How Do Humans Write Code? Large Models Do It the Same Way Too
2402.15729
1
0
Abstract
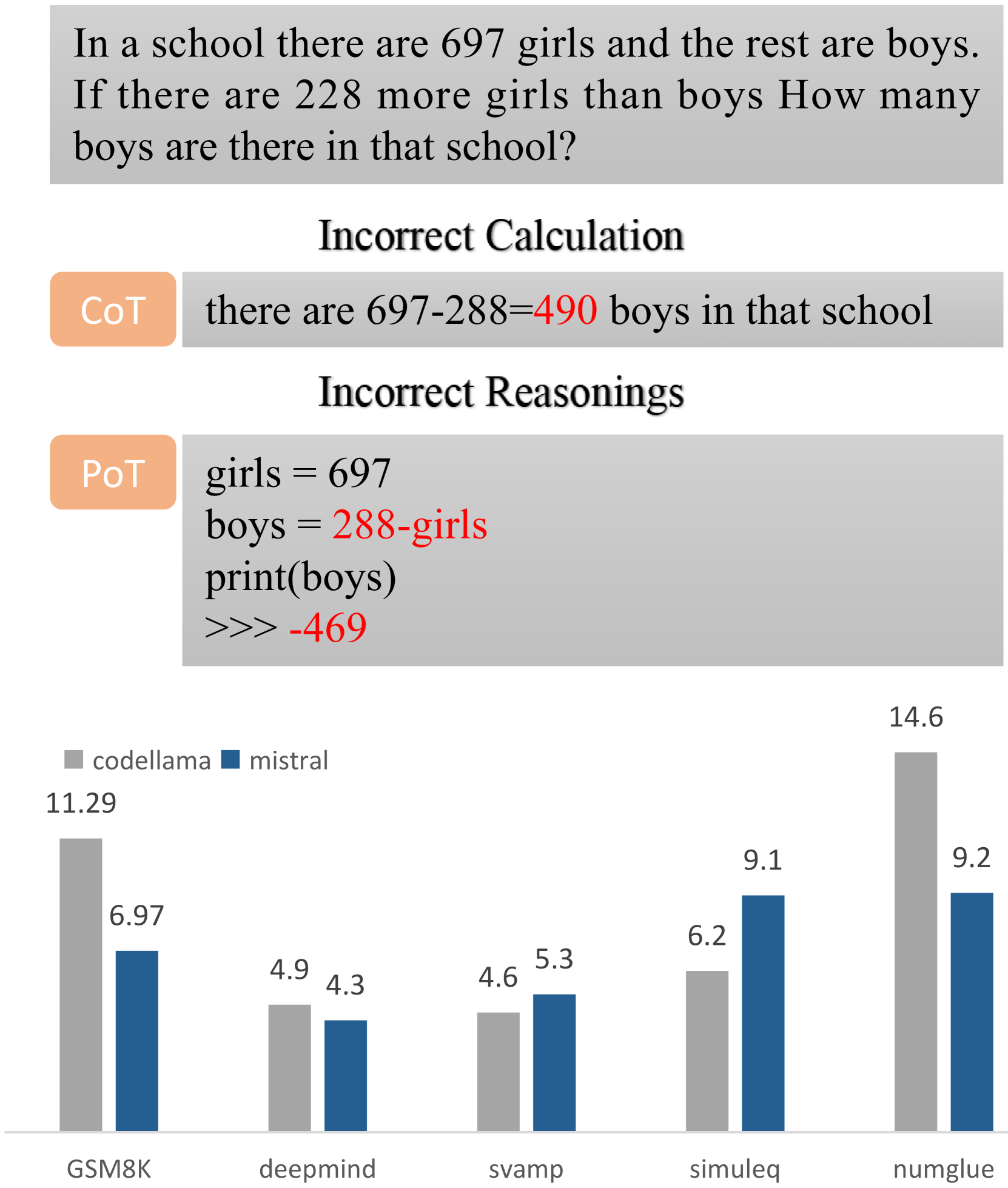
Program-of-Thought (PoT) replaces natural language-based Chain-of-Thought (CoT) as the most popular method in Large Language Models (LLMs) mathematical reasoning tasks by utilizing external tool calls to circumvent computational errors. However, our evaluation of the GPT-4 and Llama series reveals that using PoT introduces more reasoning errors, such as incorrect formulas or flawed logic, compared to CoT. To address this issue, we propose Human-Think Language (HTL), which leverages a suite of strategies that help integrate PoT and CoT, encompassing: (1) a new generation paradigm that uses full CoT reasoning to control code generation. (2) Focus Attention, that directs model attention to the CoT reasoning during PoT to generate more logical code. (3) reinforcement learning that utilizes the accuracy of both CoT and PoT responses as rewards to prevent repetitive reasoning steps in LLMs when solving difficult math problems. Our method achieves an average improvement of 6.5% on the Llama-Base model and 4.3% on the Mistral-Base model across 8 mathematical calculation datasets. It also shows significant effectiveness on five out-of-domain datasets by controlling the model's information flow, exhibiting strong transferability. Additionally, HTL shows the most significant improvement in non-mathematical natural language inference task, contributing to a unified reasoning task framework
Create account to get full access
Overview
- This paper examines how large language models (LLMs) write code in a similar way to how humans do.
