Understanding Preference Fine-Tuning Through the Lens of Coverage

0

Sign in to get full access
Overview
- This paper explores the concept of "preference fine-tuning" in large language models (LLMs), which involves training models to express user preferences and values.
- The researchers analyze preference fine-tuning through the lens of "coverage," which refers to the model's ability to accurately represent the full range of user preferences.
- The paper provides insights into how LLMs can be effectively trained to capture diverse user preferences, which has important implications for developing AI systems that align with human values.
Plain English Explanation
The paper is about how we can train large language models (LLMs) to better understand and represent the preferences and values of users. This is an important challenge, as we want AI systems to behave in ways that align with human preferences.
The key idea is to look at this problem through the lens of "coverage" - how well the model can capture the full range of user preferences, rather than just focusing on optimizing for the average preference. The researchers argue that achieving good coverage is crucial for developing AI systems that can truly understand and respect the diversity of human values.
By analyzing preference fine-tuning techniques through this coverage-focused perspective, the paper provides insights into how LLMs can be more effectively trained to express user preferences. This could lead to the development of AI assistants that are more attuned to the unique needs and values of individual users, rather than just optimizing for the "average" user.
Overall, this research represents an important step towards creating AI systems that are better aligned with human preferences and values, which is a crucial challenge as these technologies become more prevalent in our lives.
Technical Explanation
The paper explores the concept of "preference fine-tuning," where large language models (LLMs) are trained to express user preferences and values. The researchers analyze this process through the lens of "coverage," which refers to the model's ability to accurately represent the full range of user preferences, rather than just optimizing for the average preference.
The authors argue that achieving good coverage is crucial for developing AI systems that can truly understand and respect the diversity of human values. To this end, they investigate various techniques for preference fine-tuning, such as link to "Generalized Preference Optimization: A Unified Approach to Offline Reinforcement Learning and Inverse Reinforcement Learning" and link to "Robust Preference Optimization through Reward Model Distillation", and analyze how these methods impact the coverage of the resulting preference models.
The paper also explores related concepts, such as link to "Direct Preference Optimization for Unobserved Preference Heterogeneity" and link to "Value-Incentivized Preference Optimization: A Unified Approach to Offline Reinforcement Learning and Inverse Reinforcement Learning", and discusses how they can be leveraged to improve the coverage of preference fine-tuned LLMs.
Through empirical analysis and theoretical insights, the paper provides a nuanced understanding of the challenges and opportunities in developing AI systems that can effectively capture and represent the diverse preferences and values of human users.
Critical Analysis
The paper provides a thoughtful and rigorous analysis of preference fine-tuning in LLMs, highlighting the importance of achieving good coverage to ensure that these systems truly align with human values. The authors' focus on coverage as a key metric is a valuable contribution, as it pushes the field to consider the diversity of preferences, rather than just optimizing for the "average" user.
That said, the paper does not delve into some potential limitations or caveats of this approach. For example, it does not discuss how to handle cases where user preferences are in conflict or how to resolve potential tensions between individual preferences and societal values. Additionally, the paper does not explore the challenges of evaluating coverage in real-world settings, where user preferences may be complex, context-dependent, and difficult to measure.
Further research could also investigate the tradeoffs between coverage and other important metrics, such as model performance, efficiency, and interpretability. It would be valuable to understand how different preference fine-tuning techniques impact these various factors and how to strike the right balance for different applications.
Overall, this paper represents an important contribution to the ongoing efforts to develop AI systems that are truly aligned with human values. By highlighting the importance of coverage, it encourages the research community to think more holistically about the challenges of preference modeling and to continue exploring innovative approaches to this critical problem.
Conclusion
This paper provides a valuable perspective on the challenge of preference fine-tuning in large language models (LLMs). By analyzing this process through the lens of "coverage" - the model's ability to accurately represent the full range of user preferences - the researchers offer insights into how LLMs can be more effectively trained to capture the diversity of human values.
The findings have important implications for the development of AI systems that are truly aligned with human preferences, as achieving good coverage is crucial for ensuring that these systems respect the unique needs and values of individual users, rather than just optimizing for the "average" user.
