Global Benchmark Database

0
🐍
Sign in to get full access
Overview
- Presents a global benchmark database for evaluating AI systems across a wide range of tasks and domains
- Includes benchmarks for 4D prediction, 3D instruction tuning, dynamic environments, GNN performance, and AI competitions
- Aims to provide a comprehensive and standardized set of tools for benchmarking and development of AI models
Plain English Explanation
The provided research paper introduces a global benchmark database for evaluating artificial intelligence (AI) systems. This database includes a variety of benchmarks covering different areas of AI, such as 4D prediction, 3D instruction tuning, dynamic environment modeling, GNN performance, and AI competitions. The goal of this database is to provide a comprehensive and standardized set of tools for benchmarking and developing AI models across a wide range of tasks and domains.
Technical Explanation
The research paper presents a global benchmark database that aims to facilitate the evaluation of AI systems across a diverse set of tasks and domains. The database includes several key components:
-
Data Model and Queries: The paper defines a data model and a set of queries that can be used to assess the performance of AI systems on various tasks, such as 4D prediction, 3D instruction tuning, dynamic environment modeling, and GNN performance.
-
Applications: The paper showcases several applications of the benchmark database, including 4D prediction, 3D instruction tuning, dynamic environment modeling, GNN performance evaluation, and AI competitions. Each of these applications is supported by a specific set of benchmarks and datasets.
-
Evaluation Metrics: The paper introduces a range of evaluation metrics that can be used to assess the performance of AI models on the different benchmarks. These metrics include traditional measures like accuracy, as well as more complex metrics tailored to the specific tasks and domains.
-
Benchmark Generation: The paper describes the process of generating the benchmark datasets, which involves techniques such as clustering and data simulation. This ensures that the benchmarks are diverse, challenging, and representative of real-world scenarios.
Critical Analysis
The research paper presents a comprehensive and well-designed global benchmark database for AI systems. However, some potential limitations and areas for further research are worth considering:
-
Scalability and Computational Complexity: The benchmarks and datasets included in the database may pose significant computational challenges for some AI systems, particularly those with limited resources. Additional research may be needed to address the scalability and computational complexity of the benchmarks.
-
Benchmark Diversity and Relevance: While the database covers a wide range of tasks and domains, it is essential to ensure that the benchmarks remain relevant and representative of real-world challenges. Ongoing curation and updates to the database may be necessary to keep pace with the rapidly evolving field of AI.
-
Benchmark Fairness and Bias: As with any benchmarking system, there is a risk of introducing unintended biases or fairness issues. It is important to continuously evaluate the benchmarks for potential biases and to address them as they arise.
-
Practical Applicability: While the research paper focuses on the technical aspects of the benchmark database, it is crucial to consider the practical applicability of the benchmarks for AI practitioners and researchers. Efforts to bridge the gap between the theoretical framework and real-world deployment may be valuable.
Conclusion
The global benchmark database presented in this research paper provides a comprehensive and standardized set of tools for evaluating AI systems across a wide range of tasks and domains. By including benchmarks for 4D prediction, 3D instruction tuning, dynamic environment modeling, GNN performance, and AI competitions, the database aims to facilitate the development and assessment of more robust and capable AI models. While the research paper highlights the technical details of the database, ongoing efforts to address scalability, benchmark relevance, fairness, and practical applicability will be crucial for the widespread adoption and impact of this valuable resource.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
0
Global Benchmark Database
Markus Iser, Christoph Jabs
This paper presents Global Benchmark Database (GBD), a comprehensive suite of tools for provisioning and sustainably maintaining benchmark instances and their metadata. The availability of benchmark metadata is essential for many tasks in empirical research, e.g., for the data-driven compilation of benchmarks, the domain-specific analysis of runtime experiments, or the instance-specific selection of solvers. In this paper, we introduce the data model of GBD as well as its interfaces and provide examples of how to interact with them. We also demonstrate the integration of custom data sources and explain how to extend GBD with additional problem domains, instance formats and feature extractors.
