AI-Assisted Programming
Hussein Mozannar, Gagan Bansal, Adam Fourney, Eric Horvitz
Code-recommendation systems, such as Copilot and CodeWhisperer, have the potential to improve programmer productivity by suggesting and auto-completing code. However, to fully realize their potential, we must understand how programmers interact with these systems and identify ways to improve that interaction. To seek insights about human-AI collaboration with code recommendations systems, we studied GitHub Copilot, a code-recommendation system used by millions of programmers daily. We developed CUPS, a taxonomy of common programmer activities when interacting with Copilot. Our study of 21 programmers, who completed coding tasks and retrospectively labeled their sessions with CUPS, showed that CUPS can help us understand how programmers interact with code-recommendation systems, revealing inefficiencies and time costs. Our insights reveal how programmers interact with Copilot and motivate new interface designs and metrics.
Read more4/23/2024