While the paper highlights some important considerations and directions for future research, it also leaves room for further exploration of the tradeoffs and challenges involved in preference modeling. As AI technologies continue to become more prevalent in our lives, this work represents an important step towards creating systems that can truly understand and respect the full breadth of human preferences and values.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Understanding Preference Fine-Tuning Through the Lens of Coverage
Yuda Song, Gokul Swamy, Aarti Singh, J. Andrew Bagnell, Wen Sun
Learning from human preference data has emerged as the dominant paradigm for fine-tuning large language models (LLMs). The two most common families of techniques -- online reinforcement learning (RL) such as Proximal Policy Optimization (PPO) and offline contrastive methods such as Direct Preference Optimization (DPO) -- were positioned as equivalent in prior work due to the fact that both have to start from the same offline preference dataset. To further expand our theoretical understanding of the similarities and differences between online and offline techniques for preference fine-tuning, we conduct a rigorous analysis through the lens of dataset coverage, a concept that captures how the training data covers the test distribution and is widely used in RL. We prove that a global coverage condition is both necessary and sufficient for offline contrastive methods to converge to the optimal policy, but a weaker partial coverage condition suffices for online RL methods. This separation provides one explanation of why online RL methods can perform better than offline methods, especially when the offline preference data is not diverse enough. Finally, motivated by our preceding theoretical observations, we derive a hybrid preference optimization (HyPO) algorithm that uses offline data for contrastive-based preference optimization and online data for KL regularization. Theoretically and empirically, we demonstrate that HyPO is more performant than its pure offline counterpart DPO, while still preserving its computation and memory efficiency.
Read more7/17/2024
0
Preference Fine-Tuning of LLMs Should Leverage Suboptimal, On-Policy Data
Fahim Tajwar, Anikait Singh, Archit Sharma, Rafael Rafailov, Jeff Schneider, Tengyang Xie, Stefano Ermon, Chelsea Finn, Aviral Kumar
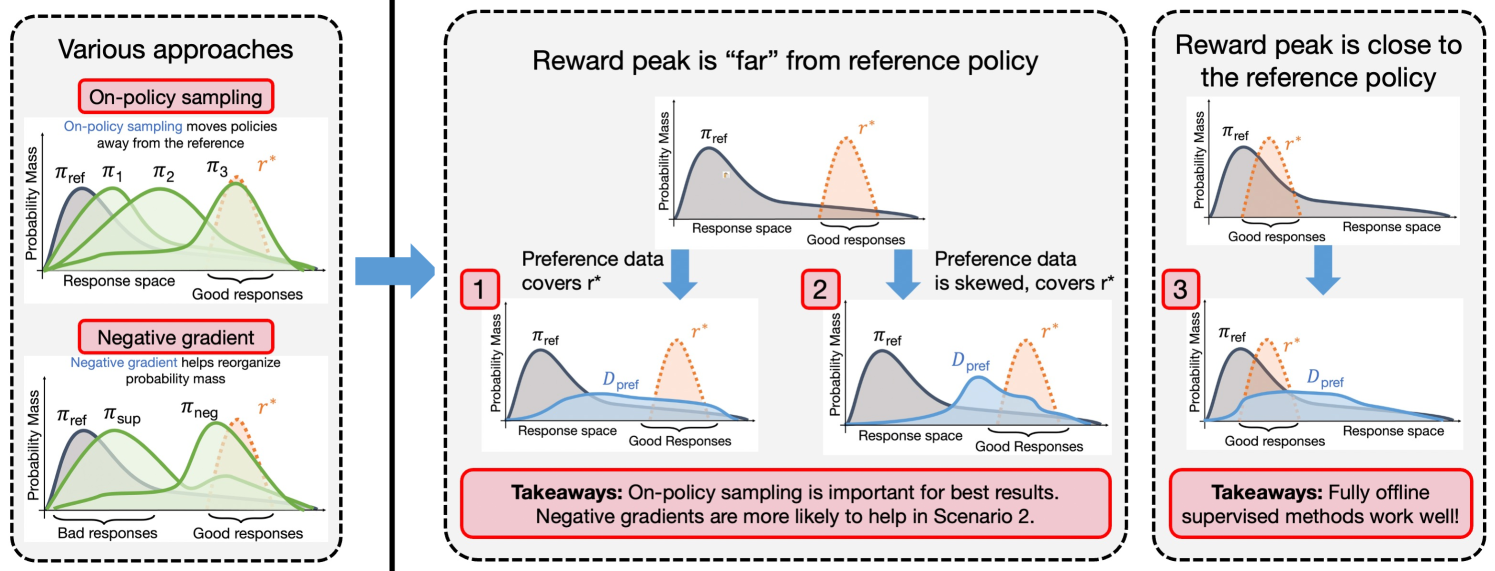
Learning from preference labels plays a crucial role in fine-tuning large language models. There are several distinct approaches for preference fine-tuning, including supervised learning, on-policy reinforcement learning (RL), and contrastive learning. Different methods come with different implementation tradeoffs and performance differences, and existing empirical findings present different conclusions, for instance, some results show that online RL is quite important to attain good fine-tuning results, while others find (offline) contrastive or even purely supervised methods sufficient. This raises a natural question: what kind of approaches are important for fine-tuning with preference data and why? In this paper, we answer this question by performing a rigorous analysis of a number of fine-tuning techniques on didactic and full-scale LLM problems. Our main finding is that, in general, approaches that use on-policy sampling or attempt to push down the likelihood on certain responses (i.e., employ a negative gradient) outperform offline and maximum likelihood objectives. We conceptualize our insights and unify methods that use on-policy sampling or negative gradient under a notion of mode-seeking objectives for categorical distributions. Mode-seeking objectives are able to alter probability mass on specific bins of a categorical distribution at a fast rate compared to maximum likelihood, allowing them to relocate masses across bins more effectively. Our analysis prescribes actionable insights for preference fine-tuning of LLMs and informs how data should be collected for maximal improvement.
