Inferring Discussion Topics about Exploitation of Vulnerabilities from Underground Hacking Forums
2405.04561
0
0
Abstract
The increasing sophistication of cyber threats necessitates proactive measures to identify vulnerabilities and potential exploits. Underground hacking forums serve as breeding grounds for the exchange of hacking techniques and discussions related to exploitation. In this research, we propose an innovative approach using topic modeling to analyze and uncover key themes in vulnerabilities discussed within these forums. The objective of our study is to develop a machine learning-based model that can automatically detect and classify vulnerability-related discussions in underground hacking forums. By monitoring and analyzing the content of these forums, we aim to identify emerging vulnerabilities, exploit techniques, and potential threat actors. To achieve this, we collect a large-scale dataset consisting of posts and threads from multiple underground forums. We preprocess and clean the data to ensure accuracy and reliability. Leveraging topic modeling techniques, specifically Latent Dirichlet Allocation (LDA), we uncover latent topics and their associated keywords within the dataset. This enables us to identify recurring themes and prevalent discussions related to vulnerabilities, exploits, and potential targets.
Create account to get full access
Overview
- This paper explores how to infer discussion topics related to the exploitation of vulnerabilities from underground hacking forums.
- The researchers used Latent Dirichlet Allocation (LDA), a popular topic modeling technique, to analyze posts from these forums and identify the key topics being discussed.
- The goal was to gain insights into how hackers discuss and share information about vulnerabilities, which could inform cybersecurity efforts.
Plain English Explanation
This research paper looks at how hackers discuss and share information about security vulnerabilities on underground online forums. The researchers used a machine learning technique called Latent Dirichlet Allocation (LDA) to analyze the content of posts on these forums and uncover the main topics being discussed.
The idea is that by understanding how hackers talk about vulnerabilities, cybersecurity experts might be able to better defend against attacks. For example, if the researchers find that hackers frequently discuss a certain type of software vulnerability, that could help security teams focus their efforts on patching that vulnerability and monitoring for exploitation attempts.
The paper provides a window into the world of underground hacking communities, which is normally hard for outsiders to access. By studying the language and topics used in these forums, the researchers hope to gain insights that can improve overall cybersecurity.
Technical Explanation
The researchers used Latent Dirichlet Allocation (LDA), a popular topic modeling technique, to analyze a corpus of posts from underground hacking forums. LDA works by identifying latent, or hidden, topics within a set of text documents and then associating each document with the topics it discusses.
By applying LDA to the hacking forum posts, the researchers were able to uncover the key discussion topics related to the exploitation of vulnerabilities. This included topics like vulnerability disclosure, exploit code development, and the underground economy around vulnerabilities.
The researchers then analyzed the prevalence and evolution of these topics over time, as well as how they were discussed in different subforums. This provided insights into the priorities and strategies of the hacking community when it comes to vulnerabilities.
Critical Analysis
One limitation of the study is that it only analyzed public forums, which may not fully represent the discussions and activities happening in more private or invite-only hacking communities. The researchers acknowledge this and suggest that future work could try to access these more closed-off forums to get a more complete picture.
Additionally, while the topic modeling approach provides a high-level view of the discussions, it doesn't delve into the nuances and context of individual posts. A more qualitative, human-driven analysis could potentially uncover additional insights that were missed by the automated approach.
That said, the researchers' use of LDA for topic modeling is well-established and appropriate for this type of exploratory analysis. The findings offer a valuable starting point for further research into the underground hacking ecosystem and how it relates to vulnerability exploitation.
Conclusion
This study provides a novel approach to understanding the discussions and priorities of hackers when it comes to vulnerabilities and exploits. By applying topic modeling techniques to analyze posts from underground forums, the researchers were able to uncover insights that could inform cybersecurity efforts.
While the study has some limitations, it represents an important step in bridging the gap between the activities of the hacking community and the efforts of security professionals to defend against attacks. The findings could help security teams anticipate emerging threats and develop more effective countermeasures.