Read more6/28/2024
🤖
0
4DBInfer: A 4D Benchmarking Toolbox for Graph-Centric Predictive Modeling on Relational DBs
Minjie Wang, Quan Gan, David Wipf, Zhenkun Cai, Ning Li, Jianheng Tang, Yanlin Zhang, Zizhao Zhang, Zunyao Mao, Yakun Song, Yanbo Wang, Jiahang Li, Han Zhang, Guang Yang, Xiao Qin, Chuan Lei, Muhan Zhang, Weinan Zhang, Christos Faloutsos, Zheng Zhang
Although RDBs store vast amounts of rich, informative data spread across interconnected tables, the progress of predictive machine learning models as applied to such tasks arguably falls well behind advances in other domains such as computer vision or natural language processing. This deficit stems, at least in part, from the lack of established/public RDB benchmarks as needed for training and evaluation purposes. As a result, related model development thus far often defaults to tabular approaches trained on ubiquitous single-table benchmarks, or on the relational side, graph-based alternatives such as GNNs applied to a completely different set of graph datasets devoid of tabular characteristics. To more precisely target RDBs lying at the nexus of these two complementary regimes, we explore a broad class of baseline models predicated on: (i) converting multi-table datasets into graphs using various strategies equipped with efficient subsampling, while preserving tabular characteristics; and (ii) trainable models with well-matched inductive biases that output predictions based on these input subgraphs. Then, to address the dearth of suitable public benchmarks and reduce siloed comparisons, we assemble a diverse collection of (i) large-scale RDB datasets and (ii) coincident predictive tasks. From a delivery standpoint, we operationalize the above four dimensions (4D) of exploration within a unified, scalable open-source toolbox called 4DBInfer. We conclude by presenting evaluations using 4DBInfer, the results of which highlight the importance of considering each such dimension in the design of RDB predictive models, as well as the limitations of more naive approaches such as simply joining adjacent tables. Our source code is released at https://github.com/awslabs/multi-table-benchmark .
Read more4/30/2024

0
GenBench: A Benchmarking Suite for Systematic Evaluation of Genomic Foundation Models
Zicheng Liu, Jiahui Li, Siyuan Li, Zelin Zang, Cheng Tan, Yufei Huang, Yajing Bai, Stan Z. Li
The Genomic Foundation Model (GFM) paradigm is expected to facilitate the extraction of generalizable representations from massive genomic data, thereby enabling their application across a spectrum of downstream applications. Despite advancements, a lack of evaluation framework makes it difficult to ensure equitable assessment due to experimental settings, model intricacy, benchmark datasets, and reproducibility challenges. In the absence of standardization, comparative analyses risk becoming biased and unreliable. To surmount this impasse, we introduce GenBench, a comprehensive benchmarking suite specifically tailored for evaluating the efficacy of Genomic Foundation Models. GenBench offers a modular and expandable framework that encapsulates a variety of state-of-the-art methodologies. Through systematic evaluations of datasets spanning diverse biological domains with a particular emphasis on both short-range and long-range genomic tasks, firstly including the three most important DNA tasks covering Coding Region, Non-Coding Region, Genome Structure, etc. Moreover, We provide a nuanced analysis of the interplay between model architecture and dataset characteristics on task-specific performance. Our findings reveal an interesting observation: independent of the number of parameters, the discernible difference in preference between the attention-based and convolution-based models on short- and long-range tasks may provide insights into the future design of GFM.