Read more6/4/2024
0
OPTune: Efficient Online Preference Tuning
Lichang Chen, Jiuhai Chen, Chenxi Liu, John Kirchenbauer, Davit Soselia, Chen Zhu, Tom Goldstein, Tianyi Zhou, Heng Huang
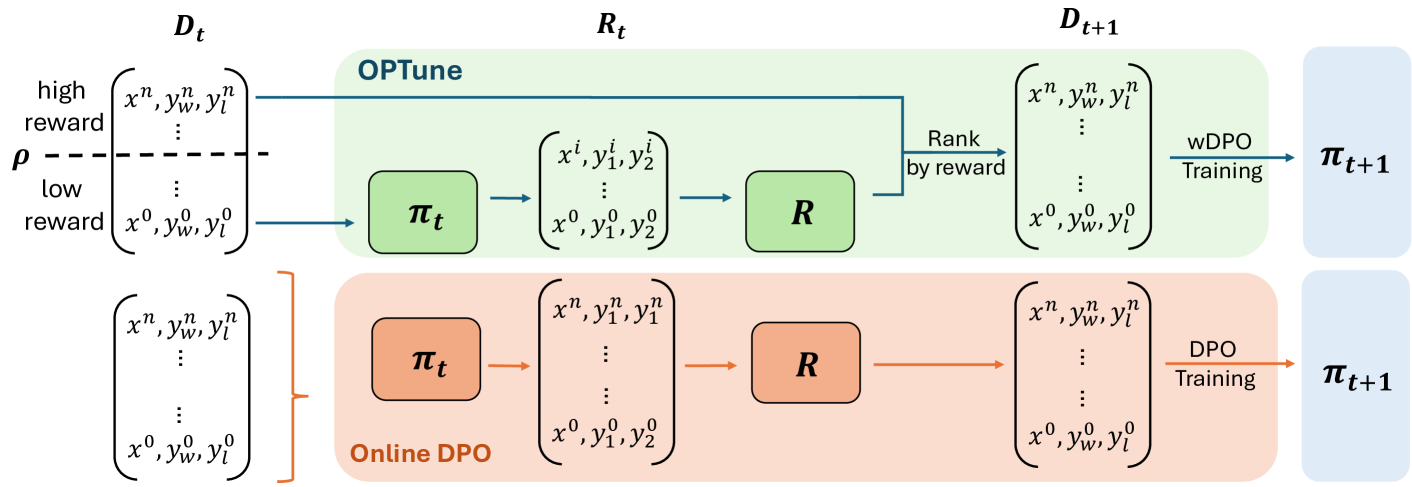
Reinforcement learning with human feedback~(RLHF) is critical for aligning Large Language Models (LLMs) with human preference. Compared to the widely studied offline version of RLHF, emph{e.g.} direct preference optimization (DPO), recent works have shown that the online variants achieve even better alignment. However, online alignment requires on-the-fly generation of new training data, which is costly, hard to parallelize, and suffers from varying quality and utility. In this paper, we propose a more efficient data exploration strategy for online preference tuning (OPTune), which does not rely on human-curated or pre-collected teacher responses but dynamically samples informative responses for on-policy preference alignment. During data generation, OPTune only selects prompts whose (re)generated responses can potentially provide more informative and higher-quality training signals than the existing responses. In the training objective, OPTune reweights each generated response (pair) by its utility in improving the alignment so that learning can be focused on the most helpful samples. Throughout our evaluations, OPTune'd LLMs maintain the instruction-following benefits provided by standard preference tuning whilst enjoying 1.27-1.56x faster training speed due to the efficient data exploration strategy.
Read more6/13/2024

0
New Desiderata for Direct Preference Optimization
Xiangkun Hu, Tong He, David Wipf
Large language models in the past have typically relied on some form of reinforcement learning with human feedback (RLHF) to better align model responses with human preferences. However, because of oft-observed instabilities when implementing these RLHF pipelines, various reparameterization techniques have recently been introduced to sidestep the need for separately learning an RL reward model. Instead, directly fine-tuning for human preferences is achieved via the minimization of a single closed-form training objective, a process originally referred to as direct preference optimization (DPO) and followed by several notable descendants. Although effective in certain real-world settings, we introduce new evaluation criteria that serve to highlight unresolved shortcomings in the ability of existing DPO methods to interpolate between a pre-trained reference model and empirical measures of human preferences, as well as unavoidable trade-offs in how low- and high-quality responses are regularized and constraints are handled. Our insights then motivate an alternative DPO-like loss that provably mitigates these limitations. Empirical results serve to corroborate notable aspects of our analyses.
Read more7/15/2024