Harm Amplification in Text-to-Image Models

0

Sign in to get full access
Overview
- The paper explores the potential for text-to-image (T2I) models to amplify harmful content, such as stereotypes, biases, and other problematic imagery.
- The authors investigate how T2I models can inadvertently generate harmful outputs when prompted with certain text inputs.
- They propose frameworks for mitigating these risks and highlight the importance of sociotechnical safety considerations in the development of T2I systems.
Plain English Explanation
The paper looks at how text-to-image (T2I) models, which can generate images based on text prompts, might end up creating harmful or biased content. These models are becoming more advanced, but they could potentially amplify problems like stereotypes or inappropriate imagery if not properly designed and monitored.
The researchers explore ways that T2I models could go wrong, such as generating biased or offensive images when given certain text inputs. They suggest frameworks for trying to prevent these issues, recognizing that the safety and social impact of these technologies need to be carefully considered as they become more widespread.
Overall, the paper highlights the importance of understanding the potential downsides of T2I models and taking steps to mitigate the risks, rather than just focusing on the impressive capabilities of these systems. By being proactive about potential harms, the authors hope to guide the responsible development of this emerging technology.
Technical Explanation
The paper examines the potential for text-to-image (T2I) models to amplify harmful content. The authors investigate how these models can inadvertently generate problematic outputs, such as images reflecting stereotypes, biases, or other concerning content, when prompted with certain text inputs.
The researchers propose frameworks for mitigating these risks and highlight the importance of sociotechnical safety considerations in the development of T2I systems. They draw on existing work on bias in text-to-image generation and red-teaming methods to inform their analysis and proposed approaches.
Critical Analysis
The paper raises important concerns about the potential for T2I models to amplify harmful content, which is a critical issue as these technologies become more advanced and widely used. The authors provide a thoughtful exploration of the problem and propose frameworks for addressing it, which is a valuable contribution to the field.
However, the paper acknowledges that further research is needed to fully understand the scope and nature of these risks, as well as to develop more robust mitigation strategies. Additionally, the authors note that the challenges they describe are not unique to T2I models and may apply more broadly to other types of generative AI systems.
It would be helpful for the paper to delve deeper into specific case studies or examples of harm amplification in T2I models, as this could provide more concrete insights into the problem and potential solutions. Additionally, the critical analysis could be strengthened by considering alternative perspectives or potential counterarguments to the authors' proposals.
Conclusion
This paper highlights the importance of considering the potential for harm amplification in the development of text-to-image (T2I) models. The authors provide a detailed exploration of the problem and propose frameworks for mitigating these risks, recognizing the need for a sociotechnical approach that prioritizes safety and responsible innovation.
As T2I models continue to advance and become more widely used, it will be crucial for researchers, developers, and policymakers to proactively address the challenges outlined in this paper. By doing so, they can help ensure that the significant benefits of these technologies are not overshadowed by unintended negative consequences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Harm Amplification in Text-to-Image Models
Susan Hao, Renee Shelby, Yuchi Liu, Hansa Srinivasan, Mukul Bhutani, Burcu Karagol Ayan, Ryan Poplin, Shivani Poddar, Sarah Laszlo
Text-to-image (T2I) models have emerged as a significant advancement in generative AI; however, there exist safety concerns regarding their potential to produce harmful image outputs even when users input seemingly safe prompts. This phenomenon, where T2I models generate harmful representations that were not explicit in the input prompt, poses a potentially greater risk than adversarial prompts, leaving users unintentionally exposed to harms. Our paper addresses this issue by formalizing a definition for this phenomenon which we term harm amplification. We further contribute to the field by developing a framework of methodologies to quantify harm amplification in which we consider the harm of the model output in the context of user input. We then empirically examine how to apply these different methodologies to simulate real-world deployment scenarios including a quantification of disparate impacts across genders resulting from harm amplification. Together, our work aims to offer researchers tools to comprehensively address safety challenges in T2I systems and contribute to the responsible deployment of generative AI models.
Read more8/19/2024
0
Severity Controlled Text-to-Image Generative Model Bias Manipulation
Jordan Vice, Naveed Akhtar, Richard Hartley, Ajmal Mian
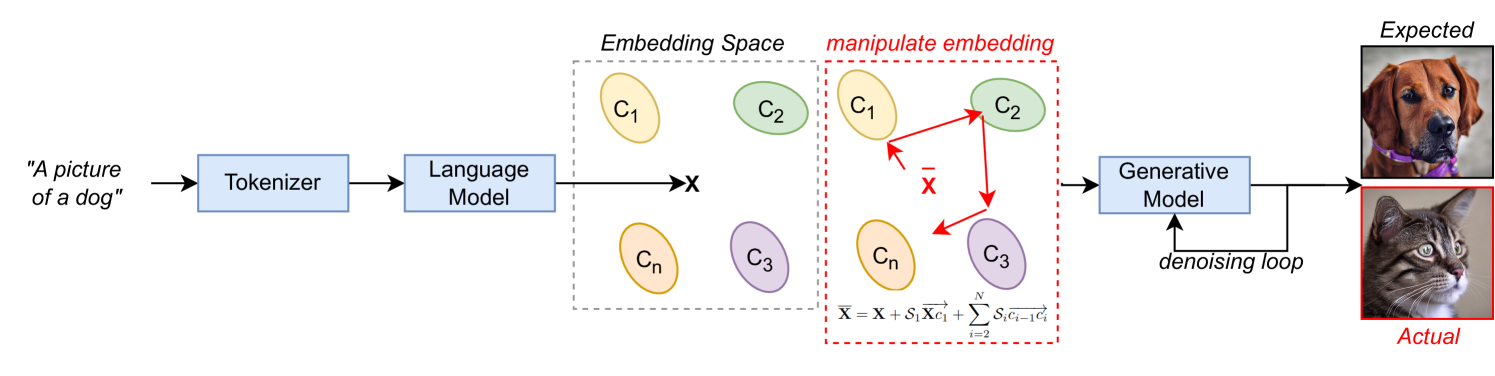
Text-to-image (T2I) generative models have gained increased popularity in the public domain. While boasting impressive user-guided generative abilities, their black-box nature exposes users to intentionally- and intrinsically-biased outputs. Bias manipulation (and mitigation) techniques typically rely on careful tuning of learning parameters and training data to adjust decision boundaries to influence model bias characteristics, which is often computationally demanding. We propose a dynamic and computationally efficient manipulation of T2I model biases by exploiting their rich language embedding spaces without model retraining. We show that leveraging foundational vector algebra allows for a convenient control over language model embeddings to shift T2I model outputs and control the distribution of generated classes. As a by-product, this control serves as a form of precise prompt engineering to generate images which are generally implausible using regular text prompts. We demonstrate a constructive application of our technique by balancing the frequency of social classes in generated images, effectively balancing class distributions across three social bias dimensions. We also highlight a negative implication of bias manipulation by framing our method as a backdoor attack with severity control using semantically-null input triggers, reporting up to 100% attack success rate. Key-words: Text-to-Image Models, Generative Models, Bias, Prompt Engineering, Backdoor Attacks
Read more9/18/2024
0
Exploring the Boundaries of Content Moderation in Text-to-Image Generation
Piera Riccio, Georgina Curto, Nuria Oliver
This paper analyzes the community safety guidelines of five text-to-image (T2I) generation platforms and audits five T2I models, focusing on prompts related to the representation of humans in areas that might lead to societal stigma. While current research primarily focuses on ensuring safety by restricting the generation of harmful content, our study offers a complementary perspective. We argue that the concept of safety is difficult to define and operationalize, reflected in a discrepancy between the officially published safety guidelines and the actual behavior of the T2I models, and leading at times to over-censorship. Our findings call for more transparency and an inclusive dialogue about the platforms' content moderation practices, bearing in mind their global cultural and social impact.
Read more9/27/2024

