The Hidden Space of Transformer Language Adapters

0
💬
Sign in to get full access
Overview
- This paper analyzes how "transformer language adapters" - small modules trained on top of a frozen language model - adapt the model's predictions to new target languages.
- The key findings are:
- The adapted predictions mostly evolve in the source language the model was trained on, while the target language becomes pronounced only in the very last layers.
- The adaptation process is gradual and distributed across layers, allowing small groups of adapters to be skipped without decreasing performance.
- Adapters operate on top of the model's frozen representation space, largely preserving its structure, rather than on an 'isolated' subspace.
Plain English Explanation
The paper looks at a technique called "transformer language adapters" that allows language models to be adapted to new languages. These adapters are small additional modules trained on top of an existing, frozen language model.
The main findings are that even when adapting a model to a new language, the original language the model was trained on still has a big influence on the adapted predictions, only fading away in the final layers of the model. The adaptation process happens gradually across the different layers of the model, so you can even skip some of the adapter modules without hurting the adaptation performance too much.
Importantly, the adapters don't create a completely separate subspace for the new language. Instead, they work within the model's existing representation space, mostly just tweaking and refining it rather than starting from scratch. This provides some insights into the constraints and structure of how language models adapt to new languages.
Technical Explanation
The paper investigates the inner workings of transformer language adapters, a technique for adapting language models to new target languages with minimal additional training.
Through experiments, the authors find that:
- The adapted model's predictions still mostly reflect the source language the model was originally trained on, only shifting towards the target language in the final layers.
- The adaptation process is gradual and distributed across layers, so small groups of adapters can be skipped without significantly impacting performance.
- The adapters operate on top of the model's existing high-dimensional representation space, mostly preserving its structure rather than creating a separate subspace for the new language.
These findings provide insights into the underlying constraints and mechanisms of how language models adapt to new languages, with practical implications for making the process more efficient.
Critical Analysis
The paper offers a valuable look under the hood of language model adaptation, but there are a few caveats to consider:
- The experiments were limited to a few language pairs, so the generalizability to a wider range of languages is unclear.
- The analysis focused on model outputs, but did not deeply examine the internal representations and how they evolve during adaptation.
- While the gradual, layer-wise adaptation is an interesting property, the authors don't explore how to best leverage this in practical applications.
Additional research could investigate adapter performance on more diverse language pairs, as well as undertake a more granular analysis of the changing internal representations. Exploring efficient techniques to selectively activate or prune adapters could also be a fruitful area for further study.
Conclusion
This paper provides an informative glimpse into the adaptation process of transformer language models to new target languages. The key insights are that the adapted models retain a strong influence from the source language, that the adaptation is a gradual, distributed process, and that it occurs within the model's existing high-dimensional representation space.
These findings have implications for making language model adaptation more efficient and controllable, potentially leading to more flexible and accessible multilingual AI systems. By understanding the underlying mechanisms, researchers can work towards unlocking the full potential of multilingual language models to serve an increasingly diverse global audience.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
The Hidden Space of Transformer Language Adapters
Jesujoba O. Alabi, Marius Mosbach, Matan Eyal, Dietrich Klakow, Mor Geva
We analyze the operation of transformer language adapters, which are small modules trained on top of a frozen language model to adapt its predictions to new target languages. We show that adapted predictions mostly evolve in the source language the model was trained on, while the target language becomes pronounced only in the very last layers of the model. Moreover, the adaptation process is gradual and distributed across layers, where it is possible to skip small groups of adapters without decreasing adaptation performance. Last, we show that adapters operate on top of the model's frozen representation space while largely preserving its structure, rather than on an 'isolated' subspace. Our findings provide a deeper view into the adaptation process of language models to new languages, showcasing the constraints imposed on it by the underlying model and introduces practical implications to enhance its efficiency.