- The researchers investigate the process of code generation by LLMs and compare it to human coding practices.
- Key findings include insights into the step-by-step mechanisms underlying LLM code generation and the potential for LLMs to learn and apply coding rules.
Plain English Explanation
The paper looks at how large AI language models, like GPT-3 or ChatGPT, write code compared to how humans do it. The researchers wanted to understand the step-by-step process these AI models use to generate code, and how it might be similar or different from how people write code.
The main finding is that LLMs actually go about coding in a quite similar way to humans. They break down the task into smaller steps, apply rules and patterns, and iterate on the code over time. This suggests these AI models are learning to "think" about coding in a human-like way, rather than just memorizing and regurgitating code.
The researchers also found evidence that LLMs can learn and apply general coding rules and principles, like how to think step-by-step mechanistically or how to learn rules. This is an important capability that could allow LLMs to reason about and generate code more robustly.
Overall, the study provides insights into the inner workings of how these powerful AI language models approach the complex task of coding, and suggests they may be developing human-like problem-solving abilities in this domain.
Technical Explanation
The researchers used a combination of techniques to investigate the code generation process of large language models (LLMs):
-
Instruction Construction: They generated prompts that asked LLMs to write code step-by-step, in order to observe the intermediate thought processes. This revealed the models breaking down the coding task into discrete sub-steps.
-
Attention Visualization: By visualizing the attention patterns of the LLMs as they generated code, the researchers could see how the models were focusing on different parts of the input and output over time, indicating an iterative, thoughtful approach.
-
Rule Learning Analysis: The paper also presents evidence that LLMs can learn general coding rules and principles, allowing them to reason about and apply coding concepts, rather than just memorizing.
Through these analyses, the researchers found striking similarities between how LLMs and humans approach the task of writing code. Both break down the problem, apply relevant rules and patterns, and refine the solution over multiple iterations. This suggests LLMs may be developing human-like step-by-step reasoning capabilities when it comes to coding.
Critical Analysis
The paper provides a compelling look into the inner workings of how large language models generate code. However, it is important to note that the research is limited to a set of specific coding tasks and prompts.
The authors acknowledge that more work is needed to understand the full scope of LLM coding capabilities, as well as their limitations. For example, the paper does not address whether LLMs can handle more complex, open-ended coding problems or maintain long-term reasoning about code.
Additionally, while the evidence for LLMs learning coding rules is promising, the paper does not explore the depth or robustness of this capability. It remains to be seen how well LLMs can generalize these rules to novel situations.
Overall, this research provides a valuable window into LLM code generation, but further investigation is needed to fully understand the strengths and limitations of these models when it comes to complex, real-world coding tasks.
Conclusion
This paper offers important insights into how large language models approach the task of writing code. By observing LLMs as they construct code step-by-step, the researchers found striking similarities to how humans code, suggesting these models are developing human-like problem-solving abilities in this domain.
The findings indicate that LLMs are not simply memorizing and regurgitating code, but are learning to apply general coding rules and principles. This has significant implications for the potential of these models to assist with and augment human coding workflows in the future.