Overall, this research highlights the value of carefully studying the online activities and language of malicious actors in order to stay one step ahead in the ever-evolving world of cybersecurity.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
QuaLLM: An LLM-based Framework to Extract Quantitative Insights from Online Forums
Varun Nagaraj Rao, Eesha Agarwal, Samantha Dalal, Dan Calacci, Andr'es Monroy-Hern'andez
0
0
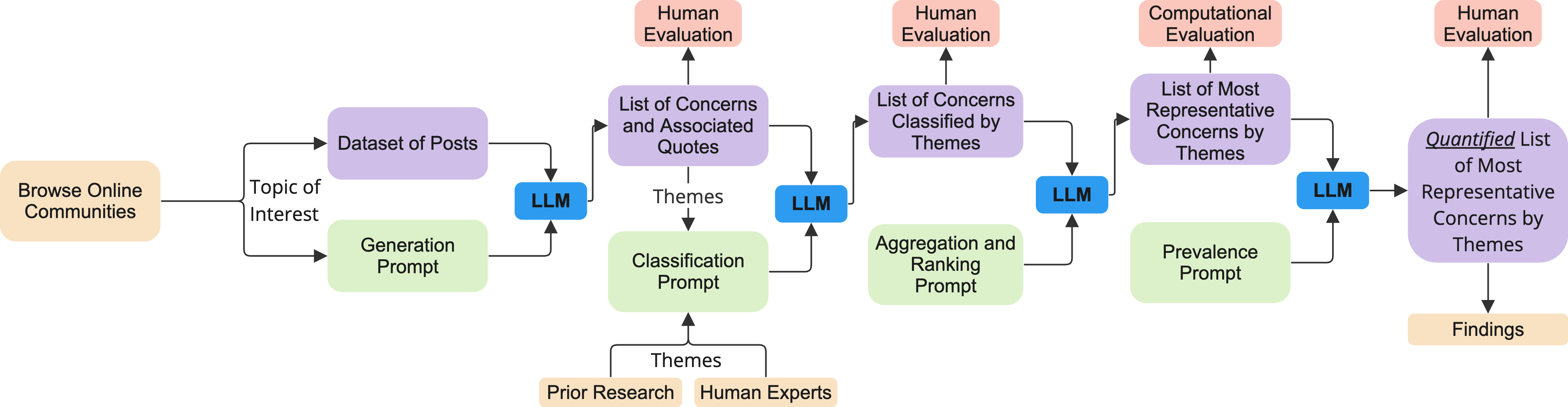
Online discussion forums provide crucial data to understand the concerns of a wide range of real-world communities. However, the typical qualitative and quantitative methods used to analyze those data, such as thematic analysis and topic modeling, are infeasible to scale or require significant human effort to translate outputs to human readable forms. This study introduces QuaLLM, a novel LLM-based framework to analyze and extract quantitative insights from text data on online forums. The framework consists of a novel prompting methodology and evaluation strategy. We applied this framework to analyze over one million comments from two Reddit's rideshare worker communities, marking the largest study of its type. We uncover significant worker concerns regarding AI and algorithmic platform decisions, responding to regulatory calls about worker insights. In short, our work sets a new precedent for AI-assisted quantitative data analysis to surface concerns from online forums.
5/10/2024
Threads of Subtlety: Detecting Machine-Generated Texts Through Discourse Motifs
Zae Myung Kim, Kwang Hee Lee, Preston Zhu, Vipul Raheja, Dongyeop Kang
0
0
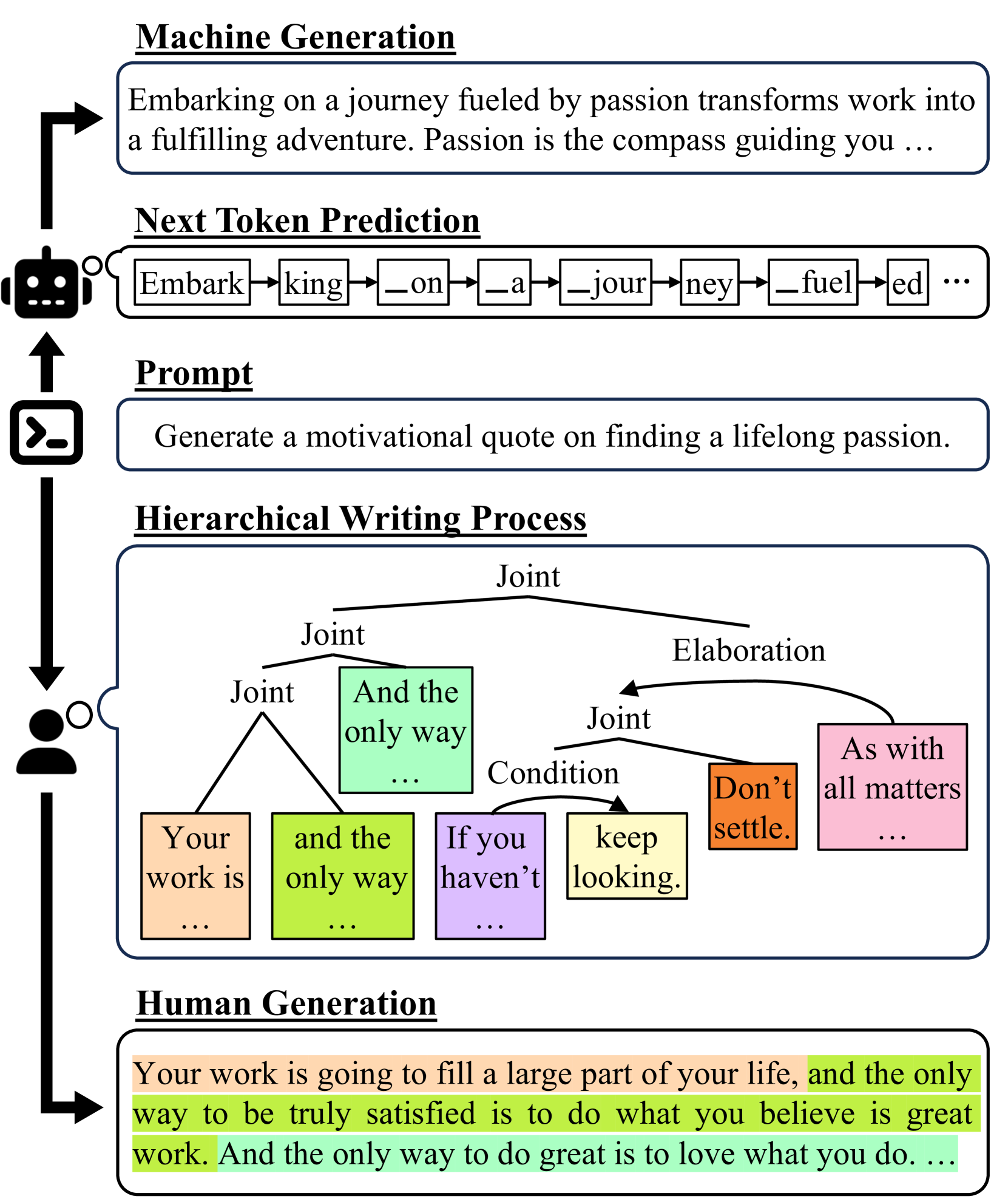
With the advent of large language models (LLM), the line between human-crafted and machine-generated texts has become increasingly blurred. This paper delves into the inquiry of identifying discernible and unique linguistic properties in texts that were written by humans, particularly uncovering the underlying discourse structures of texts beyond their surface structures. Introducing a novel methodology, we leverage hierarchical parse trees and recursive hypergraphs to unveil distinctive discourse