Read more6/11/2024
2
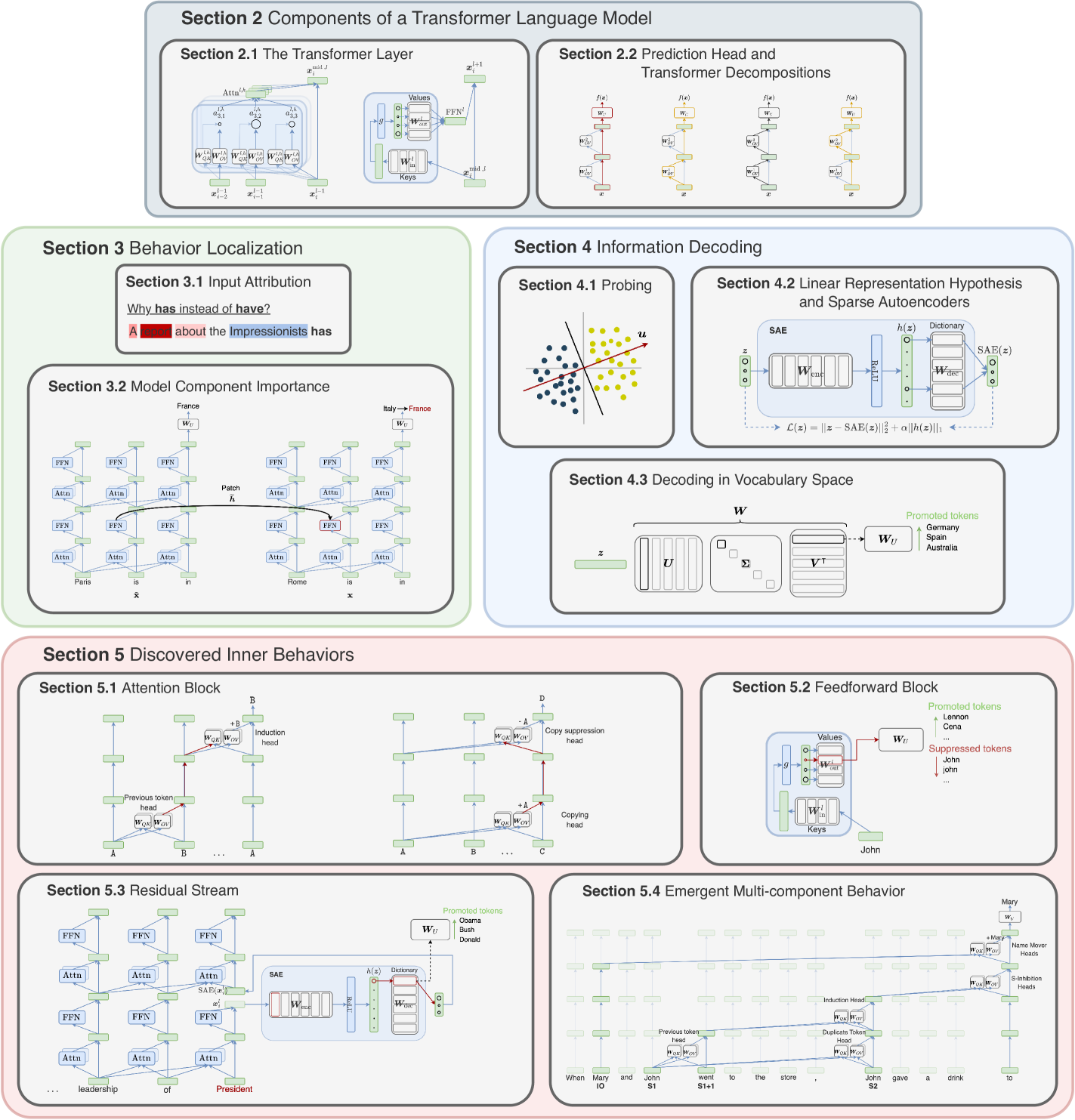
A Primer on the Inner Workings of Transformer-based Language Models
Javier Ferrando, Gabriele Sarti, Arianna Bisazza, Marta R. Costa-juss`a
The rapid progress of research aimed at interpreting the inner workings of advanced language models has highlighted a need for contextualizing the insights gained from years of work in this area. This primer provides a concise technical introduction to the current techniques used to interpret the inner workings of Transformer-based language models, focusing on the generative decoder-only architecture. We conclude by presenting a comprehensive overview of the known internal mechanisms implemented by these models, uncovering connections across popular approaches and active research directions in this area.
Read more5/3/2024

0
An Adapter-Based Unified Model for Multiple Spoken Language Processing Tasks
Varsha Suresh, Salah Ait-Mokhtar, Caroline Brun, Ioan Calapodescu
Self-supervised learning models have revolutionized the field of speech processing. However, the process of fine-tuning these models on downstream tasks requires substantial computational resources, particularly when dealing with multiple speech-processing tasks. In this paper, we explore the potential of adapter-based fine-tuning in developing a unified model capable of effectively handling multiple spoken language processing tasks. The tasks we investigate are Automatic Speech Recognition, Phoneme Recognition, Intent Classification, Slot Filling, and Spoken Emotion Recognition. We validate our approach through a series of experiments on the SUPERB benchmark, and our results indicate that adapter-based fine-tuning enables a single encoder-decoder model to perform multiple speech processing tasks with an average improvement of 18.4% across the five target tasks while staying efficient in terms of parameter updates.
Read more6/24/2024
💬
0
Targeted Multilingual Adaptation for Low-resource Language Families
C. M. Downey, Terra Blevins, Dhwani Serai, Dwija Parikh, Shane Steinert-Threlkeld
The massively-multilingual training of multilingual models is known to limit their utility in any one language, and they perform particularly poorly on low-resource languages. However, there is evidence that low-resource languages can benefit from targeted multilinguality, where the model is trained on closely related languages. To test this approach more rigorously, we systematically study best practices for adapting a pre-trained model to a language family. Focusing on the Uralic family as a test case, we adapt XLM-R under various configurations to model 15 languages; we then evaluate the performance of each experimental setting on two downstream tasks and 11 evaluation languages. Our adapted models significantly outperform mono- and multilingual baselines. Furthermore, a regression analysis of hyperparameter effects reveals that adapted vocabulary size is relatively unimportant for low-resource languages, and that low-resource languages can be aggressively up-sampled during training at little detriment to performance in high-resource languages. These results introduce new best practices for performing language adaptation in a targeted setting.
Read more5/22/2024