While more research is needed to fully understand the scope and limitations of LLM coding capabilities, this paper represents an important step forward in illuminating the inner workings of these powerful AI systems when it comes to the complex task of generating code.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
How to think step-by-step: A mechanistic understanding of chain-of-thought reasoning
Subhabrata Dutta, Joykirat Singh, Soumen Chakrabarti, Tanmoy Chakraborty
0
0
Despite superior reasoning prowess demonstrated by Large Language Models (LLMs) with Chain-of-Thought (CoT) prompting, a lack of understanding prevails around the internal mechanisms of the models that facilitate CoT generation. This work investigates the neural sub-structures within LLMs that manifest CoT reasoning from a mechanistic point of view. From an analysis of Llama-2 7B applied to multistep reasoning over fictional ontologies, we demonstrate that LLMs deploy multiple parallel pathways of answer generation for step-by-step reasoning. These parallel pathways provide sequential answers from the input question context as well as the generated CoT. We observe a functional rift in the middle layers of the LLM. Token representations in the initial half remain strongly biased towards the pretraining prior, with the in-context prior taking over in the later half. This internal phase shift manifests in different functional components: attention heads that write the answer token appear in the later half, attention heads that move information along ontological relationships appear in the initial half, and so on. To the best of our knowledge, this is the first attempt towards mechanistic investigation of CoT reasoning in LLMs.
5/7/2024
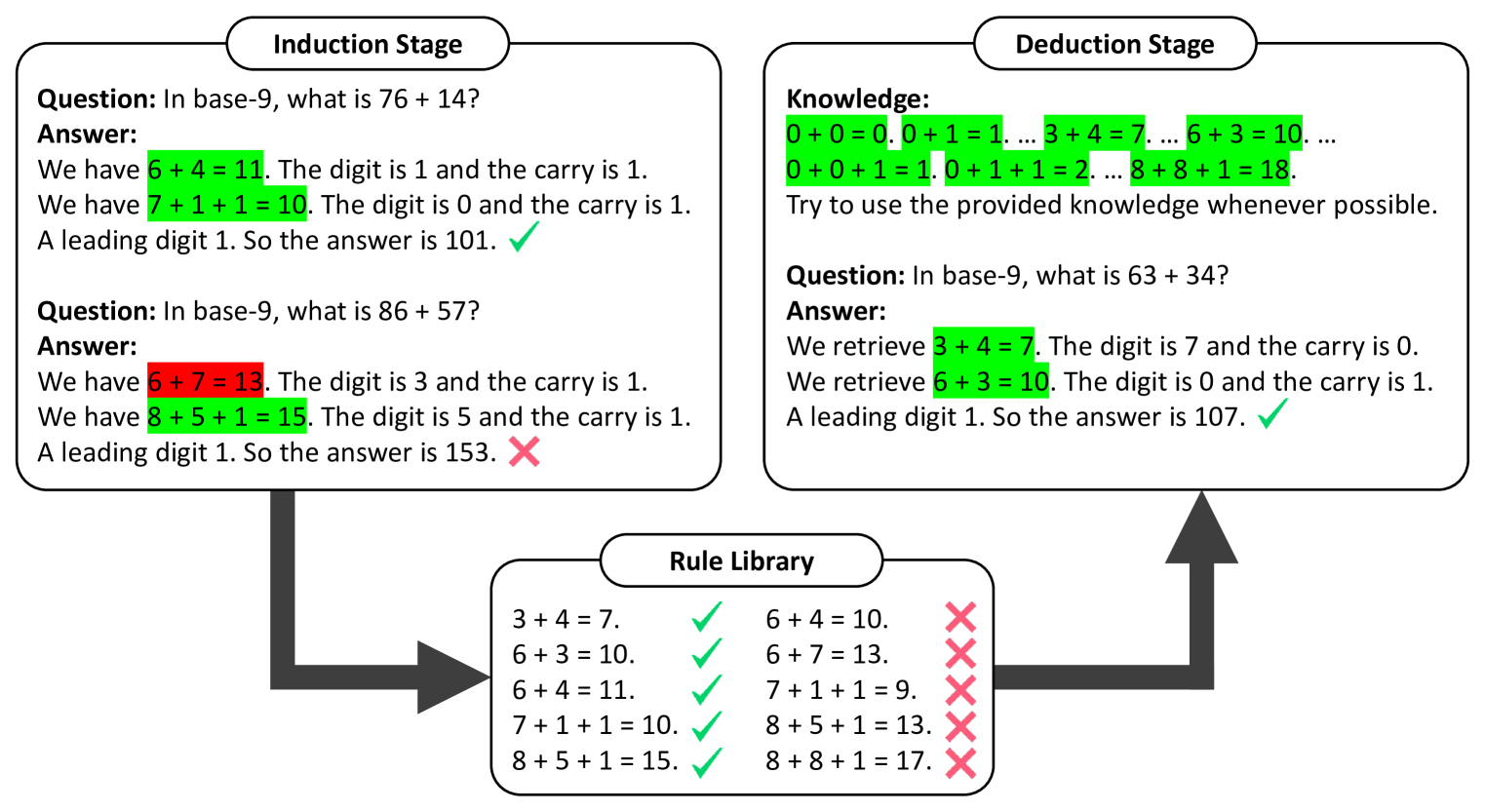
Large Language Models can Learn Rules
Zhaocheng Zhu, Yuan Xue, Xinyun Chen, Denny Zhou, Jian Tang, Dale Schuurmans, Hanjun Dai
0
0
When prompted with a few examples and intermediate steps, large language models (LLMs) have demonstrated impressive performance in various reasoning tasks. However, prompting methods that rely on implicit knowledge in an LLM often generate incorrect answers when the implicit knowledge is wrong or inconsistent with the task. To tackle this problem, we present Hypotheses-to-Theories (HtT), a framework that learns a rule library for reasoning with LLMs. HtT contains two stages, an induction stage and a deduction stage. In the induction stage, an LLM is first asked to generate and verify rules over a set of training examples. Rules that appear and lead to correct answers sufficiently often are