patterns in texts produced by both LLMs and humans. Empirical findings demonstrate that, although both LLMs and humans generate distinct discourse patterns influenced by specific domains, human-written texts exhibit more structural variability, reflecting the nuanced nature of human writing in different domains. Notably, incorporating hierarchical discourse features enhances binary classifiers' overall performance in distinguishing between human-written and machine-generated texts, even on out-of-distribution and paraphrased samples. This underscores the significance of incorporating hierarchical discourse features in the analysis of text patterns. The code and dataset are available at https://github.com/minnesotanlp/threads-of-subtlety.
6/10/2024
💬
Harnessing Large Language Models for Software Vulnerability Detection: A Comprehensive Benchmarking Study
Karl Tamberg, Hayretdin Bahsi
0
0
Despite various approaches being employed to detect vulnerabilities, the number of reported vulnerabilities shows an upward trend over the years. This suggests the problems are not caught before the code is released, which could be caused by many factors, like lack of awareness, limited efficacy of the existing vulnerability detection tools or the tools not being user-friendly. To help combat some issues with traditional vulnerability detection tools, we propose using large language models (LLMs) to assist in finding vulnerabilities in source code. LLMs have shown a remarkable ability to understand and generate code, underlining their potential in code-related tasks. The aim is to test multiple state-of-the-art LLMs and identify the best prompting strategies, allowing extraction of the best value from the LLMs. We provide an overview of the strengths and weaknesses of the LLM-based approach and compare the results to those of traditional static analysis tools. We find that LLMs can pinpoint many more issues than traditional static analysis tools, outperforming traditional tools in terms of recall and F1 scores. The results should benefit software developers and security analysts responsible for ensuring that the code is free of vulnerabilities.