0
Adversarial Nibbler: An Open Red-Teaming Method for Identifying Diverse Harms in Text-to-Image Generation
Jessica Quaye, Alicia Parrish, Oana Inel, Charvi Rastogi, Hannah Rose Kirk, Minsuk Kahng, Erin van Liemt, Max Bartolo, Jess Tsang, Justin White, Nathan Clement, Rafael Mosquera, Juan Ciro, Vijay Janapa Reddi, Lora Aroyo
With the rise of text-to-image (T2I) generative AI models reaching wide audiences, it is critical to evaluate model robustness against non-obvious attacks to mitigate the generation of offensive images. By focusing on ``implicitly adversarial'' prompts (those that trigger T2I models to generate unsafe images for non-obvious reasons), we isolate a set of difficult safety issues that human creativity is well-suited to uncover. To this end, we built the Adversarial Nibbler Challenge, a red-teaming methodology for crowdsourcing a diverse set of implicitly adversarial prompts. We have assembled a suite of state-of-the-art T2I models, employed a simple user interface to identify and annotate harms, and engaged diverse populations to capture long-tail safety issues that may be overlooked in standard testing. The challenge is run in consecutive rounds to enable a sustained discovery and analysis of safety pitfalls in T2I models. In this paper, we present an in-depth account of our methodology, a systematic study of novel attack strategies and discussion of safety failures revealed by challenge participants. We also release a companion visualization tool for easy exploration and derivation of insights from the dataset. The first challenge round resulted in over 10k prompt-image pairs with machine annotations for safety. A subset of 1.5k samples contains rich human annotations of harm types and attack styles. We find that 14% of images that humans consider harmful are mislabeled as ``safe'' by machines. We have identified new attack strategies that highlight the complexity of ensuring T2I model robustness. Our findings emphasize the necessity of continual auditing and adaptation as new vulnerabilities emerge. We are confident that this work will enable proactive, iterative safety assessments and promote responsible development of T2I models.
Read more5/15/2024