collected to form a rule library. In the deduction stage, the LLM is then prompted to employ the learned rule library to perform reasoning to answer test questions. Experiments on relational reasoning, numerical reasoning and concept learning problems show that HtT improves existing prompting methods, with an absolute gain of 10-30% in accuracy. The learned rules are also transferable to different models and to different forms of the same problem.
4/26/2024
On the Empirical Complexity of Reasoning and Planning in LLMs
Liwei Kang, Zirui Zhao, David Hsu, Wee Sun Lee
0
0
Chain-of-thought (CoT), tree-of-thought (ToT), and related techniques work surprisingly well in practice for some complex reasoning tasks with Large Language Models (LLMs), but why? This work seeks the underlying reasons by conducting experimental case studies and linking the performance benefits to well-established sample and computational complexity principles in machine learning. We experimented with 6 reasoning tasks, ranging from grade school math, air travel planning, ..., to Blocksworld. The results suggest that (i) both CoT and ToT benefit significantly from task decomposition, which breaks a complex reasoning task into a sequence of steps with low sample complexity and explicitly outlines the reasoning structure, and (ii) for computationally hard reasoning tasks, the more sophisticated tree structure of ToT outperforms the linear structure of CoT. These findings provide useful guidelines for the use of LLM in solving reasoning tasks in practice.
6/19/2024
💬
Do Large Language Models Pay Similar Attention Like Human Programmers When Generating Code?
Bonan Kou, Shengmai Chen, Zhijie Wang, Lei Ma, Tianyi Zhang
0
0
Large Language Models (LLMs) have recently been widely used for code generation. Due to the complexity and opacity of LLMs, little is known about how these models generate code. We made the first attempt to bridge this knowledge gap by investigating whether LLMs attend to the same parts of a task description as human programmers during code generation. An analysis of six LLMs, including GPT-4, on two popular code generation benchmarks revealed a consistent misalignment between LLMs' and programmers' attention. We manually analyzed 211 incorrect code snippets and found five attention patterns that can be used to explain many code generation errors. Finally, a user study showed that model attention computed by a perturbation-based method is often favored by human programmers. Our findings highlight the need for human-aligned LLMs for better interpretability and programmer trust.
5/24/2024