Influencer Backdoor Attack on Semantic Segmentation

0
🛸
Sign in to get full access
Overview
- Deep neural networks can exhibit malicious behavior during inferences if a small number of poisoned samples are injected into the training dataset
- This poses potential threats to real-world applications, especially in the domain of semantic segmentation
- Semantic segmentation aims to classify every pixel within a given image, unlike traditional classification tasks
- The research paper explores a backdoor attack called the Influencer Backdoor Attack (IBA) that can mislead the classifications of all victim pixels in every single inference
Plain English Explanation
In the world of artificial intelligence and machine learning, deep neural networks are powerful tools that can be trained to perform a wide range of tasks, from image recognition to language processing. However, these models can be vulnerable to a type of attack known as a backdoor attack.
A backdoor attack occurs when a small number of "poisoned" samples are intentionally introduced into the training dataset of a deep neural network. These poisoned samples can then cause the trained model to exhibit malicious behavior during the inference stage, where the model makes predictions on new, real-world data.
While backdoor attacks have been extensively studied in the context of classification tasks, the research paper focuses on a less explored area: semantic segmentation. Unlike traditional classification, where an image is assigned a single label, semantic segmentation aims to classify every single pixel within an image. This added complexity makes semantic segmentation models potentially more vulnerable to backdoor attacks.
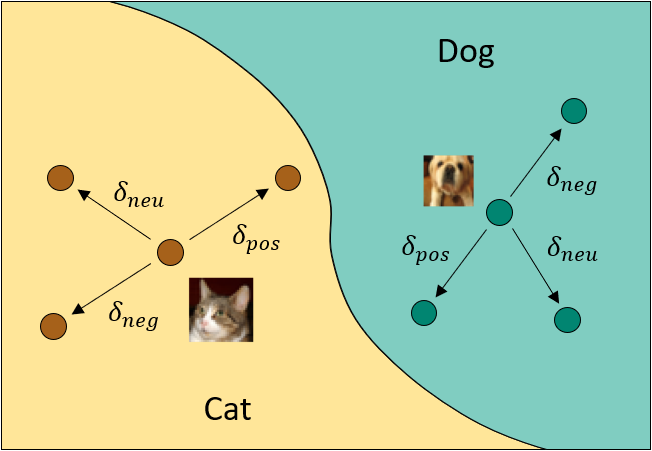
The researchers propose a specific type of backdoor attack called the Influencer Backdoor Attack (IBA). The goal of IBA is to cause the segmentation model to misclassify all pixels of a "victim" class by injecting a specific trigger on non-victim pixels during the inference stage. This attack is designed to maintain the accuracy of the model on non-victim pixels while completely misleading the classifications of all victim pixels.
The researchers developed a simple yet effective strategy for injecting the trigger, called the Nearest-Neighbor trigger injection strategy, which leverages the context aggregation ability of segmentation models. They also introduced an innovative Pixel Random Labeling strategy that helps maintain optimal performance even when the trigger is placed far from the victim pixels.
Technical Explanation
The researchers explored the vulnerability of semantic segmentation models to backdoor attacks. Unlike classification tasks, where a single label is assigned to an entire image, semantic segmentation aims to classify every individual pixel within an image.
The proposed Influencer Backdoor Attack (IBA) is designed to mislead the classifications of all victim pixels in every single inference by injecting a specific trigger on non-victim pixels. This is achieved by leveraging the context aggregation ability of segmentation models, which allows the models to consider the relationships between different regions of the image when making predictions.
The researchers developed two key techniques to enhance the IBA approach:
-
Nearest-Neighbor trigger injection strategy: This strategy leverages the context aggregation ability of segmentation models to effectively inject the trigger into the non-victim pixels.
-
Pixel Random Labeling strategy: This innovative technique maintains optimal performance even when the trigger is placed far from the victim pixels, by randomly labeling the pixels during training.
The researchers conducted extensive experiments to evaluate the effectiveness of the IBA approach and the proposed techniques. Their results demonstrate that current segmentation models are indeed vulnerable to backdoor attacks and that the IBA approach, combined with the Nearest-Neighbor trigger injection and Pixel Random Labeling strategies, can significantly increase the attack performance.
Critical Analysis
The research paper presents a compelling exploration of backdoor attacks on semantic segmentation models, an area that has been largely overlooked in previous studies. The authors' proposed Influencer Backdoor Attack (IBA) and the accompanying techniques, such as the Nearest-Neighbor trigger injection and Pixel Random Labeling strategies, offer valuable insights into the vulnerabilities of these models.
However, the paper does not address several important considerations. For instance, it does not discuss the potential real-world implications of such backdoor attacks or the ethical implications of intentionally introducing vulnerabilities into AI systems. Additionally, the paper does not explore potential countermeasures or defense mechanisms that could be developed to mitigate such attacks.
Furthermore, while the researchers demonstrate the effectiveness of their IBA approach, the paper lacks a thorough discussion of the limitations and potential drawbacks of the proposed techniques. It would be beneficial to understand the specific scenarios or conditions under which the IBA approach may be less effective or encounter challenges.
Readers are encouraged to think critically about the research and form their own opinions. It is important to consider the broader context and implications of such findings, as well as the need for continued research and development of robust and secure AI systems that can withstand malicious attacks.
Conclusion
The research paper explores a critical vulnerability in semantic segmentation models: the potential for backdoor attacks that can mislead the classification of all victim pixels in every single inference. The proposed Influencer Backdoor Attack (IBA) and the accompanying techniques, such as the Nearest-Neighbor trigger injection and Pixel Random Labeling strategies, demonstrate the feasibility and effectiveness of such attacks.