5/27/2024
Exploring Vulnerabilities and Protections in Large Language Models: A Survey
Frank Weizhen Liu, Chenhui Hu
0
0
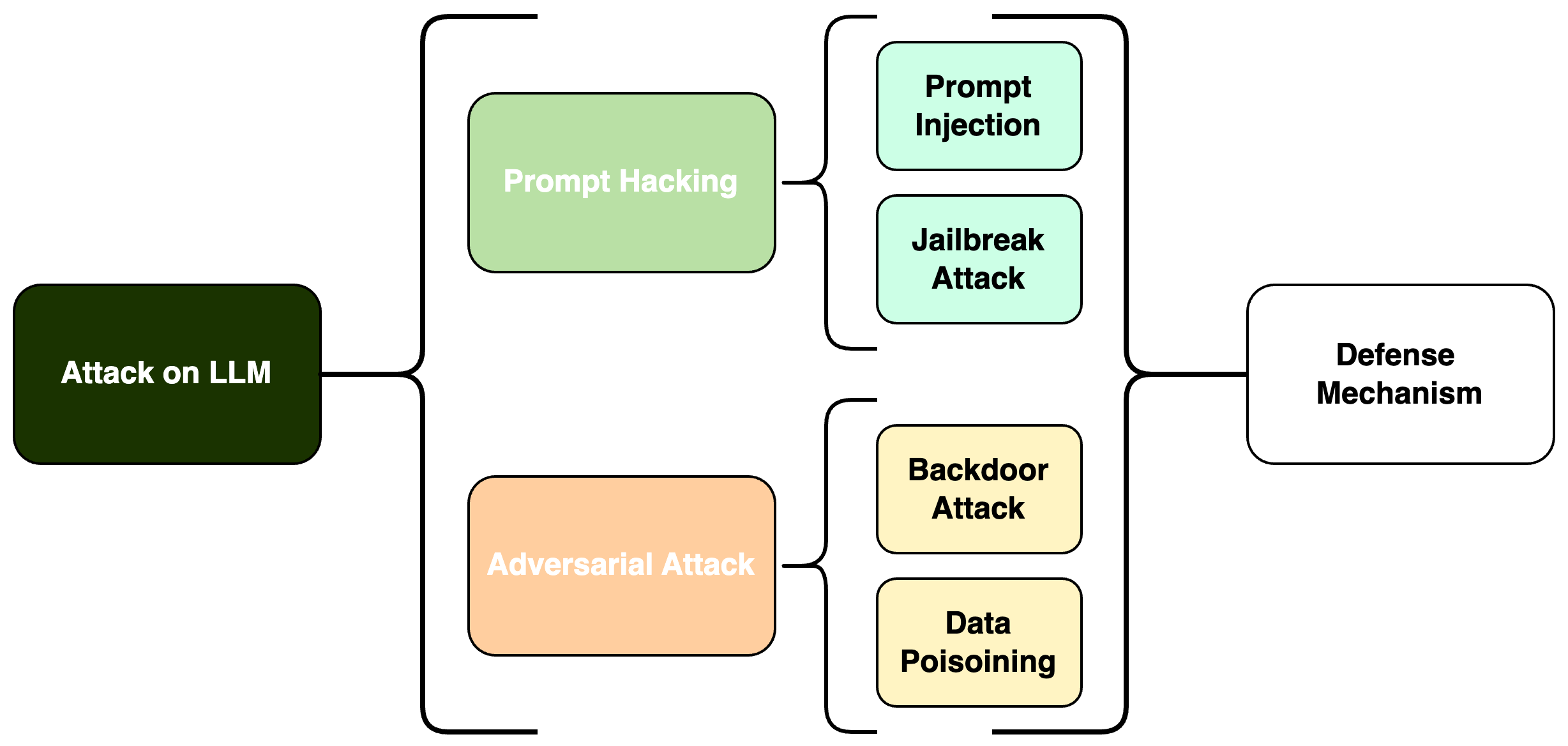
As Large Language Models (LLMs) increasingly become key components in various AI applications, understanding their security vulnerabilities and the effectiveness of defense mechanisms is crucial. This survey examines the security challenges of LLMs, focusing on two main areas: Prompt Hacking and Adversarial Attacks, each with specific types of threats. Under Prompt Hacking, we explore Prompt Injection and Jailbreaking Attacks, discussing how they work, their potential impacts, and ways to mitigate them. Similarly, we analyze Adversarial Attacks, breaking them down into Data Poisoning Attacks and Backdoor Attacks. This structured examination helps us understand the relationships between these vulnerabilities and the defense strategies that can be implemented. The survey highlights these security challenges and discusses robust defensive frameworks to protect LLMs against these threats. By detailing these security issues, the survey contributes to the broader discussion on creating resilient AI systems that can resist sophisticated attacks.
6/4/2024