Read more6/6/2024
0
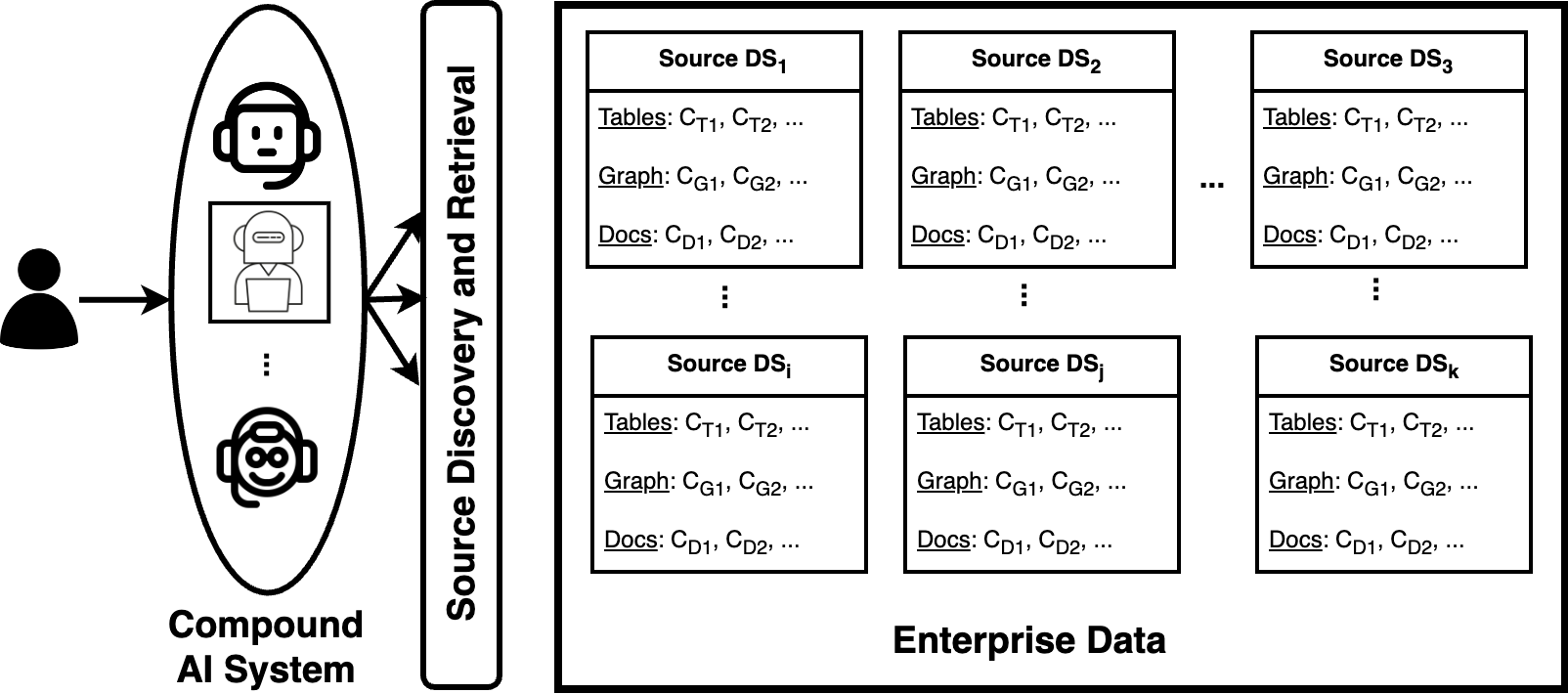
CMDBench: A Benchmark for Coarse-to-fine Multimodal Data Discovery in Compound AI Systems
Yanlin Feng, Sajjadur Rahman, Aaron Feng, Vincent Chen, Eser Kandogan
Compound AI systems (CASs) that employ LLMs as agents to accomplish knowledge-intensive tasks via interactions with tools and data retrievers have garnered significant interest within database and AI communities. While these systems have the potential to supplement typical analysis workflows of data analysts in enterprise data platforms, unfortunately, CASs are subject to the same data discovery challenges that analysts have encountered over the years -- silos of multimodal data sources, created across teams and departments within an organization, make it difficult to identify appropriate data sources for accomplishing the task at hand. Existing data discovery benchmarks do not model such multimodality and multiplicity of data sources. Moreover, benchmarks of CASs prioritize only evaluating end-to-end task performance. To catalyze research on evaluating the data discovery performance of multimodal data retrievers in CASs within a real-world setting, we propose CMDBench, a benchmark modeling the complexity of enterprise data platforms. We adapt existing datasets and benchmarks in open-domain -- from question answering and complex reasoning tasks to natural language querying over structured data -- to evaluate coarse- and fine-grained data discovery and task execution performance. Our experiments reveal the impact of data retriever design on downstream task performance -- a 46% drop in task accuracy on average -- across various modalities, data sources, and task difficulty. The results indicate the need to develop optimization strategies to identify appropriate LLM agents and retrievers for efficient execution of CASs over enterprise data.
Read more6/4/2024