The findings in this paper highlight the importance of continued research and development in the area of AI security and robustness. As deep neural networks become increasingly prevalent in real-world applications, it is crucial to address these vulnerabilities and develop effective countermeasures to ensure the reliability and trustworthiness of these systems. Further research into the underlying mechanisms of backdoor attacks, as well as the exploration of novel defense strategies, will be crucial in safeguarding the deployment of AI systems in sensitive domains.
Overall, this paper serves as a valuable contribution to the ongoing efforts to understand and mitigate adversarial attacks on deep learning models, particularly in the context of semantic segmentation, and paves the way for future advancements in the field of AI security.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
Influencer Backdoor Attack on Semantic Segmentation
Haoheng Lan, Jindong Gu, Philip Torr, Hengshuang Zhao
When a small number of poisoned samples are injected into the training dataset of a deep neural network, the network can be induced to exhibit malicious behavior during inferences, which poses potential threats to real-world applications. While they have been intensively studied in classification, backdoor attacks on semantic segmentation have been largely overlooked. Unlike classification, semantic segmentation aims to classify every pixel within a given image. In this work, we explore backdoor attacks on segmentation models to misclassify all pixels of a victim class by injecting a specific trigger on non-victim pixels during inferences, which is dubbed Influencer Backdoor Attack (IBA). IBA is expected to maintain the classification accuracy of non-victim pixels and mislead classifications of all victim pixels in every single inference and could be easily applied to real-world scenes. Based on the context aggregation ability of segmentation models, we proposed a simple, yet effective, Nearest-Neighbor trigger injection strategy. We also introduce an innovative Pixel Random Labeling strategy which maintains optimal performance even when the trigger is placed far from the victim pixels. Our extensive experiments reveal that current segmentation models do suffer from backdoor attacks, demonstrate IBA real-world applicability, and show that our proposed techniques can further increase attack performance.
Read more4/10/2024

0
An Invisible Backdoor Attack Based On Semantic Feature
Yangming Chen
Backdoor attacks have severely threatened deep neural network (DNN) models in the past several years. These attacks can occur in almost every stage of the deep learning pipeline. Although the attacked model behaves normally on benign samples, it makes wrong predictions for samples containing triggers. However, most existing attacks use visible patterns (e.g., a patch or image transformations) as triggers, which are vulnerable to human inspection. In this paper, we propose a novel backdoor attack, making imperceptible changes. Concretely, our attack first utilizes the pre-trained victim model to extract low-level and high-level semantic features from clean images and generates trigger pattern associated with high-level features based on channel attention. Then, the encoder model generates poisoned images based on the trigger and extracted low-level semantic features without causing noticeable feature loss. We evaluate our attack on three prominent image classification DNN across three standard datasets. The results demonstrate that our attack achieves high attack success rates while maintaining robustness against backdoor defenses. Furthermore, we conduct extensive image similarity experiments to emphasize the stealthiness of our attack strategy.
Read more5/21/2024
🖼️
0
Backdoor Attack with Sparse and Invisible Trigger
Yinghua Gao, Yiming Li, Xueluan Gong, Zhifeng Li, Shu-Tao Xia, Qian Wang
Deep neural networks (DNNs) are vulnerable to backdoor attacks, where the adversary manipulates a small portion of training data such that the victim model predicts normally on the benign samples but classifies the triggered samples as the target class. The backdoor attack is an emerging yet threatening training-phase threat, leading to serious risks in DNN-based applications. In this paper, we revisit the trigger patterns of existing backdoor attacks. We reveal that they are either visible or not sparse and therefore are not stealthy enough. More importantly, it is not feasible to simply combine existing methods to design an effective sparse and invisible backdoor attack. To address this problem, we formulate the trigger generation as a bi-level optimization problem with sparsity and invisibility constraints and propose an effective method to solve it. The proposed method is dubbed sparse and invisible backdoor attack (SIBA). We conduct extensive experiments on benchmark datasets under different settings, which verify the effectiveness of our attack and its resistance to existing backdoor defenses. The codes for reproducing main experiments are available at url{https://github.com/YinghuaGao/SIBA}.
Read more6/7/2024
0
Poisoning-based Backdoor Attacks for Arbitrary Target Label with Positive Triggers
Binxiao Huang, Jason Chun Lok, Chang Liu, Ngai Wong
Poisoning-based backdoor attacks expose vulnerabilities in the data preparation stage of deep neural network (DNN) training. The DNNs trained on the poisoned dataset will be embedded with a backdoor, making them behave well on clean data while outputting malicious predictions whenever a trigger is applied. To exploit the abundant information contained in the input data to output label mapping, our scheme utilizes the network trained from the clean dataset as a trigger generator to produce poisons that significantly raise the success rate of backdoor attacks versus conventional approaches. Specifically, we provide a new categorization of triggers inspired by the adversarial technique and develop a multi-label and multi-payload Poisoning-based backdoor attack with Positive Triggers (PPT), which effectively moves the input closer to the target label on benign classifiers. After the classifier is trained on the poisoned dataset, we can generate an input-label-aware trigger to make the infected classifier predict any given input to any target label with a high possibility. Under both dirty- and clean-label settings, we show empirically that the proposed attack achieves a high attack success rate without sacrificing accuracy across various datasets, including SVHN, CIFAR10, GTSRB, and Tiny ImageNet. Furthermore, the PPT attack can elude a variety of classical backdoor defenses, proving its effectiveness.
Read more5/10/2024